







论文笔记 | DCS-RISR: Dynamic Channel Splitting for Efficient Real-world Image Super-Resolution
太久没更新了,因为最近读的文章都比较经典,大佬的分析文都写得很精彩,觉得自己没必要画蛇添足地复制一篇到自己的博客。
DCS是最近刚在Arxiv看到的文章,v1的提交时间是12.15,因为还没看到代码,也没在网上看到相关参考分析,就由我来抛砖引玉下~
如有理解不到位之处,欢迎留言讨论。

用于超分的动态通道拆分方法。
作者来自华东师范大学、苏黎世联邦理工、华为。
目录
1 Motivation
- 传统SR方法假设从HR图像到LR图像的退化是双三次下采样,由于退化类型不匹配导致了用于真实世界图片的超分,性能不理想。
- 最近的RISR方法倾向于探索复杂组合的退化过程,但计算成本和内存消耗较大。
- 文章提出了一种方法,期望能在解决复杂退化的过程中保持性能并控制计算成本。
2 Contribution
- 动态通道拆分DCS方法,自适应地调整特征的高频和低频比例,改善模型冗余。
- LOC模块(可学习的八度卷积模块),添加到现有SR模型中。
- 非局部正则化方法,增加patch之间的信息交互。
3 Method
3.1 OctConv八度卷积
- 19年facebook提出的,对传统的卷积进行改进,来降低空间冗余。
- 名字起的很有意思,Drop an Octave是说降低一个八度,这里借鉴了音乐高低音的说法(刚好差一个八度),指代高低频的特征。
首先,我们看高频信号和低频信号的概念,或说图像中的高频分量和低频分量,一般高频信号指的是图像强度变化剧烈的像素点,比如边缘,轮廓,细节和噪声;低频信号指的是图像强度变换平缓的像素点,比如大片面积色块的部分。也就是说高频信号度量图像的细节,低频信号度量图像的整体,所以论文指出:较高的频率通常用精细的细节编码,而较低的频率使用全局结构编码即可。
根据上面的观点,八度卷积的作者认为,特征图也是图像,也可以进行高频和低频的区分,所以可以设置一个频率阈值,对特征进行频率计算,高于/低于这个阈值的区分为高频/低频特征图。
联想到与之有点相似的Best-buddy GAN。
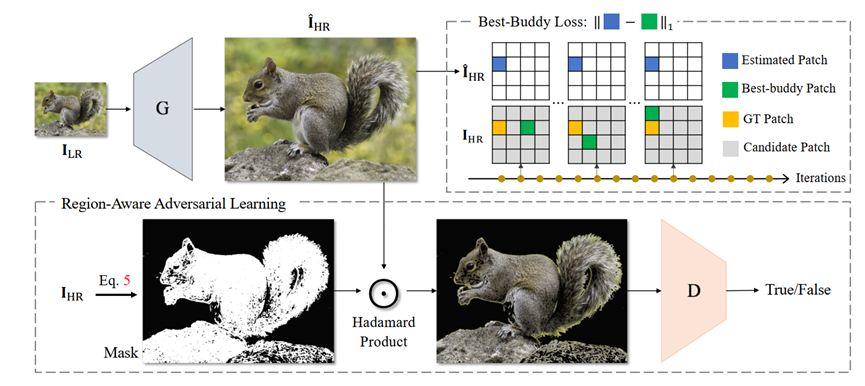
Best Buddy GAN:计算一个mask,用于区分纹理丰富的部分。计算一个patch之内的标准差,大于某个值的,就认为是一个patch之内的变化比较丰富,说明纹理丰富,就特殊处理。
详情可以参考本人几个月前的笔记:
链接: 论文笔记 |【AAAI2022】Best-Buddy GANs for Highly Detailed Image Super-Resolution
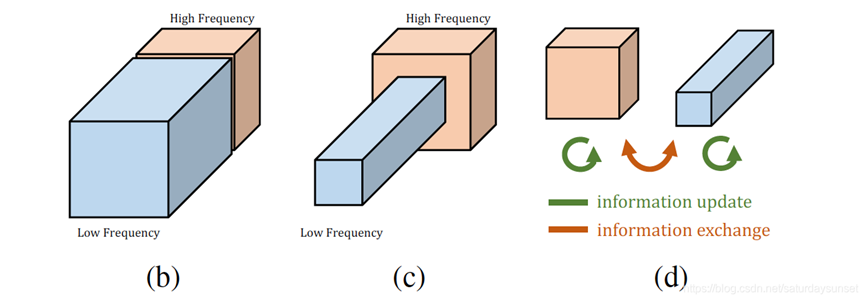
回到图像处理中,其实我们会更需要高频特征,因为包含了轮廓这种边缘信息,而低频特征图包含的信息相对少。如果用相同的处理方法处理两部分特征图,其实对低频特征图来说,有点浪费资源,所以作者提出把特征图按照频率分成2部分的做法成为Octave feature representation,其中有一个α参数,代表低频特征图占总特征图的比例,相对的高频特征图所占比例就是1-α。α∈[0,1]。
所以看到上面这张图,针对低频特征图,也就是对处理过程来说有些冗余的特征图,作者把分辨率降低为原来的1/2。因为高分辨率图好比近距离观察,低分辨率图好比远距离观察,作者认为降低低频特征图的分辨率,不仅有助于减少冗余数据,也有利于得到全局信息。(卷积核不变,总体图像的尺寸变小了,感受野相对变大了一倍,更加有利于观察全局信息)
但是普通卷积无法解决2组特征图,所以作者对卷积核进行了拆分,拆成4部分。
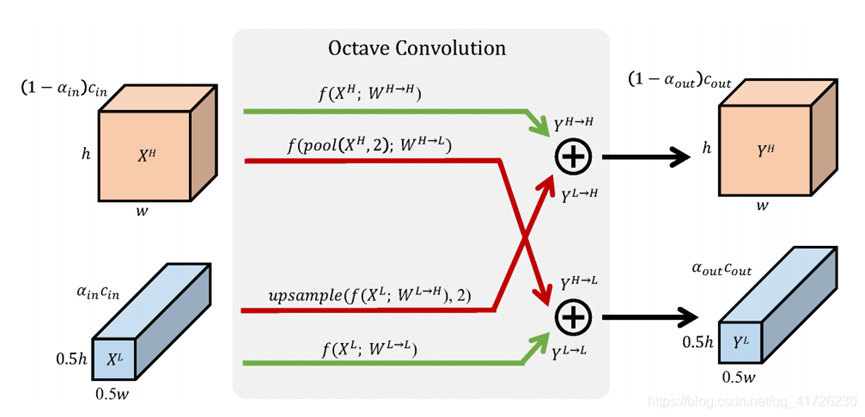
高低频的特征一方面自己和自己进行同一频率内的更新,绿色箭头;另一方面,不同频率之间也有交流,红色的箭头。这里假设卷积过后尺寸不变,那么不同频率之间的交流前,需要用池化/上采样进行分辨率的调整,最后经过元素点加,得到高频/低频的输出特征图。
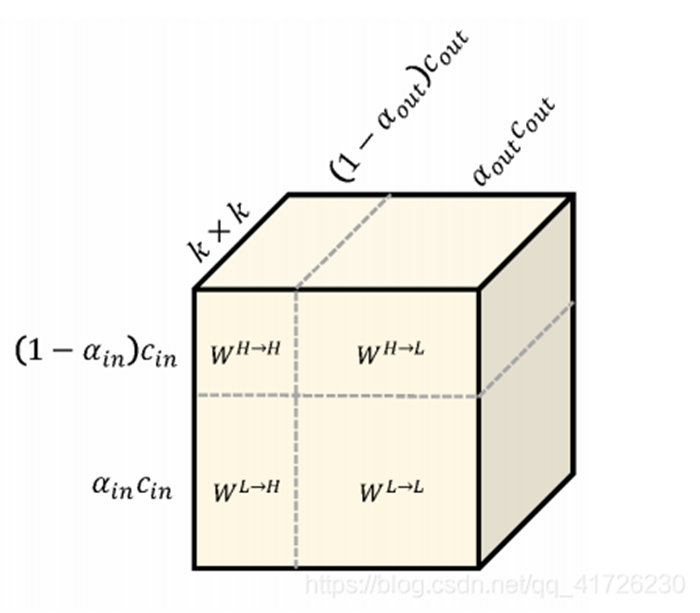
最后看一下卷积核的尺寸。
假设α是低频特征图占比,1-α就是高频占比。
我们知道卷积核的尺寸一般是kkCinCout,这里为了方便看,把kk拉直了。
对于WHH,它的输入输出,代表了卷积核的尺寸,比较难理解的是WLH和WHL。
最后这个八度卷积它设计成了一个即插即用的模块,也就是说它可以直接去替代一个卷积层,达到降低计算复杂度的目的。
但是这里它并没有说α要如何来确定,能得到一个相对好的效果,并且因为图像内容各异,势必会影响到α的取值,所以对于图像超分而言,如果固定了一个α,效果必然是不好的,所以本文把α变成了一个可学习的量。
3.2 Overview
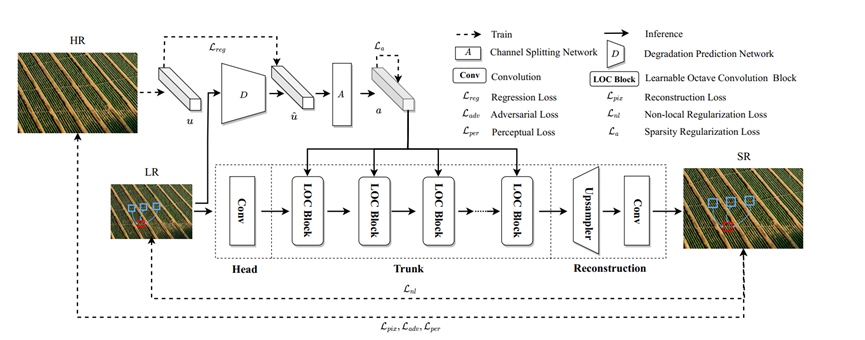
流程图。实线表示实际推理过程,虚线表示训练过程。
大致过程是,对于一张高分图片,它先进行一些退化处理,得到HR-LR图像对,以及描述退化处理过程的参数向量u。因为之前的工作大多数是默认双三次下采样,但效果不好,因此它采用了多级退化策略,就是用多种退化操作对这张HR图片进行处理,并且使用one-hot向量来记录退化操作的种类和参数,这些参数记录在向量u中,维度d=33。
接着,我们把LR图像放进退化预测网络D,生成一个退化向量u-head,用来描述LR的退化类型。也就是D网络是可学习的网络,目的是学出LR图像可能经过了怎样的退化处理过程,所以这里对u和u-head做了一个loss,实现对D的训练。
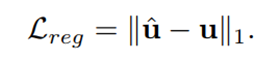
D是一个轻量级网络,通道数是64×33×33,三层卷积+Leady Relu+池化+FC层。
然后通过通道拆分网络A,学习一个通道拆分向量a,这个向量是一维的,a∈Rs,其中s是LOC模块的数量。a向量的每一个分量ai,是给第i个LOC模块作为输入的,它代表的是我们刚才在介绍八度卷积中的α,刚才的α指的是低频特征图占总特征图的比例,不过这里ai代表的是高频占总的比例。因为a需要针对不同的图像内容进行变化,所以是可学习的,因此加了一个loss。
如果a太大,接近1了,说明把全部特征都当成高频进行精细化处理了,那么LOC模块就会退化成普通的resnet block(这就是这里为什么要用a代表高频而非低频,为了构造loss),所以添加的loss只要限制a不要太接近1就可以。
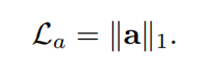
A是2个FC层+一个sigmoid激活层,参数量很小,相当于一个MLP。
把a和LR图像作为输入,传进网络的主干部分。
下面来看网络的主干部分。其实网络的改动不大,我们知道SR网络一般是:头部进行特征提取,中间进行一些特征的处理,最后上采样,或者说图像重建。它头卷积和尾部的上采样模块都维持原样,baseline使用的是SRResnet,但它把中间的Resnet模块都替换成了自己的LOC模块(可学习的八度卷积模块)。
替换思路很简单,把正常的卷积,替换成八度卷积。
因为八度卷积需要额外传入一个ratio,也就是α的参数,所以上面用A网络的输出a,传进每个LOC模块。可以看到,和我们刚才的那个图是一样的,多了一步残差相加而已。
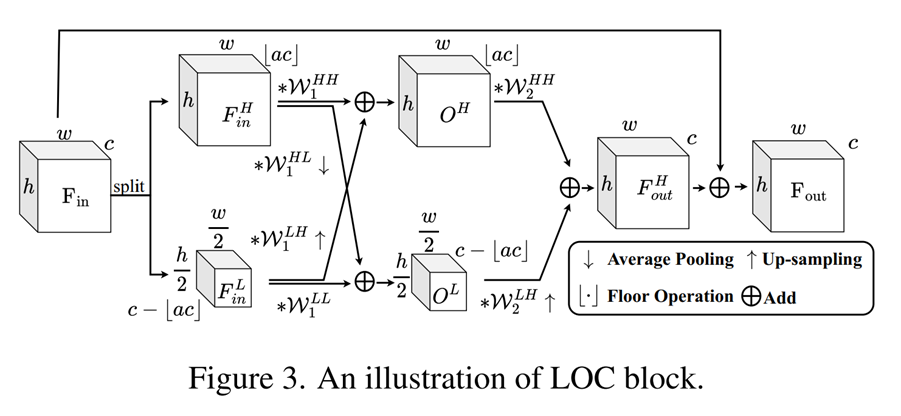
这样,重建出的SR图像,就可以和HR图像计算loss。
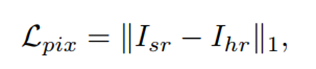
一个是像素级别的损失函数,其实就是SR和GT之间的L1-loss,另外是感知损失和对抗损失。
3.3 Non-local Regularization
我们经常看到类似于local/non-local,查了一下,其实这个词开始好像是针对感受野来说的,同一个卷积核作用的位置就属于local,如果做一些感受野之间的交互,就可以称作是non-local,如果交互扩散到了全局,比如全连接层,那不仅是non-local,而且可以称作是global。
文章提出的这个非局部正则化,我感觉比较抽象。用一个loss来约束LR和生成的SR图像。
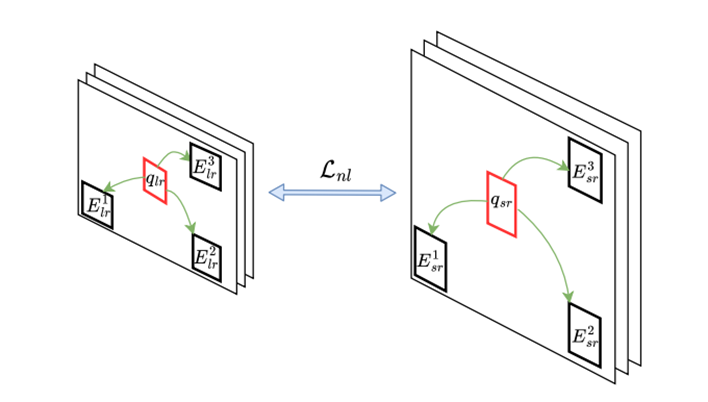
对于LR图像中的每一个patch,以qlr为例,我们计算其他patch和它的相似度,这里用的是欧氏距离,然后按相似度从高到低排序,取前K个,比如这里K=3,取前三个。然后在SR图像中,按照对应位置关系找到对应的K个Esr,按照下面这个公式计算loss:
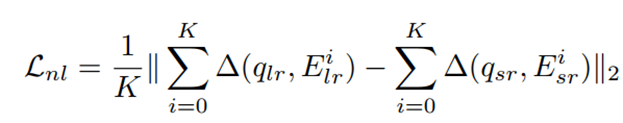
三角形Δ符号是对两个patch的欧氏距离取绝对值的意思。也就是对于LR图像中每一块相似patch,取它和query的patch的欧氏距离绝对值相加,SR图像做同样操作,两者求差,最后取二范数再平均。我能理解到的是,去做一些像素位置上的约束,或者说图片的内容和位置上,去添加一个约束。
总体的损失是下面这个式子。
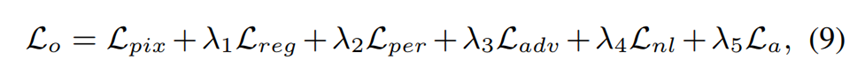
训练分为两阶段,第一阶段是固定a=0.5,先训练SR的backbone网络,只最小化pixel损失。之后再同时重新训练D、A和SR网络,最小化总体损失。
4 Experiment
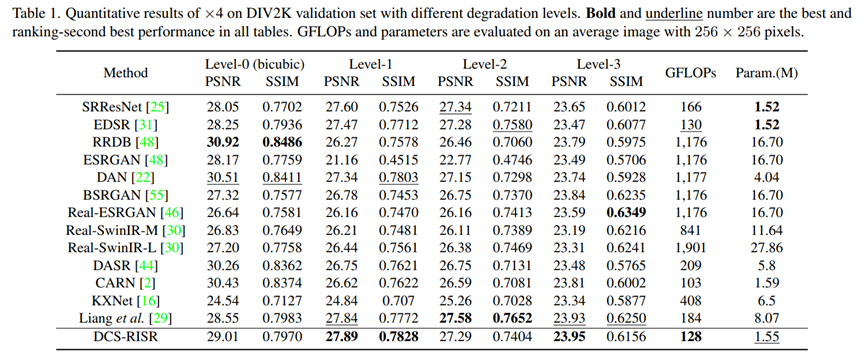
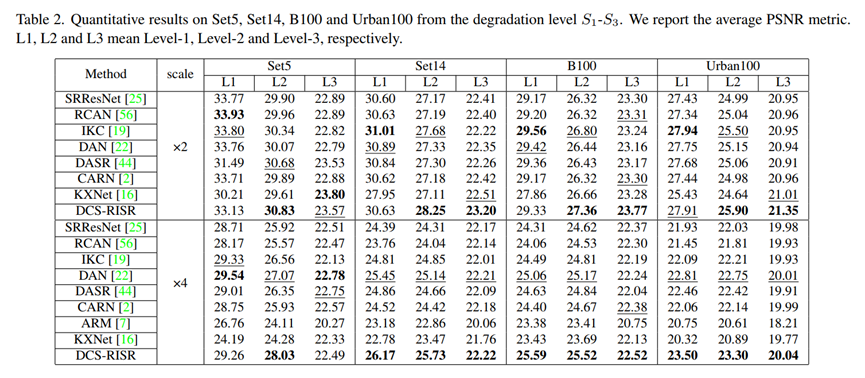
5 Ablation study
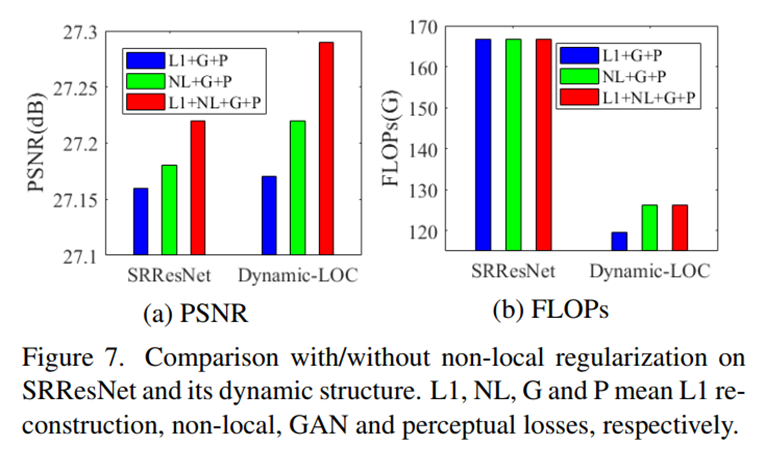
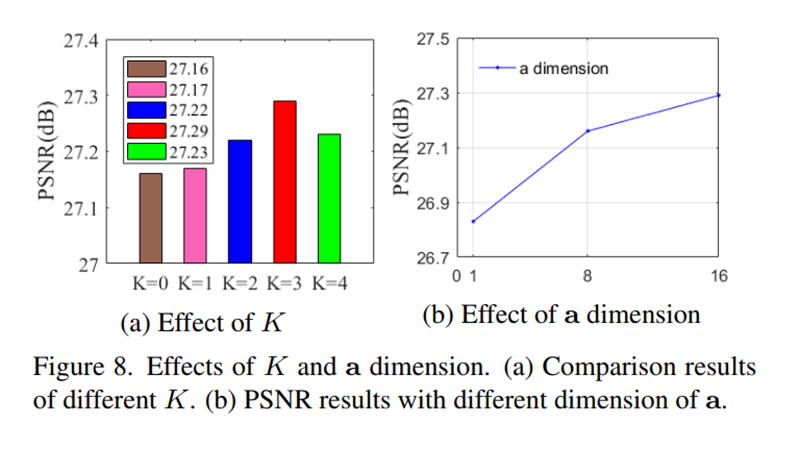
LOC Block+Non-local regularization+K的数量+a的维度















 1932
1932











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









