







论文笔记 | 【ECCV2022】Restore Globally, Refine Locally: A Mask-Guided Scheme to Accelerate Super-Resolution Networks
作者单位南开大学+悉尼大学,还有阿联酋的起源人工智能研究院。
目录
1 Motivation
SR网络有压缩空间:
(1)超分图像分辨率趋于变大(4K)
(2)同一张图片不同patch,需要的恢复程度不同。复杂处需要更精细的超分重建。

如PAN网络(ECCV2020Workshop,中科大董超团队,一个含有pixel attention的超分网络,包含16个SCPA模块)。
让图片通过PAN网络,过12个SCPA模块后得到coarse SR(图2);过全部模块得到final SR(图3),计算两个SR图片在亮度通道的差值,得到一张error map(图4)。
可以看到纹理边缘的error是比较大的,可视化为图5后也可以看出,大部分LR区域通过12个block已经可以恢复的很好了,剩下的4个block其实主要是用来提升边缘区域的,更深层次的复原。
这个现象给SR网络提供了改进空间。
2 Contribution
- 1)提出Mask-Guided Acceleration (MGA)方法来加速SR networks,减少Flops(浮点数计算)次数和运行时间,同时保持性能。
方法包含Base-Net(粗SR)和Refine-Net(精细调整部分patch)。 - 2)MGA方法包含一个Mask Prediction 模块(MP Module),用于选择图片中需要进一步精细化调整的patch。
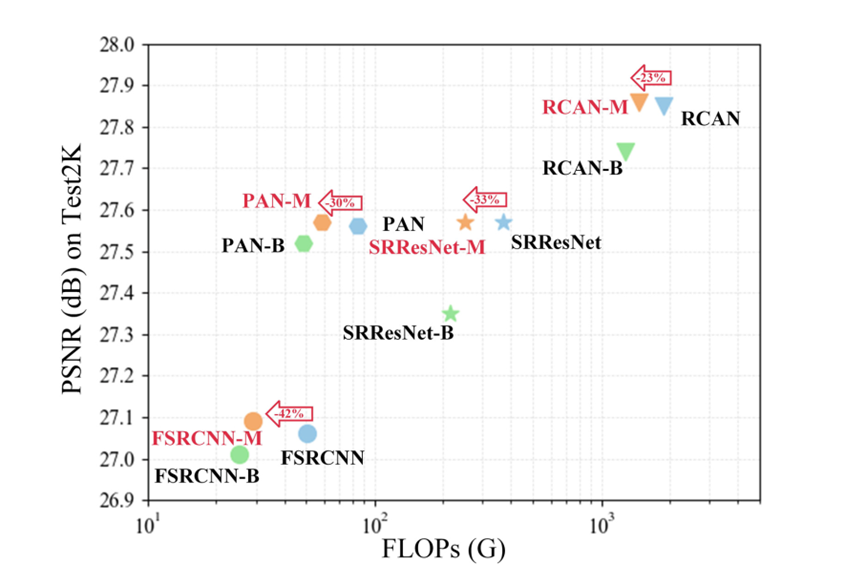
-B:Base-Net 使用部分block的原网络,Flops降了,但性能也降了;
-M:using MGA,Flops降了,性能保持甚至升高。
3 Method
3.1 MGA method
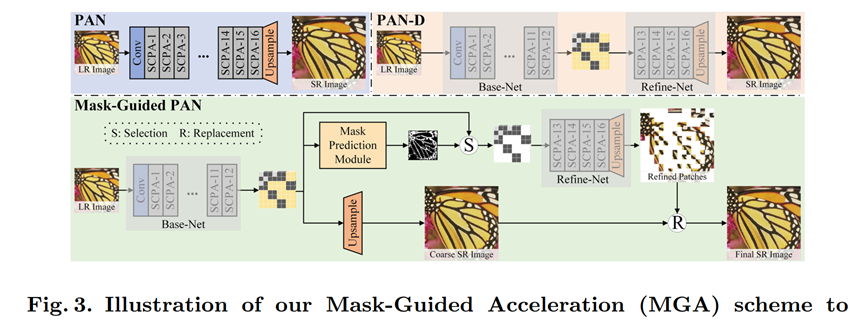
左上角是PAN网络结构,可以看到,Conv后是12层SCPA block,最后通过一个pixel-shuffle 的上采样层,得到超分图像。
右上角PAN-D图,实际上是一个中间产物,图画得不准确,先跳过;
下方是MGA加速的PAN方法。
整体方法思路:(推理阶段)
LR图像,经过12个block的Base-Net进行特征提取后,分为2个分支。
其中一个,直接用得到的粗提取特征,做上采样,得到Coarse SR图像;
另一个分支,通过一个小型轻量的网络MP Module,预测出一个mask。Mask指示粗粒度提取的特征,有哪些patch是涉及到比较多的边缘信息,需要进一步refine调整的。Mask计算出来以后,在粗粒度特征中提取出这些patch(因为最后出来的是一个softmax后的结果,所以挑选分数最高的K个),送入Refine-Net进行精细特征进一步提取,再上采样,得到SR的patch。
此时两个分支汇合,通过Refine-Net的这些经过调整后的patch,替换掉原本Coarse SR图像的这一部分patch,得到最终的Final SR结果。
注意,Base-Net和Refine-Net的上采样器是不共享的。
分开训练的。
3.2 MP Module

粗提取的特征,通过卷积核全局池化层GAP,得到尺寸是H/pW/p2的中间结果Fs。Fs有2个通道,每一个通道的每一个元素,代表一个p*p的patch,的C个通道的特征。
然后通过softmax函数,只使用第二个通道的结果,通过一个动态卷积,得到最后的mask。Mask指代的是需要进一步调整的,比较复杂的patch。
一些细节需要说明:
1)代码没全给,只给了model的类定义和forward函数。稍有不同,先过softmax才过的全局池化,最后还过了一个LeakyReLU,但总体没变;
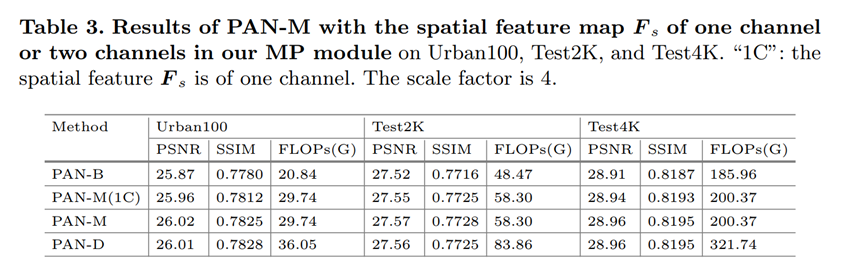
2)Ms2?为什么要用2个channel。论文的解释是,第一个channel学的是Well-SR patches的概率,第二个channel反映的是the possibilities of being Under-SR patches,所以用第二个channel。我倾向于是实验表明第二个channel性能更好,所以临时找的理由,并不算很有说服力。
那如果只学一个channel呢?消融实验做了学一个channel,和学2个用第二个的,发现学2个的性能更好。
3)D-Conv:正常卷积,卷积核可学习,但是对于D-Conv,另外拿一个卷积层来学习卷积核。
即,拿一个卷积层,输入是Ms2,输出是卷积核,再用这个卷积核在Ms2上面做卷积。(Meta-SR其实是典型的动态卷积,使用一个小型网络动态学习“卷积核”的参数,此时其实重点已经不是卷积核了,它只是个权重,重点在小型网络)。
3.3 Training Strategy
端到端训练,效果不好。因为12个Block提取的特征质量较低而且容易改变,使得MP模块训练不稳定。
因此使用3步训练网络:
1)用L1loss,用全部训练数据,训练不含MP模块的全部网络D-Net.
D-Net:decomposed net = PAN(拆分)+Upsampler = Base-Net(含Upsampler)+ Refine-Net(含Upsampler)
2)用通过12个block(通过Base-Net)后的特征patch训练Refine-Net,做进一步的精细调整,即A-Net(All-Net)。与D-Net含等量的参数;
3)固定B-Net和R-Net为All-Net的参数,只训练MP-Module。
对mask也增加一个loss作为监督,使用第一步骤里的coarse SR与final SR的差(即error map),与mask做监督。
(实际操作应该要对error map做全局池化处理才能对上维度吧,但是没有代码,只能这样猜测了)
4 Experiment
4.1 result on baseline
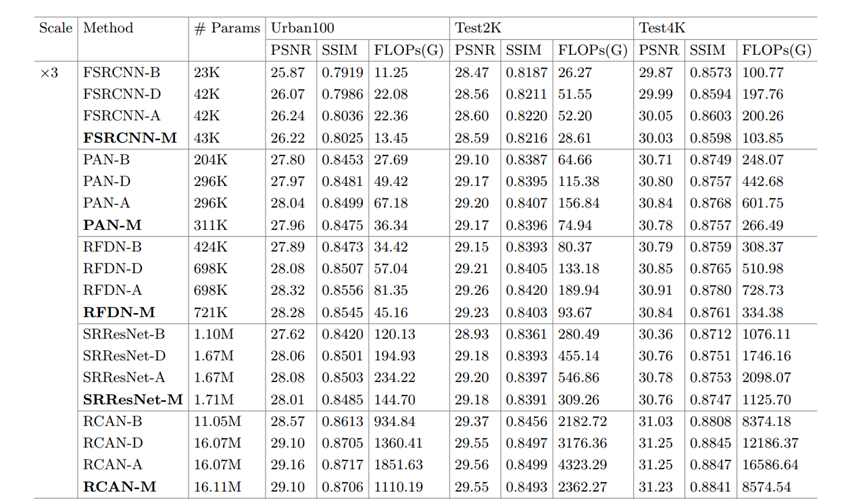
-B:通过12个block的;
-D:通过12+4+upsampler的
-A:通过12+4+upsampler,且对后4个进行了refine的;
-M:MGA加速的网络。
-A性能应该最好,因为它把所有的patch都通过了后4个,但和-M比没有好很多,而且-M的flops明显下降,参数量增加也不多。
4.2 compared with ClassSR
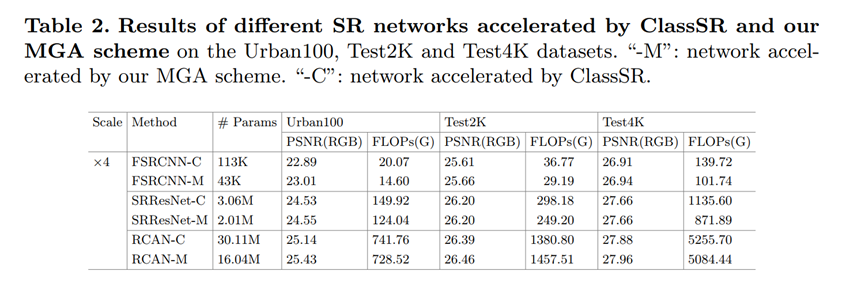
用来拉踩的(bushi
参数量和flops都更少,性能更佳。
5 Ablation study
5.1 Mask 可视化
表明mask确实聚焦于多边缘区域了。

5.2 Fs的channel为1还是为2
5.3 训练策略对性能的影响

E2E的方法不稳定;
Without S 是说,是否对mask添加一个监督(error map),实验表明添加监督效果更好;
5.4 PAN网络的模块如何划分到B和F网络
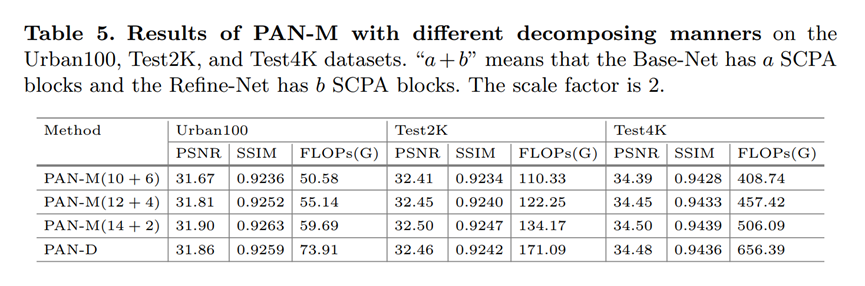
显然是,Base-Net占比越大性能越好,但同时计算量也上去了,两者要寻求一个平衡,故12+4,中庸之道。
5.5 patch的大小

4*4最好,于是就用了它。
5.6 K选多少比较好
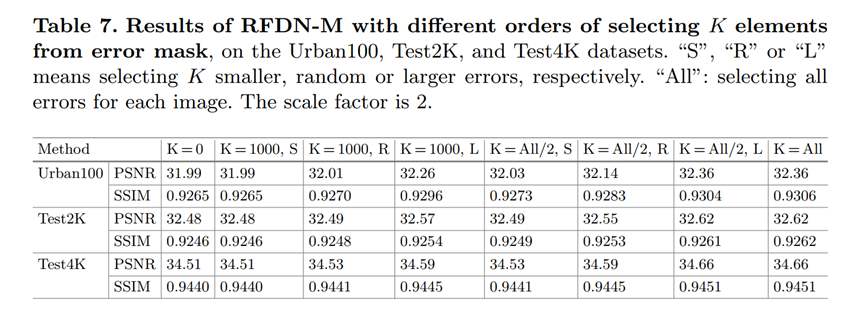
肯定是越多越好,但同样需要一个权衡。
S,R,L是指选分数最小的,随机选,选分数最大的K个。那肯定是从大开始选最好了。
从最后两列也可以看到的是,c选K的个数到达all/2即全局一半的时候,性能影响已经不大了。侧面印证,需要调整的patch数量其实是不多的,最起码少于全局的一半了。















 845
845











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









