







 本文介绍了Uformer,一种结合U-Net和Transformer结构的图像恢复模型。Uformer通过LeWinTransformer块降低了Transformer的计算复杂度,同时利用多尺度恢复调制器增强细节恢复。实验表明,该模型在图像去模糊和去噪等任务中表现出色,提升了图像修复的质量,并达到SOTA水平。
本文介绍了Uformer,一种结合U-Net和Transformer结构的图像恢复模型。Uformer通过LeWinTransformer块降低了Transformer的计算复杂度,同时利用多尺度恢复调制器增强细节恢复。实验表明,该模型在图像去模糊和去噪等任务中表现出色,提升了图像修复的质量,并达到SOTA水平。
论文笔记 |【CVPR2021】Uformer: A General U-Shaped Transformer for Image Restoration

文章目录
1 Motivation
- CNN无法捕捉长距离的像素依赖
- Transformer计算复杂度高达二次方、获取局部依赖关系受限
解决方法: 提出Uformer
- 参考了U-Net和transformer的结构
- 将U-Net中的卷积层用transformer代替
- 编码器-解码器结构和skip-connection保持不变。
核心设计:
- LeWin Transformer块:
非重叠窗口的自注意力—降低计算复杂度+捕获更多全局依赖关系
前向传播的网络,两个全连接层之间引入深度卷积层—更好捕获局部上下文 - 可学习、多尺度、恢复调制器:处理图像退化,恢复更多细节。可以灵活用于不同框架下的不同图像恢复任务(general)

贡献: Uformer+恢复调制器提升修复质量+sota

2 Method
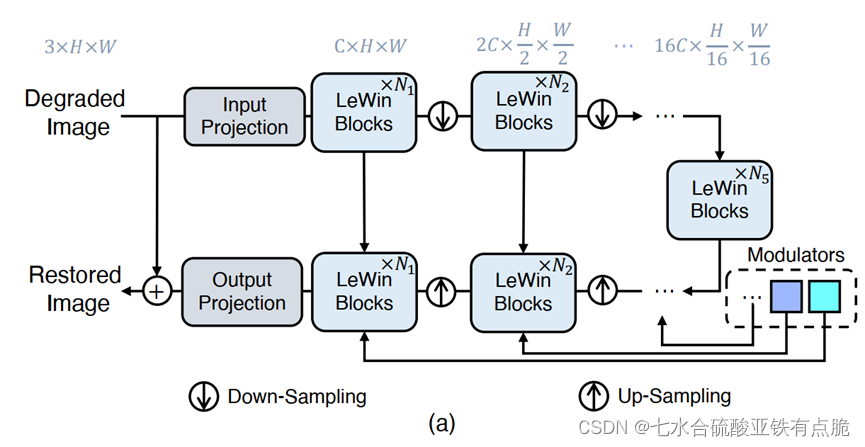
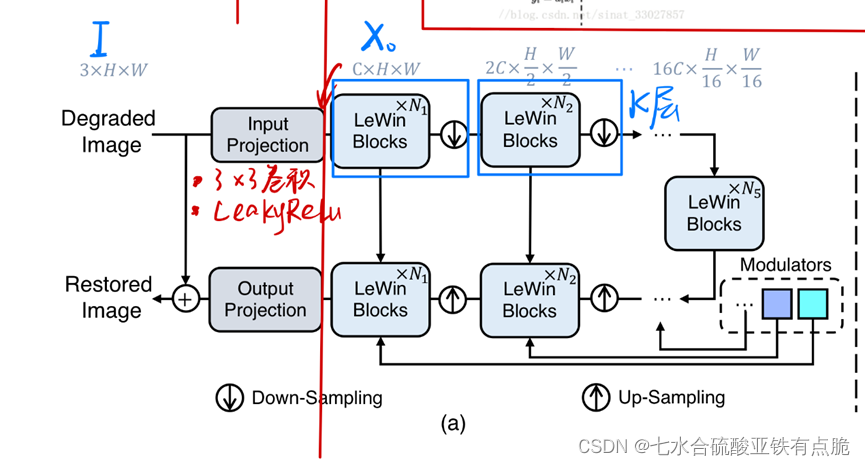
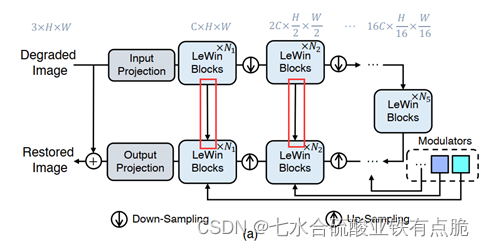
2.1 整体结构
编码器:
- 输入图像I,input projection提取底层特征
- 3×3卷积
- LeakyReLU,得到特征图X。
- 通过K个模块,每个模块包含一个LeWin transformer块和一个下采样层。
LeWin transformer块
- 下采样层:把transformer输出的一维向量reshape为二维特征,再进行正常下采样
- 步长为2的4×4卷积核:通道数加倍;分辨率HW都减半
- 最后一层:多个LeWin块:捕获远程信息,如果卷积核尺寸和特征图大小相同,甚至捕获到全局信息。
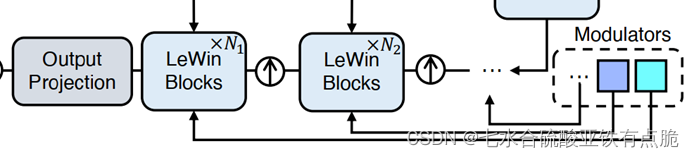
解码器:
- K个模块,每个模块对应一个上采样层和一个LeWin transformer块。
- 上采样层:步长为2的转置卷积,卷积核尺寸为2×2:分辨率加倍,通道数减半
- LeWin transformer块传入:经过上采样层处理的特征图+编码器对应层的特征图(跳跃连接)+Modulartors传入
- 最后:输出的一维向量,reshape为二维,使用3×3的卷积层获得与输入图像尺寸相同的残差图R,与输入图像相加,输出
文中K=4;损失函数:
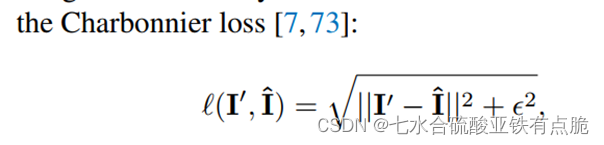
L1和L2损失会造成图像过于平滑的问题,缺乏感官上的照片真实感;
效果的猜测:常数的存在,避免了梯度消失(接近0 的点);
开方避免梯度爆炸?
2.2 LeWin transformer Block
trnasformer存在问题:
-
计算复杂度(可以计算所有token之间的全局自注意力,计算复杂度是token数量的二次方,不适用于高分辨率任务)
-
trnasformer在获取局部信息存在局限性
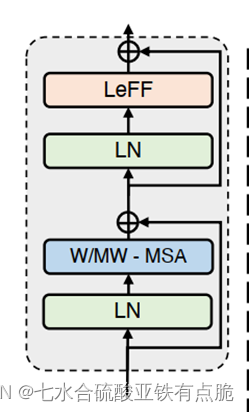
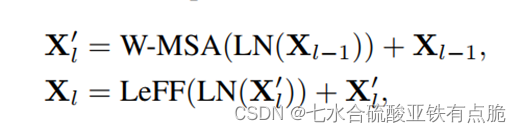
LN:Layer Norm -
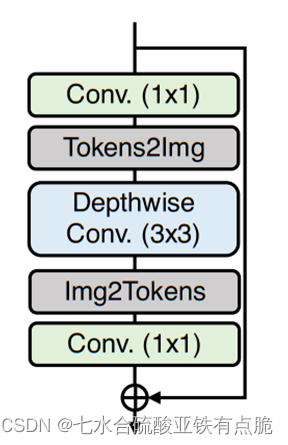
W-MSA: non-overlapping Window-based Multi-head Self-Attention
· 二维图像X,通道数为C,HW
· 将X切割为多个尺寸为M×M的窗,窗与窗之间不重叠
· 将每个窗的图像拉伸为一维,这样每个窗内的图像区域就成了M平方的向量
· 每个窗内的这些向量用自注意力机制进行处理
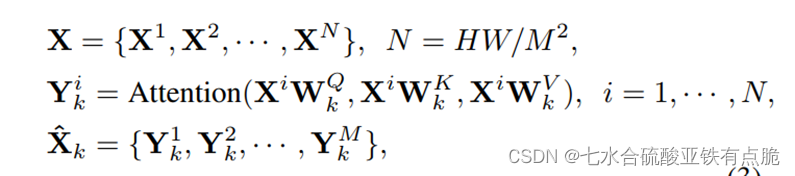
· 计算第k个头的自注意力。
· 将k个头的输出拼接,线性投影,最终W-MSA输出。
· 完整注意力机制:(B,相对位置偏置)
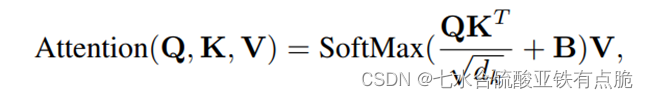
效果:降低计算复杂度
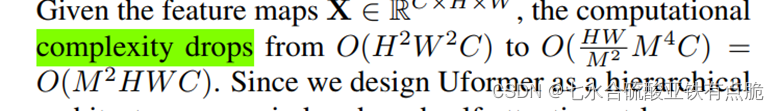
分窗口,分层,低分辨率上的自注意力机制可以获得很大的感受野,能学习远程信息 -
LeFF: Locally-enhanced Feed-Forward Network 局部增强前馈网络
· transformer中的前馈网络在捕捉局部上下文信息具有局限性,因此加入深度卷积
· 1×1卷积核,处理每个token增加通道数量
· 将token重新变为二维特征图
· 3×3的卷积捕获局部信息
· Img2Tokens将二维特征图拉回一维token
· 1× 1卷积降低通道数量使其和输入前的通道数量相同,叠加。
· 激活函数:GELU
2.3 Multi-Scale Restoration Modulator 多尺度恢复调制器
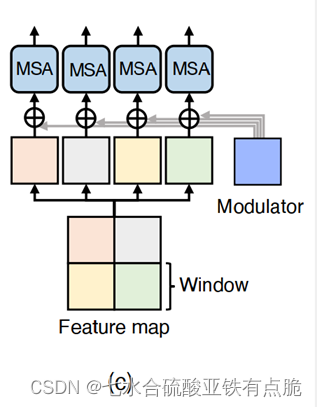
- 调制器:M ×M ×C 的可学习张量,在自注意模块之前添加到所有非重叠窗口。
- 引入了边际额外参数和计算成本,但是很小。有助于以很少的计算成本恢复细节。
- 有效性:图像去模糊和图像去噪。
可视化:

可能的解释:在解码器的每个阶段添加调制器可以灵活调整特征图,从而提高恢复细节的性能。
3 Experiment

· 动量项为(0:9; 0:999)
· 权重衰减为0.02
· 余弦衰减策略
· 用PSNR和SSIM结构相似性作为评价指标,除了去雨任务,其他任务都是在RGB色彩空间进行指标计算。去雨在YCbCr色彩空间的Y通道计算指标
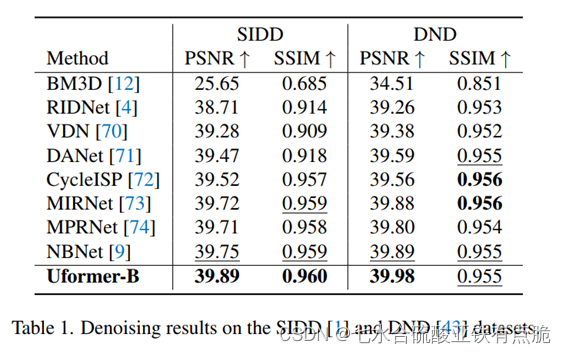
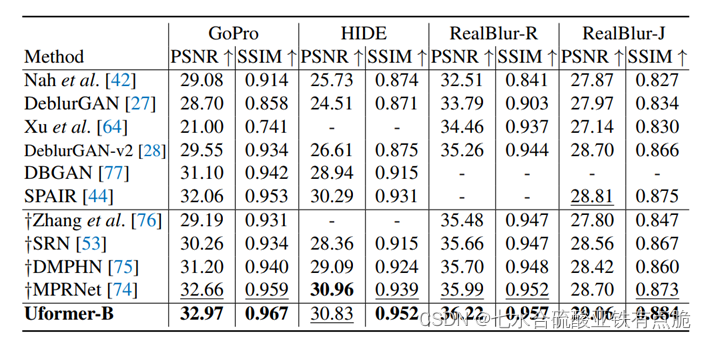
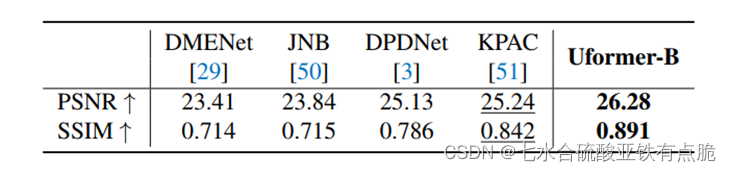


4 消融实验
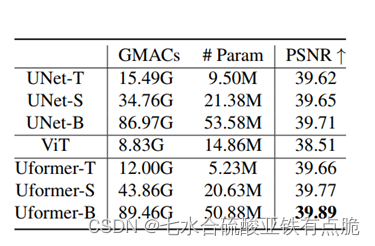
 Transformer与CNN的对比: 将LeWin Transformer块中的用基于CNN的ResBlock代替
Transformer与CNN的对比: 将LeWin Transformer块中的用基于CNN的ResBlock代替
层次结构的多尺度与单一尺度的对比: 基于ViT的单一尺度模型用在降噪,包含两个卷积层的头用于特征提取,一个包含两个卷积层的尾用于输出,头和尾之间设置了12个transformer块

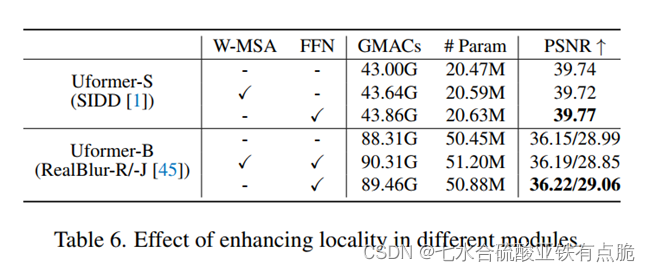
Locally-enhanced在各个位置的效果: 不用局部增强/放在自注意力部分/都放
结论: 放在前馈网络处效果最好
GMACs:乘法累加操作次数
多尺度恢复调制器:

5 Conclusion
提出Uformer
- LeWin Transformer块:
· 非重叠窗口的自注意力—降低计算复杂度+捕获更多全局依赖关系
· 前向传播的网络,两个全连接层之间引入深度卷积层—更好捕获局部上下文
· 可学习、多尺度、恢复调制器Modulator:处理图像退化,恢复更多细节。
6 Addition
- 窗口移位的作用 消融实验 0.01??

- 跳跃连接的变体:设计了三种不同的跳过连接机制
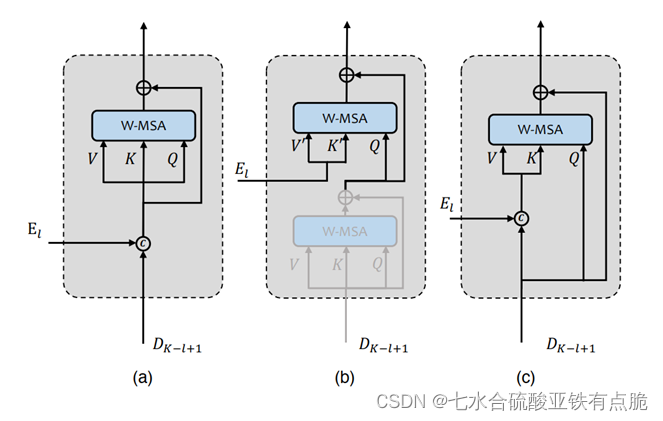
- Concat Skip:UNet广泛运用。将第 l 阶段的编码特征 El 和(K-l+1) 解码器阶段的特征 DK-l+1 逐通道拼接。K 是编码器/解码器阶段的数量。拼接特征馈送到解码器阶段的第一个 LeWin 块的 W-MSA 模块
- Cross Skip:参考Transformer中的解码结构。在第一个LeWin模块中添加一个额外的注意力模块,它用于从解码特征D中寻找自相似像素信息,而第二个注意力则从解码特征中提取key与values,从第一个注意力模块输出中提取queries。
- Concat Cross Skip:组合前两种。编码特征提取v k,解码特征提取queries。
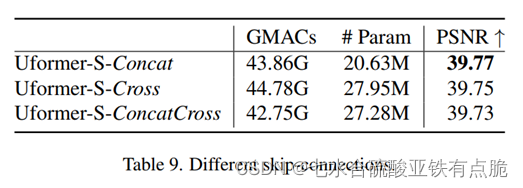
效果: Concat最好。(正常浮动?原本在正文,后改到附录)GMACs:计算量
其他实验部分:
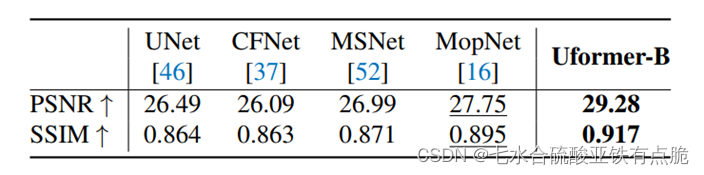
莫尔条纹的移除 效果不错

















 341
341

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









