







| 目录 |
| - - 1. Network pruning - 1.1 为什么需要大的network? - 1.2 Practical Issue - 2. Knowledge Distillation - 2.1 Teacher network - 2.1.1 trick - 3 Parameter Quantization - 3.1 改变参数的dtype, 比如变成16位 - 3.2 Weight Clustering - 3.3 Binary Weights - 4. Architecture Design - 4.1 Low rank approximation - 4.2 Depthwise Separable Convolution - 5. Dynamic Computation - 5.1 保存多个网络 - 5.2 中间层连接多个分类器
概述 终于了解到关于网络压缩的各种知识。
|
1. Network pruning
很直观的想法是,如果有一些neuron output一直为0或接近0,则这些是没有作用的。
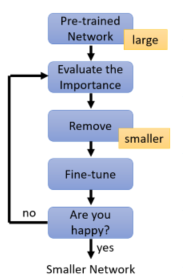
1.1 为什么需要大的network?
common sense:大的network容易optimal,现在有很多研究证明,大的network容易train,不容易陷入local minima,甚至大多数时候都能找到global mimima。
1.2 Practical Issue
pruning neuron or pruning weight ,答案是pruning neuron比较好。后者影响矩阵运算,影响GPU加速。
2. Knowledge Distillation
2.1 Teacher network

用Teacher net的输出作为Student Net的label。让小模型获得大模型的结果。
这一招可以用在ensemble那边,在kaggle中,最后的一招就是ensemble,谁ensemble得多,谁的performance就好,但问题在于,实践中,这是没有意义的,你不能试图让设备放进1000个模型,所以这个可以用来简化ensemble的模型,保持原来的结果。
2.1.1 trick
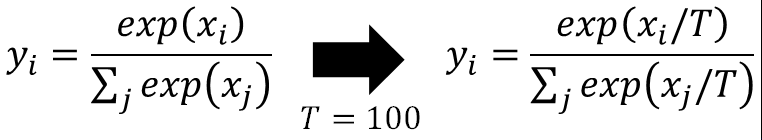
通常在softmax的时候,会让输出除以T,这是为了缓解softmax对输出差距的放大作用,让student更好地学到teacher学到的东西。
划重点:助教实作发现这个方法没什么用。
3 Parameter Quantization
3.1 改变参数的dtype, 比如变成16位
3.2 Weight Clustering

参数不再使用参数本身,而使用聚类,利用如均值来代表该类别,于是每个参数只需要一个2bit长度就可以代替原32bit的长度。这个方法虽然会有损失,但是可以让网络变得很小。
3.3 Binary Weights
上面的方法的进阶版本是让weight直接以+1-1的形式存在,这个每个位置只需要1个bit。而这个确实trian得起来。

这种居然能train得起来,它是这样的,上述每个灰色点代表一个weight的状态(全+1-1),而蓝色的点和一般网络一样,随机初始化,然后找最近的点求梯度,更新蓝色点,再重复。
它和正常网络其实很类似,只不过每次都对weight做吸附。
研究表明,这种网络类似于对weight做正则化,使得它无法任意取值。
4. Architecture Design
4.1 Low rank approximation
熟悉矩阵运算应该知道,这个思想类似于我们做矩阵乘法优化。在原本是M * N,最终变成N * K + K * M, 参数量因为K的取值而改变。这种做法虽然有效,但是熟悉线性代数应该知道,新的两个矩阵的rank都不会超过K,所以这种做法是有损失的。

4.2 Depthwise Separable Convolution
这种方法是对于cnn层次的优化。
普通cnn:

优化

它每个通道都只设定一个filter,用户捕获单通道的信息,而通道之间的关系交给pointwise convolution。最终的结果:输出和原来conv一致,而参数量大大减少。这其实和第一种方法本质类似。
课程的投影做的太好了。以上过程进一步可视化。
对于每次卷积操作,
标准卷积,十八个inputs,一个ouput,不同输出通道weight不同
dwconv,每个通道9个input,再连接n个单元,作为输出,n位输出通道个数
可以看到,对于dwconv,输出n个单元可能变化,但前面的输入永远是一样的。

为什么说这个东西和Low rank approximation类似呢,如下图。

而且根据数学公式,上述可量化为1/k*k。当前非常出名的mobile net,xception net等等用的就是这个方法。
5. Dynamic Computation
这是一个经常听见的概念,终于学到了。它是想要网络根据不同的设备性能,提供不同的结果——如果设备不太行,例如没电,它希望网络也能给出一个相对好的结果。有如下几种做法。
5.1 保存多个网络
这个简单到不能再简单了。
5.2 中间层连接多个分类器
一图可以描述。

但是,在太早的地方接上分类器会破坏网络的原有特征,这很显然,因为这是joint learning,靠前的分类器要求特征抽象,靠后的分类器要求前面的特征简单。
于是,MSD network专门propose来处理这个问题。Multi-Scale Dense Networks















 5126
5126











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









