






 本文介绍了one-hot编码在早期语言处理中的应用,随后探讨了RNN和LSTM的局限性,以及自注意力机制如何改进生成速度。重点讲解了BERT的预训练和微调过程,强调了多层自注意力机制在Bert结构中的核心作用,以及其在自监督学习中的重要性。
本文介绍了one-hot编码在早期语言处理中的应用,随后探讨了RNN和LSTM的局限性,以及自注意力机制如何改进生成速度。重点讲解了BERT的预训练和微调过程,强调了多层自注意力机制在Bert结构中的核心作用,以及其在自监督学习中的重要性。
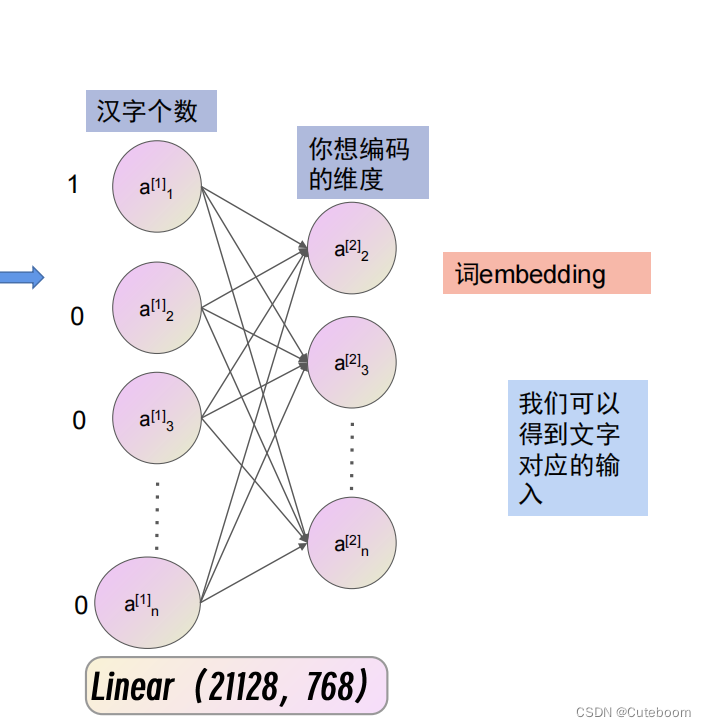
文字编码
one-hot编码,让模型自己去学习怎么进行编码
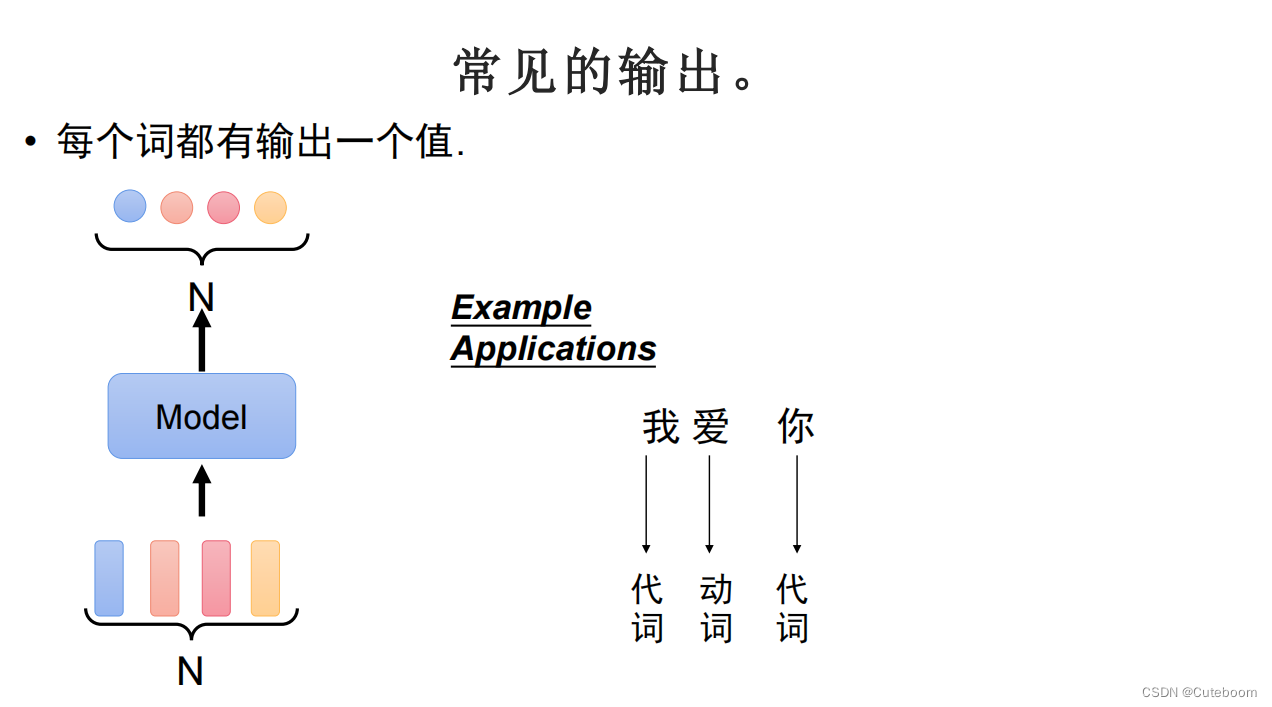
 常见的输出
常见的输出
1.每个词都有一个输出值
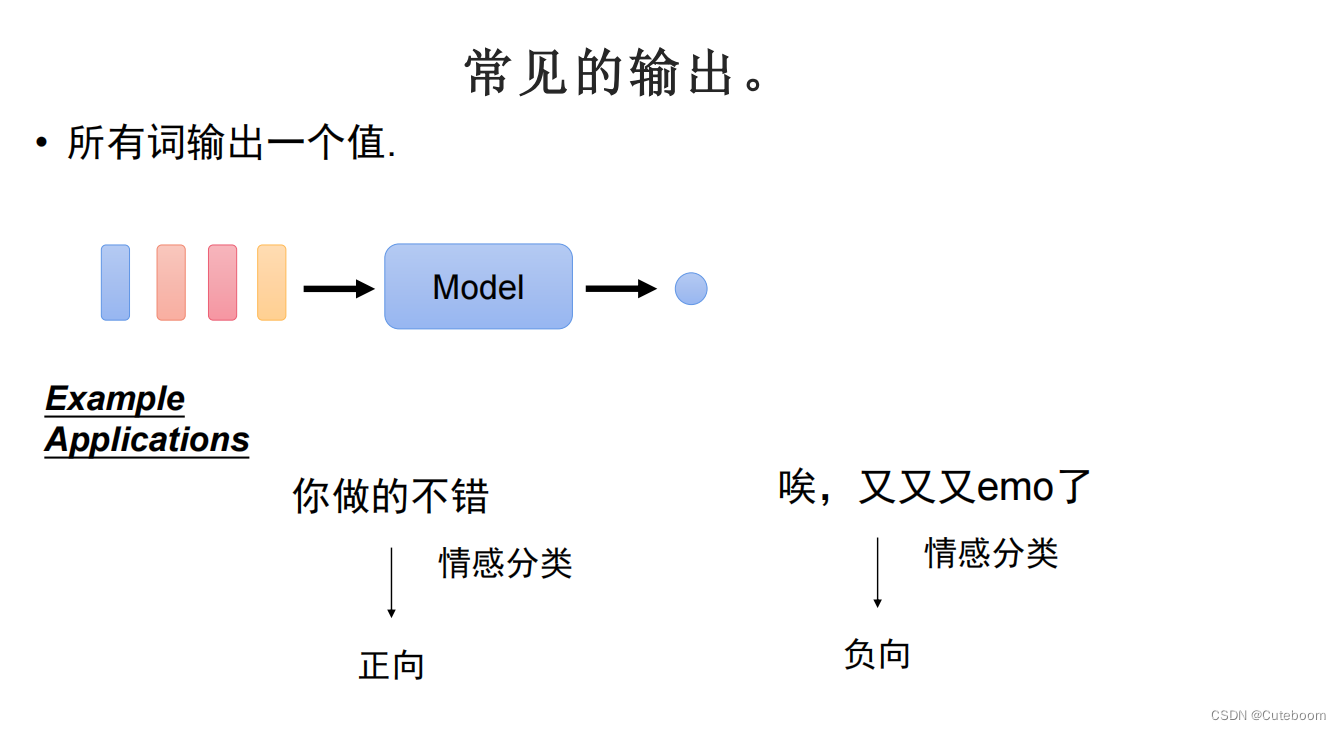
 2.每个句子输出一个值,情感分类
2.每个句子输出一个值,情感分类
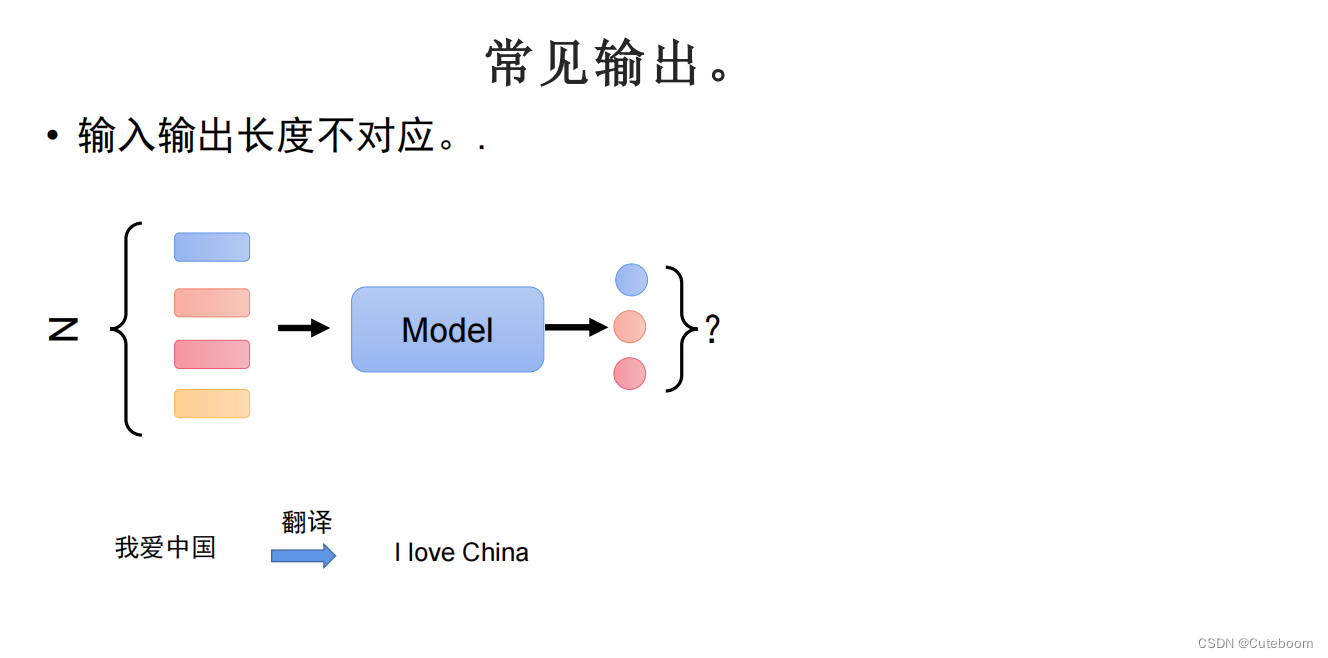
 3.输入与输出长度不对应,翻译任务,生成任务。
3.输入与输出长度不对应,翻译任务,生成任务。
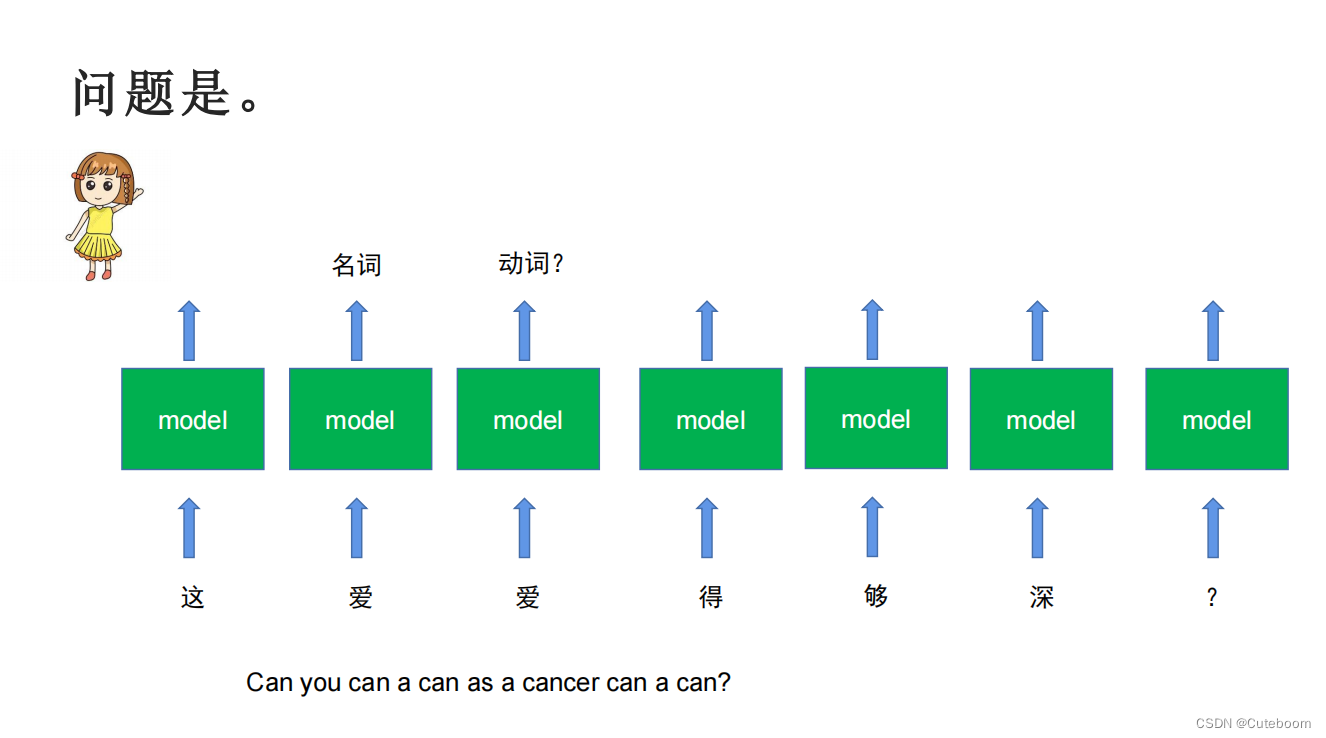
 RNN最早的语言处理
RNN最早的语言处理
RNN解决的是模型去考虑前面的输入
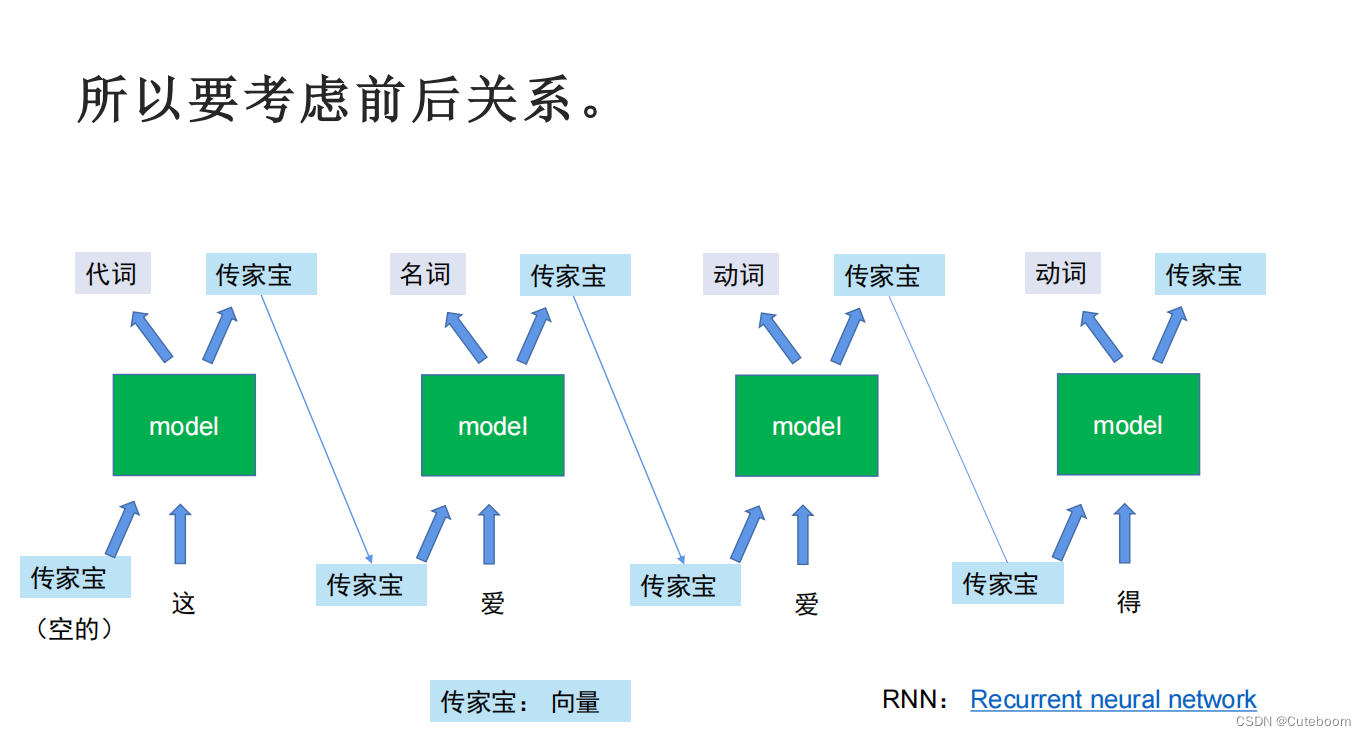 RNN的缺点,每一代都要向传家宝中装东西,导致后面看不到祖先。
RNN的缺点,每一代都要向传家宝中装东西,导致后面看不到祖先。

长短期记忆(LSTM,long short-term memory)
 RNN与LSTM速度很慢,需要一代一代,无法一下生成全部。所以引入了自注意力机制。
RNN与LSTM速度很慢,需要一代一代,无法一下生成全部。所以引入了自注意力机制。
自注意力机制的原理:
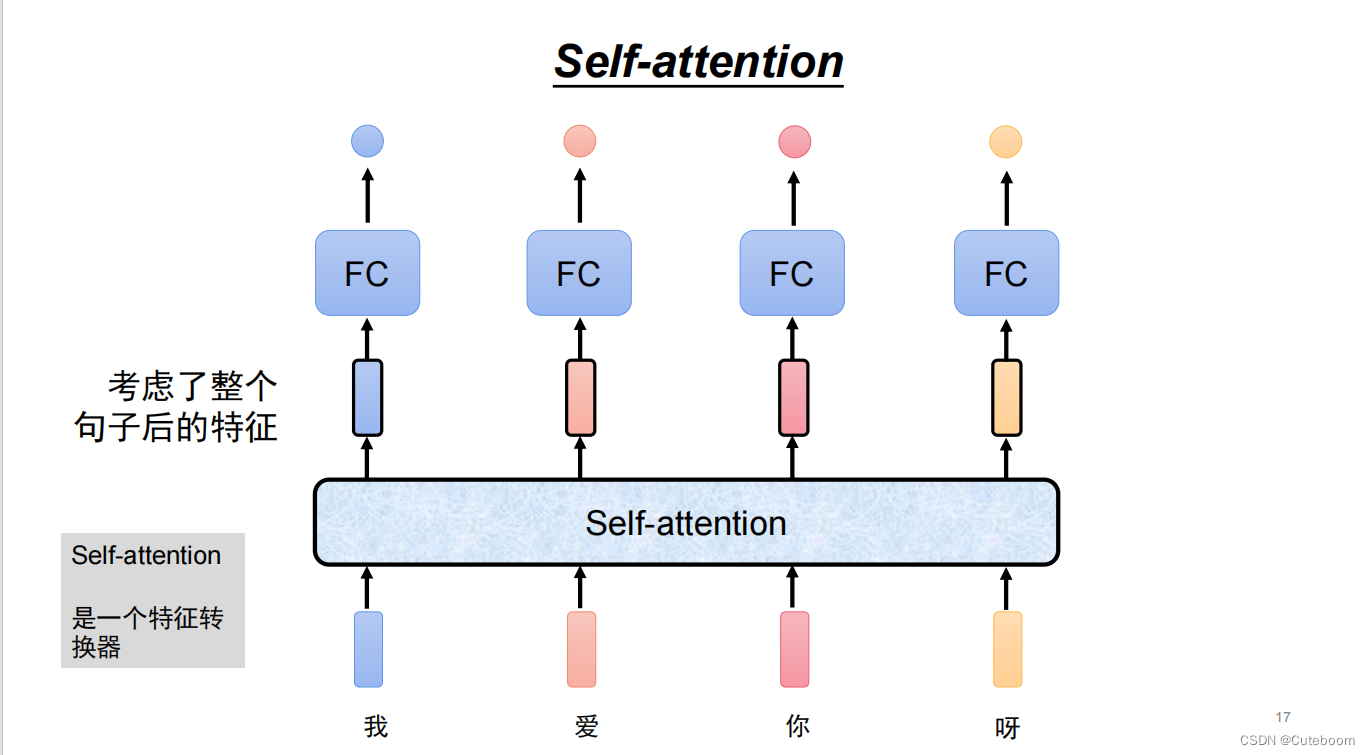
什么是注意力,分配给每个任务的注意力,注意力的高低是自己决定的。
 注意力分配
注意力分配

如何计算注意力?
在不同的句子中,注意力应该不同,并且模型要有学习设置注意力的能力。因此采用点乘的方式。

加了wq,wk得到的矩阵。
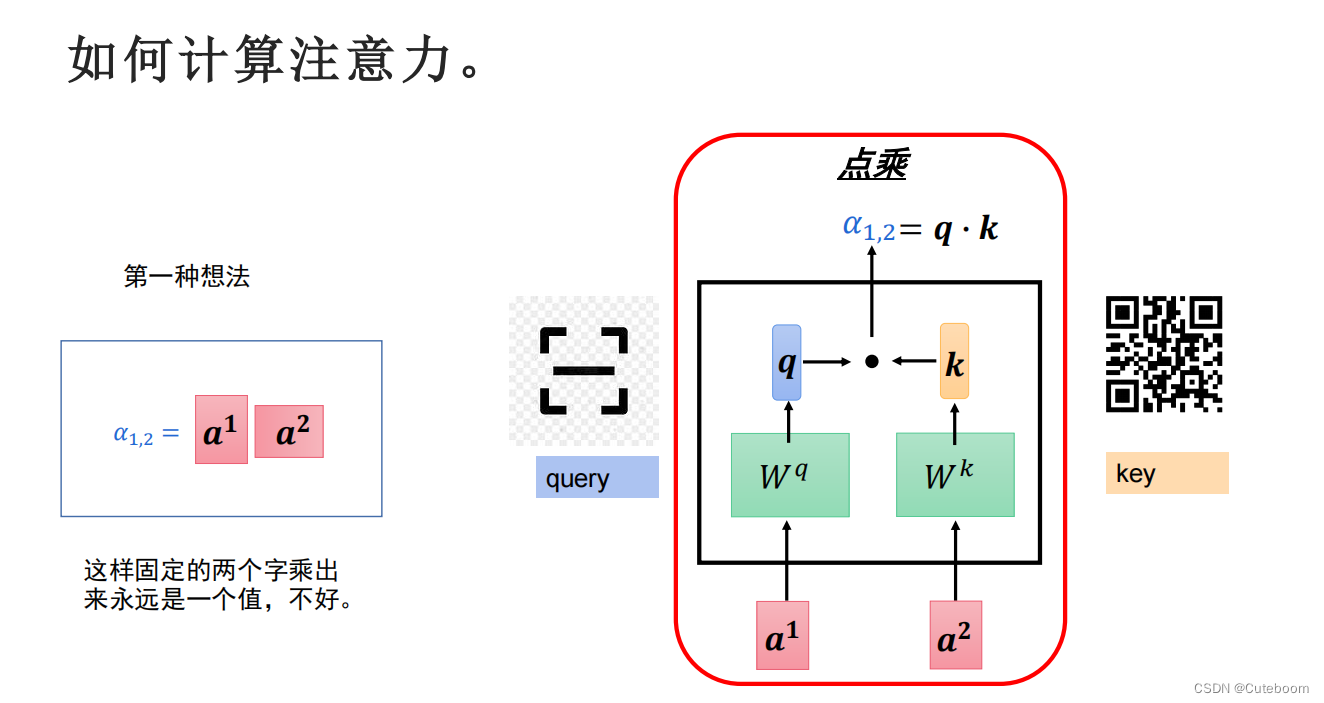
 得到a1对其他的注意力分数。
得到a1对其他的注意力分数。
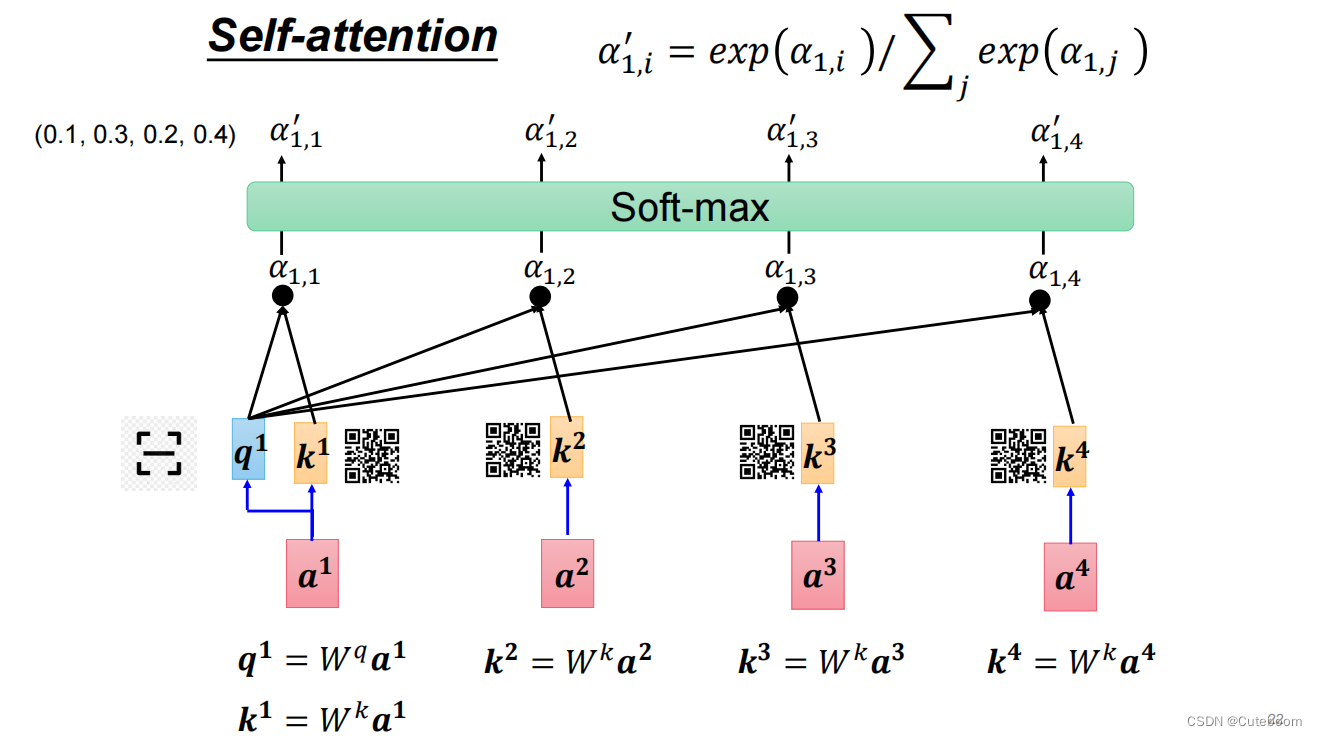 利用soft-max对分数进行归一化,化为合为1的概率。
利用soft-max对分数进行归一化,化为合为1的概率。
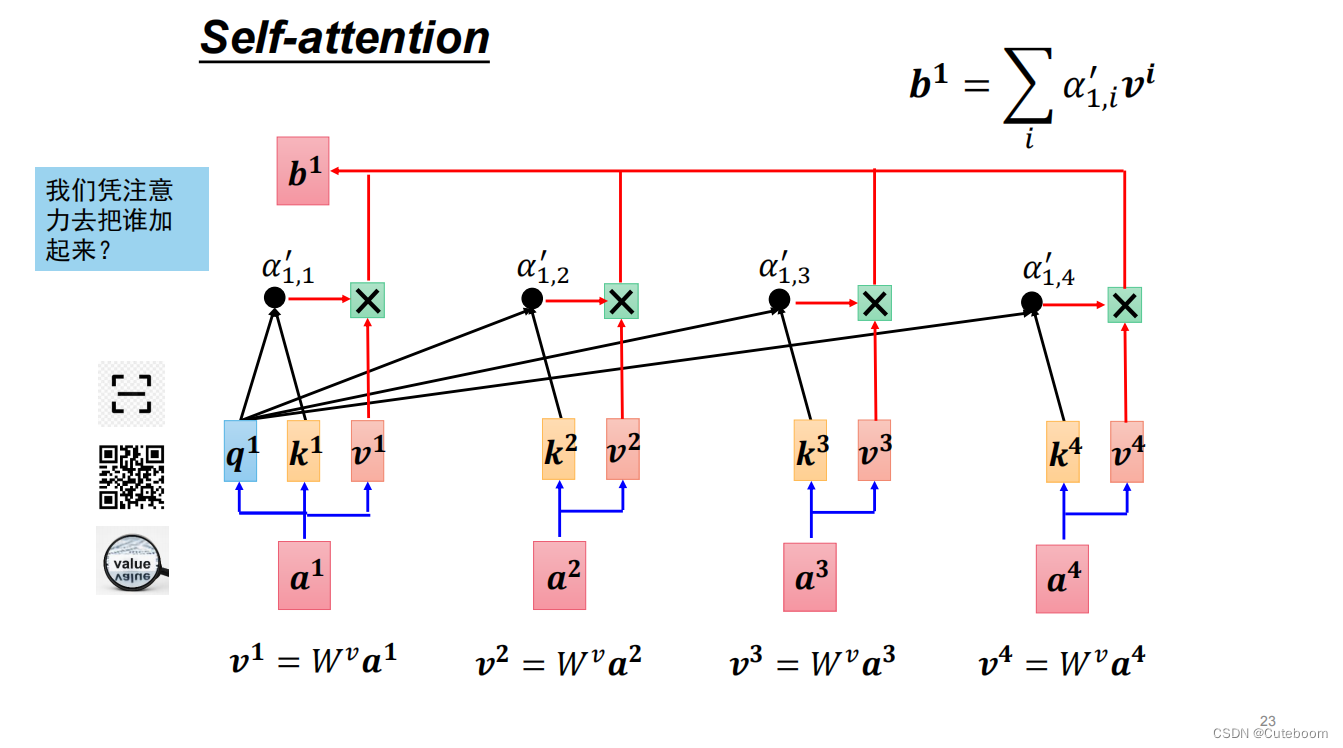

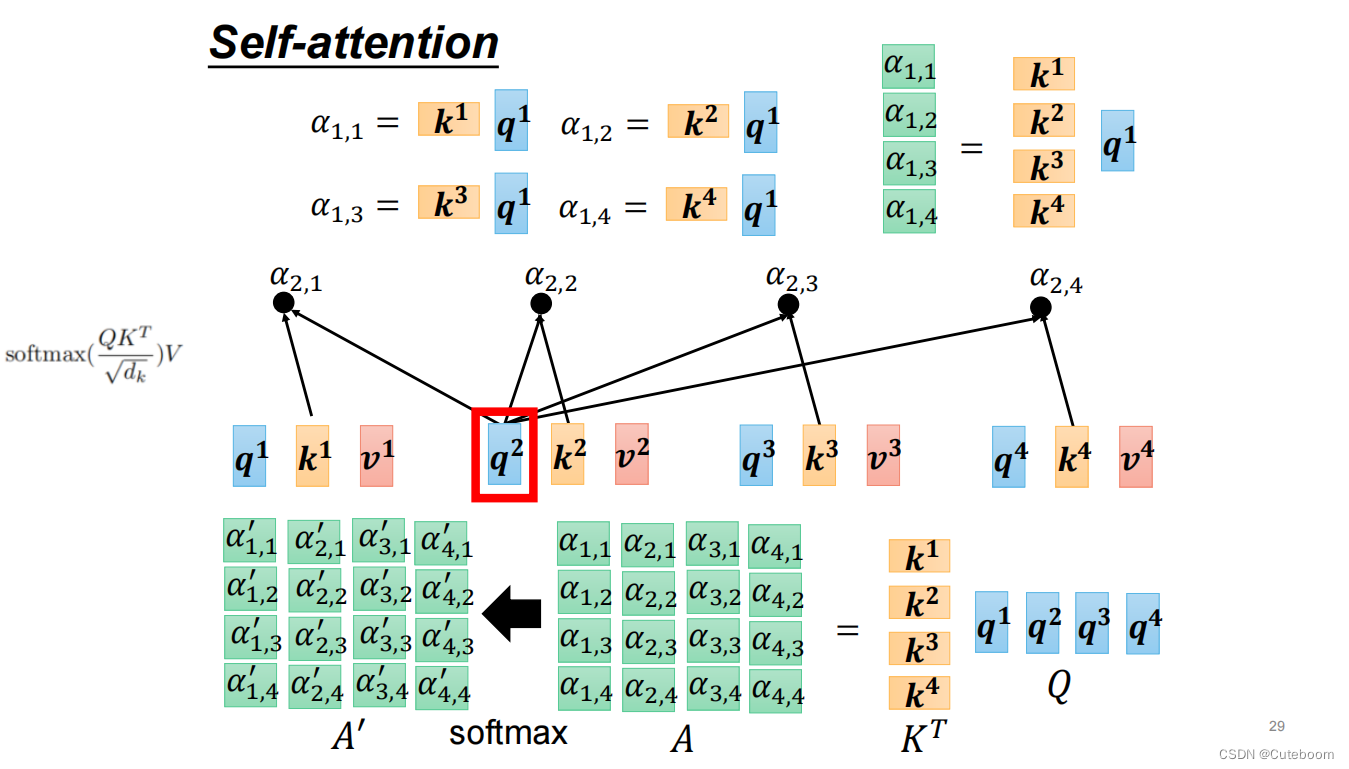
 b1的生成过程:a1矩阵化为q(通过wq),利用这个q与其他(a2、a3、a4)生成的w分别进行点乘,生成a1.1、a1.2、a1.3、a1.4。再讲a1、a2、a3、a4的value与a1.1、a1.2、a1.3、a1.4相乘。成绩和为b1。
b1的生成过程:a1矩阵化为q(通过wq),利用这个q与其他(a2、a3、a4)生成的w分别进行点乘,生成a1.1、a1.2、a1.3、a1.4。再讲a1、a2、a3、a4的value与a1.1、a1.2、a1.3、a1.4相乘。成绩和为b1。
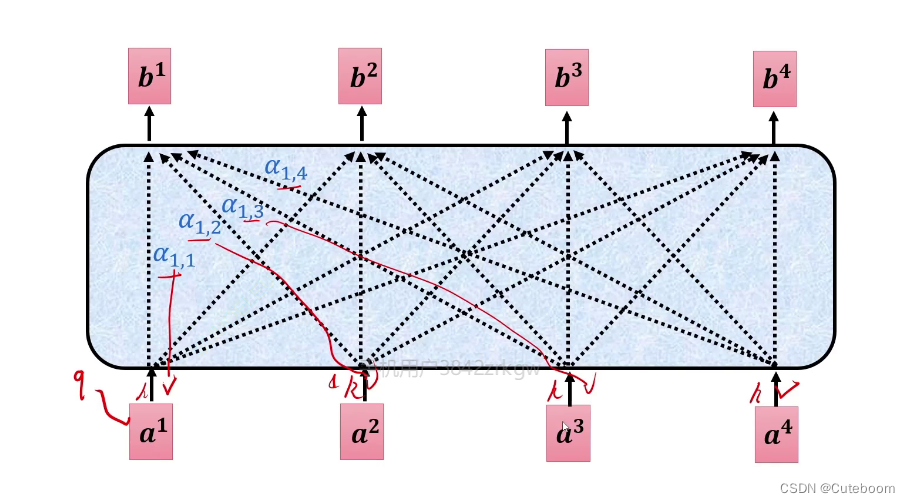
总结过程为:

总公式可以表示为:
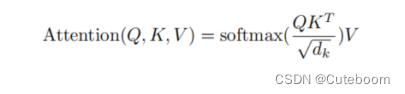
A:注意力矩阵。

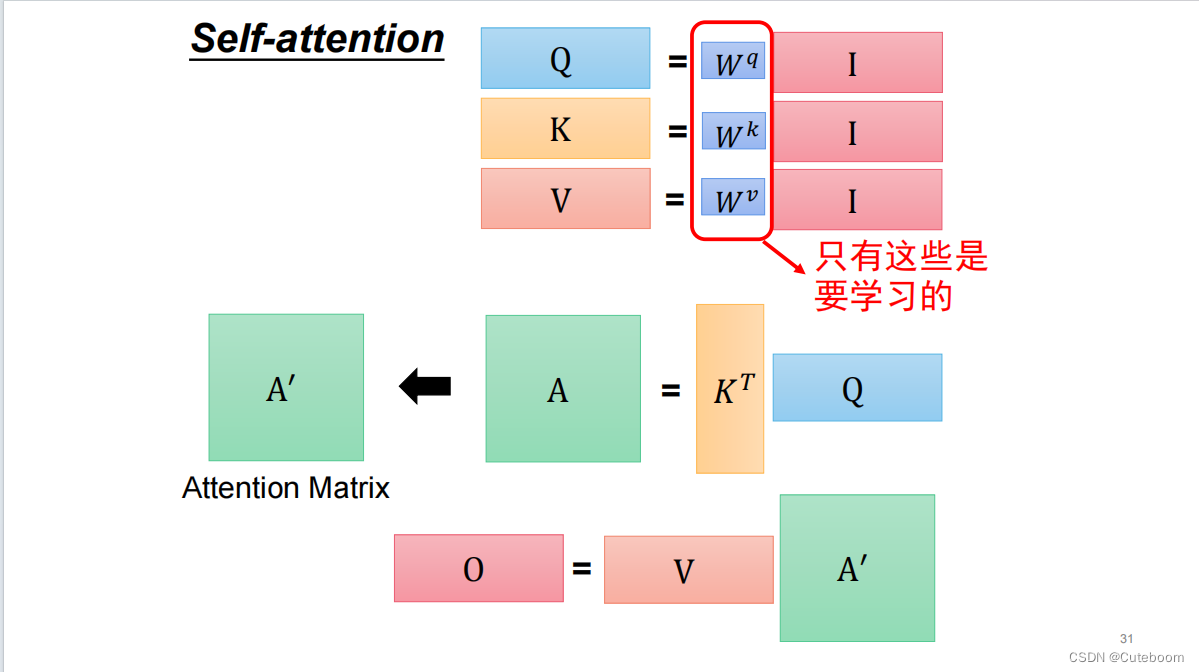 Wq 和 Wk、Wv是学习到的权重矩阵
Wq 和 Wk、Wv是学习到的权重矩阵
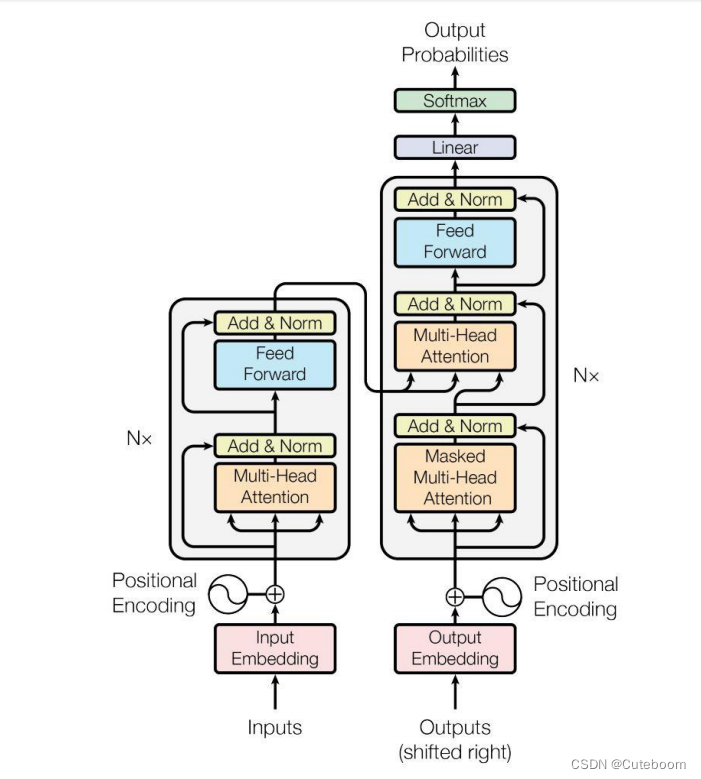
bert,该图左侧部分构成了bert。右边为提取特征,然后再生成,即为GPT
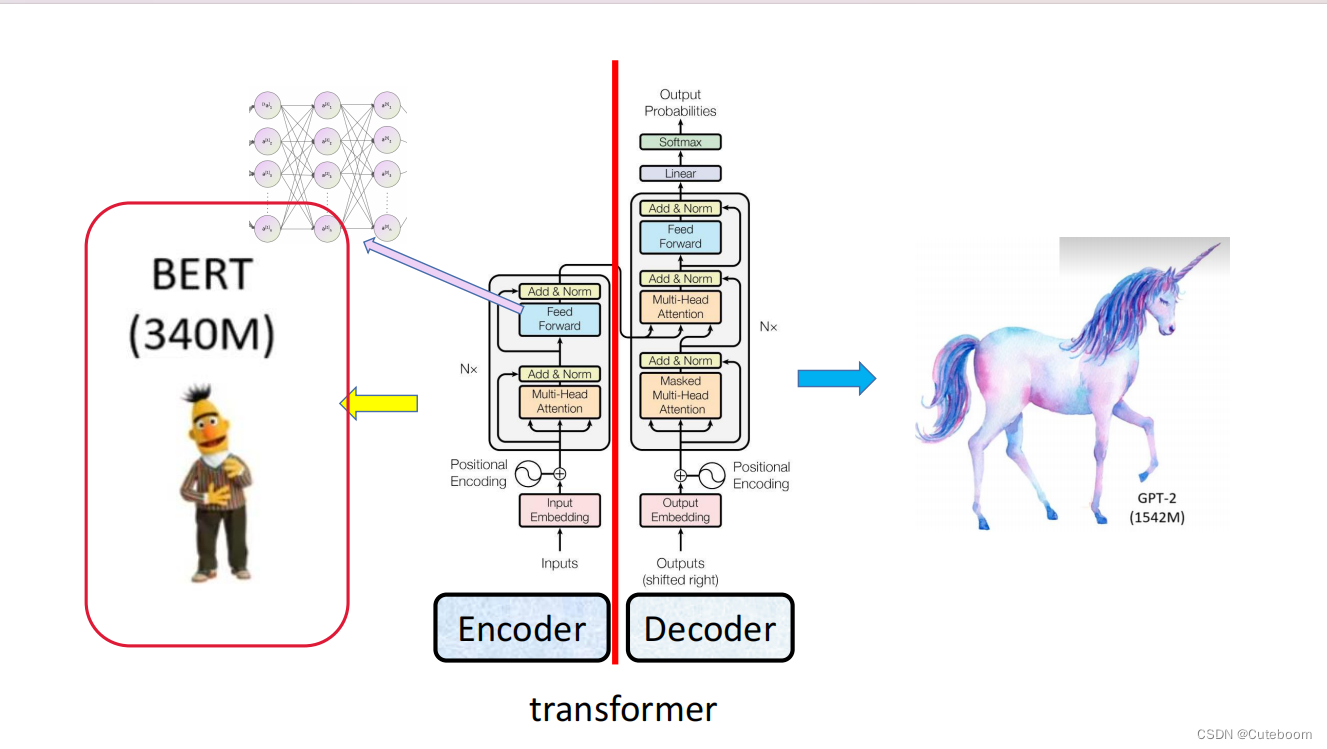
bert就是一个特征提取器。
1.预训练
2.微调
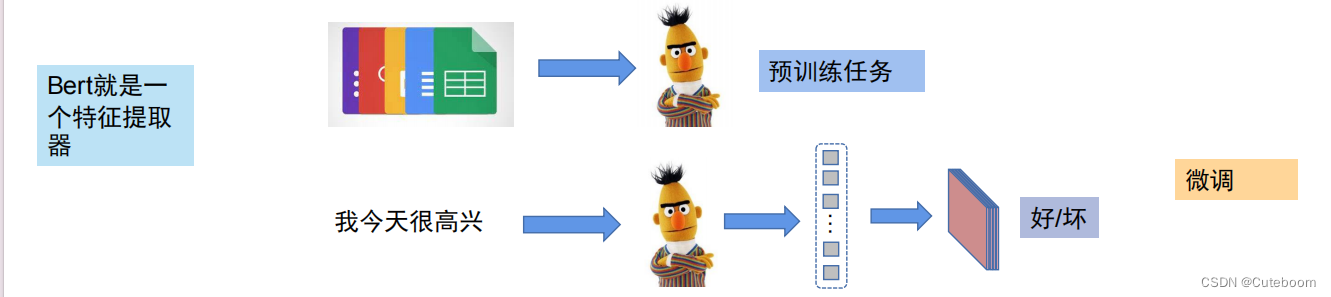
自监督预训练

Bert结构
1.embedding
2.多层自注意力机制
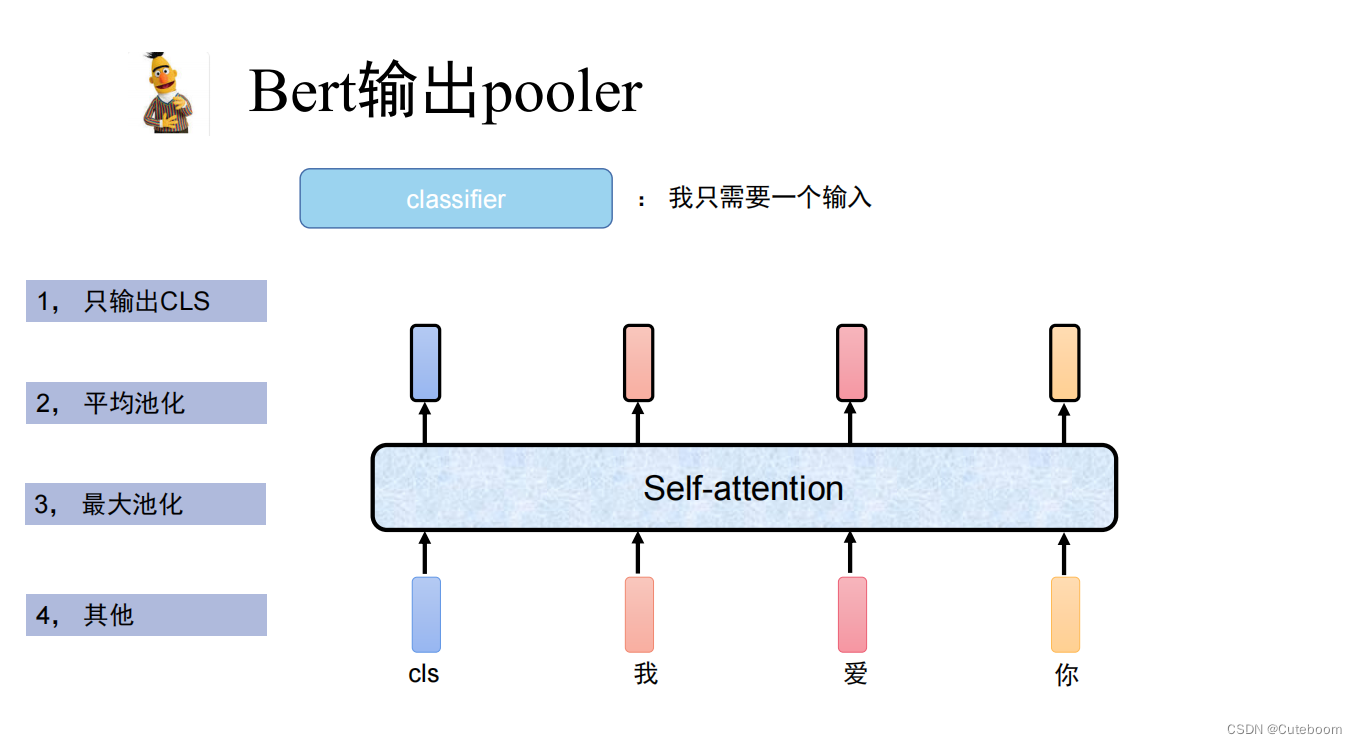
3.池化输出

Bert的输出

EA,EB为给句子的编码
CLS相当于链表头,SEP相当于句号,句尾结束。
















 16万+
16万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









