







44物体检测算法:R-CNN,SSD,YOLO【动手学深度学习v2】
深度学习学习笔记
学习视频:https://www.bilibili.com/video/BV1if4y147hS/?spm_id_from=333.337.search-card.all.click&vd_source=75dce036dc8244310435eaf03de4e330
目标检测中的常用算法,首先是区域卷积神经网络,最早的模型是R-CNN(居于区域的CNN)。
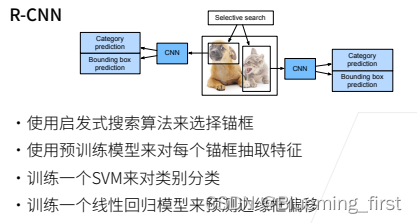
R-CNN
启发式搜索算法来选择锚框:选出很多锚框之后,对每个锚框当做一张图片,使用训练好的模型来抽feature,训练一个SVM来对类别进行分类。使用线性回归来预测锚框与真实框的偏移。
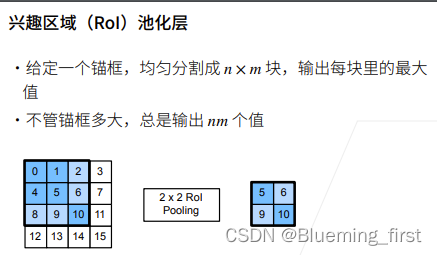
锚框选择后,怎么保证锚框能变成一个batch,使用办法为兴趣区域池化(RoI 池化): 将一个锚框均匀切分成 nm 块,输出每块中的最大值,做 RoI Pooling,输出nm个值,这样不同的锚框会输出同样大小的batch。
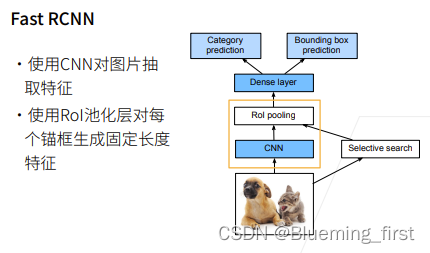
之后出现的模型是 Fast RCNN
Fast RCNN
改进:一张图片抽1000个锚框的话,要用1000次CNN抽取feature,那么计算量就太大了,Fast RCNN 首先对图片抽feature,对整张图片抽,而不是对一个锚框,然后再在图片上搜锚框,将锚框映射到CNN上面,再得到更小的锚框,之后用RoI pooling上对每个锚框抽取特征,最后到全连接层,在上面对每个锚框做预测和与真实边缘框的偏移。
主要地方是不是对每个锚框做抽取,而是对整个图片做抽取。再在抽取的特征上面再找锚框抽feature,之后就做预测了。
Faster RCNN
用神经网络替代之前的选择性抽取算法。
图片输入进CNN,把CNN的输出(再做一次卷积,然后生成很多的锚框,进行一次二分类训练,来预测这个锚框到底有没有框住物体和计算真实边界框之间的差别,输出一些好的锚框)送到RoI pooling ,最后对锚框中的物体预测和真实边框差别计算。(做了两次预测,一次糙一点的,一次精确一点的预测)。

Faster RCNN 精度很高,主要应用在对精度关注特别高时。工业界大多数更关心速度。

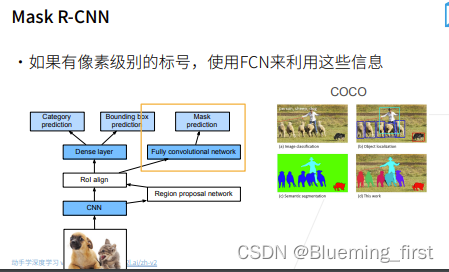
Mask RCNN
跟fast RCNN 没有太大区别,新变化为:如果有像素级标号,对每个像素做预测。 对RoI出来的东西,进行FCN和Mask预测。
RoI align

单发多框检测(SSD)
核心思想:RCNN主要是做了两个预测,SSD就只做一次预测。
SSD现在用的不多。
主要思想:对每个像素,以每个像素为中心生成多个锚框(与锚框那节生成方式一样)。

SSD模型:对给定的那些锚框,直接做预测。输入图片,先CNN抽取特征,每个像素生成多个锚框,每个锚框变成一个样本,进行预测类,判断是圈出了背景还是类并且计算与真实锚框之间的差别。SSD通过在多个分辨率下抽取特征,下层拿到比较大的输出,越到上层越小,在底层检测一些小的物体,在上面就检测 到大的物体。
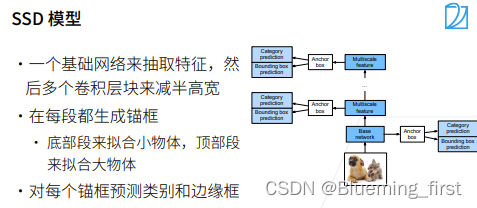
SSD 相对来说速度比较快,但精度不太高。


YOLO (你只看一次)
YOLO 追求的是快,也是一个单神经网络的算法。
尽量让锚框不重叠,将一张图片均匀成多块,每一块就是一个锚框。

如绿色部分,一个块就是一个锚框。
每个锚框会去b个边缘框(也就是b个物体都和这个锚框很近)(最原始的做法,后面v2 v3 等等有些改进)。

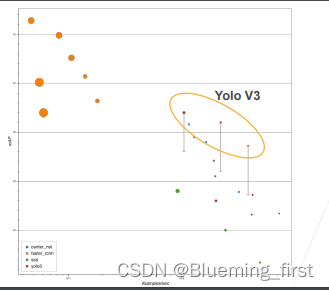
Yolo v3 使用很多别的trick性能会提高, 比faster RCNN 要快很多。















 182
182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









