








 本文深入探讨了图嵌入的概念,包括同质图、异质图、属性图和非显式图的输入,以及节点嵌入、边缘嵌入、混合嵌入和全图嵌入的输出。图嵌入技术涵盖矩阵分解、深度学习、边缘重构优化和图核,广泛应用于节点分类、链接预测和图分类等领域。未来的研究方向包括计算效率提升、动态图处理和非深度学习方法的探索。
本文深入探讨了图嵌入的概念,包括同质图、异质图、属性图和非显式图的输入,以及节点嵌入、边缘嵌入、混合嵌入和全图嵌入的输出。图嵌入技术涵盖矩阵分解、深度学习、边缘重构优化和图核,广泛应用于节点分类、链接预测和图分类等领域。未来的研究方向包括计算效率提升、动态图处理和非深度学习方法的探索。
目录
- 前言
- Abstract
- 1.Introduction
- 2.Problem Formalization
- 3.Problem Settings Of Graph Embedding
- 4.Graph Embedding Techniques
- 5.Applications
- 6.Future Directions
- 7. Conclusions
前言

题目: 图嵌入的综合研究:问题、技术和应用
期刊: IEEE TKDE
原文地址:A Comprehensive Survey of Graph Embedding: Problems, Techniques, and Applications
本文是图嵌入领域被引用较多的一篇综述性文章,非常适合作为图挖掘的入门论文!前面一篇论文KDD2016 | node2vec:Scalable Feature Learning for Networks中提出的node2vec就是一种基于深度学习(SGD优化)的随机游走图嵌入技术。
本文很长,但同时干货很多,相信看完此文后对图嵌入会有一个比较充分的认识。
Abstract
大多数图分析方法的计算量和空间成本都很高,图嵌入是解决图分析问题的一种有效的方法。它将图数据转换到一个低维空间,在这个低维空间中,图的结构信息和图的性质得到最大限度的保留。
本篇综述对图嵌入进行了比较系统全面地回顾,主要内容如下:
- 介绍了图嵌入的形式化定义以及相关概念
- 提出了图嵌入的两个分类方法
- 总结了图形嵌入的应用,并从计算效率、问题设置、技术和应用场景四个方面提出了未来的研究方向
1.Introduction
图在现实生活场景中比较常见,比如社交网络中的社交图/扩散图,研究领域中的引文图等等。社交网络中比较常见的应用如:通过分析基于社交网络中用户交互(如Twitter中的转发/评论/关注)构建的图,我们可以对用户进行分类,给用户推荐朋友等等。
现有的大多数图分析方法都存在较高的计算和空间成本,图嵌入是解决图分析问题的一种有效的方法。它将图数据转换到一个低维空间,在这个低维空间中,图的结构信息和图的性质得到最大限度的保留。

图有不同的类型(如同质图、异质图、属性图等),所以图嵌入的输入在不同的场景下是不同的。图嵌入的输出是表示图的一部分(或整个图)的低维向量。
图1给出了在不同粒度的二维空间中嵌入一个图形的示例。即根据不同的需要,我们可以将节点/边/子结构/整个图表示为低维向量。
图嵌入问题涉及两个传统的研究问题:图分析和表示学习。需要注意的是:图表示学习不要求学到的表示是低维的,图嵌入是需要的。
在本研究中,将输入图分为四类:同质图、异质图、信息图和非显式图。将图嵌入输出也分为四类:节点嵌入、边缘嵌入、混合嵌入和全图嵌入。
1.1 Our Contributions
- 提出了一种基于问题设置的图嵌入分类方法,并总结了在每个问题设置中所面临的挑战。
- 对图嵌入技术进行了详细的分析。
- 系统地对图嵌入支持的应用场景进行了分类:节点相关、边缘相关和图相关。对于每一类,都给出了详细的应用场景作为参考。
- 从图嵌入的计算效率、问题设置、求解技术和应用场景四个方面提出了图嵌入未来的研究方向。
1.2 Organization of The Survey
行文组织:
-
第2节介绍了理解图嵌入问题所需的基本概念的定义。
-
第3节比较了基于问题设置的相关工作,并总结了在每个设置中所面临的挑战。
-
第4节介绍图嵌入技术。
-
第5节介绍了图形嵌入支持的应用场景。
-
第6节讨论了四个潜在的未来研究方向。
-
第7节全文总结。
2.Problem Formalization
2.1 Notation and Definition
本文中使用到的符号及其描述如表1所示:

简单介绍下: 带有节点集和边集的图
G
=
(
V
,
E
)
G=(V,E)
G=(V,E),子图
G
^
\hat{G}
G^,邻接矩阵
A
A
A,
f
v
f_v
fv和
f
e
f_e
fe分别表示节点和边的类型,
N
k
(
v
i
)
N_k(v_i)
Nk(vi)表示节点
v
i
v_i
vi的
K
K
K个最近邻结点,特征矩阵X(每一行表示一个节点的N维特征表示),嵌入方式
y
y
y,知识图三元组
<
h
,
r
,
t
>
<h,r,t>
<h,r,t>(头实体、关系和尾实体),节点
v
i
v_i
vi和
v
j
v_j
vj间的一阶邻近度
s
i
j
(
1
)
s_{ij}^{(1)}
sij(1)和二阶邻近度
s
i
j
(
2
)
s_{ij}^{(2)}
sij(2),级联
c
c
c。
有些概念没听说过,不过后文会有介绍!
一些定义:


这些定义上面已经叙述过了。
对于知识图三元组:
<
h
,
r
,
t
>
<h,r,t>
<h,r,t>(头实体、关系和尾实体),
h
h
h和
r
r
r都表示一个节点,
r
r
r表示边。比如在图3中:

上图有两个三元组:
<
A
l
i
c
e
,
i
s
F
r
i
e
n
d
O
f
,
B
o
b
>
<Alice,isFriendOf,Bob>
<Alice,isFriendOf,Bob>和
<
B
o
b
,
i
s
S
u
p
e
r
v
i
s
o
r
O
f
,
C
h
r
i
s
>
<Bob,isSupervisorOf,Chris>
<Bob,isSupervisorOf,Chris>,监护人和朋友是他们之间的关系。


一个前提:如果两个节点由一条权重较大的边连接,则它们很相似。
- 一阶邻近度 s i j ( 1 ) s_{ij}^{(1)} sij(1):边的权值即两个节点的一阶邻近度,若没有边则一阶邻近度为0。定义 s i ( 1 ) s_i^{(1)} si(1)表示节点 i i i与其他所有节点的邻近度向量,比如对于上图的节点1就有: s 1 ( 1 ) = [ 0 , 1.2 , 1.5 , 0 , 0 , 0 , 0 , 0 , 0 ] s_1^{(1)}=[0,1.2,1.5,0,0,0,0,0,0] s1(1)=[0,1.2,1.5,0,0,0,0,0,0]
- 二阶邻近度
s
i
j
(
2
)
s_{ij}^{(2)}
sij(2):定义如下:


节点 i i i和节点 j j j的二阶邻近度为: s i j ( 2 ) = c o s i n e ( s i ( 1 ) , s j ( 1 ) ) s_{ij}^{(2)}=cosine(s_i^{(1)},s_j^{(1)}) sij(2)=cosine(si(1),sj(1))。同理可以推出三阶邻近度、四阶邻近度等。
图嵌入问题的定义:

简单来说就是将图G的一部分表示为
d
d
d维向量(可以是节点表示为向量,边表示为向量或者子图表示为向量)。
3.Problem Settings Of Graph Embedding
本节从问题设置的角度比较了现有的图嵌入工作,问题设置包括嵌入输入和嵌入输出。
3.1 Graph Embedding Input
图嵌入的输入是一个图。在本研究中,将图嵌入输入分为四类:同质图、异质图、信息图和非显式图。
3.1.1 Homogeneous Graph
同质图的定义如下:

同质图中,node和edge的类型只有一种。比如社交网络中只存在一种节点类型:用户节点和一种边类型:用户-用户边类型。 同质图进一步分为加权(或有向)图和非加权(或无向)图,如下所示:

无向无权同质图是最基本的一种图,其只有图的基本结构信息能够使用。 与之对应地,有向图往往能提供更多的信息,比如上图a中的
v
2
v_2
v2相比于
v
3
v_3
v3应该嵌入到更靠近
v
1
v_1
v1的位置,因为
e
12
e_{12}
e12边的权重更大。
由于同质图中只有结构信息,因此同质图嵌入的挑战在于如何在嵌入时保留这些连通模式。
3.1.2 Heterogeneous Graph
异质图与同质图相反:图中节点和边的类型不止一种。这么说起来可能有一点抽象,借助应用场景来说明:
- 基于社区的问答(cQA)站点:用户可以在互联网上发布问题,其他人可以回答问题。那么在cQA图中就有了不同类型的节点:问题、答案、用户。现有的cQA图嵌入算法的区分如下:

可以看到这些图嵌入算法主要是依据link来区分的。 - 多媒体网络:同样有不同类型的节点,比如图片、文本和视频等。
- 知识图:前面有提到过,实体的类型可以是导演、演员和电影等,关系可以是产生、监制等。
异质图嵌入的挑战:如何探索不同类型对象之间的全局一致性。
3.1.3 Graph with Auxiliary Information
辅助信息就是除了图结构信息(node和edge)之外的其他信息,包括以下几种:

- label:节点或者边的类别信息。
- attribute:与标签不同,属性值既可以是离散的,也可以是连续的。
- node feature:大多数节点特征是文本,节点特征通过提供丰富的非结构化信息增强了图嵌入性能。
- information propagation:信息传播的一个例子就是Twitter中的“retweet”。
- knowledge base:流行的知识库包括Wikipedia、Freebase、YAGO、DBpedia等。
信息图嵌入的难点:如何整合丰富的非结构化信息,使得的学习到的嵌入既能代表拓扑结构,又能区分辅助信息。
3.1.4 Graph Constructed from Non-Relational Data
从非关系数据构造的图,一般称作非显式图(在其它地方看到是这么叫的)。非显式图是指数据之间没有显式地定义出关系,需要依据某种规则或计算方式将数据的关系表达出来,进而将数据当成一种图数据进行研究。
非显式图嵌入的难点:如何计算非关系数据之间的关系并构造图。在构建图之后,与其他输入图的挑战相同,即如何在嵌入空间中保持所构建图的节点邻近性。
总结: 3.1节介绍了四种图:同质图、异质图、属性图和非显式图。
3.2 Graph Embedding Output
图嵌入的输入是一个图,输出是一组表示图(部分)的低维向量。 根据输出粒度,将图嵌入输出分为节点嵌入、边缘嵌入、混合嵌入和全图嵌入四类。
3.2.1 Node Embedding
节点嵌入,顾名思义,输出的是每一个节点的向量表示。图中邻近度较高的节点被嵌入到一起。不同嵌入方法的区别在于如何定义两个节点之间的“邻近度”。一阶邻近度(定义5)和二阶邻近度(定义6)是两种常用的节点邻近度计算指标。
节点嵌入的难点:如何在不同类型的图中定义节点的邻近度?
3.2.2 Edge Embedding
边缘嵌入,顾名思义,输出的是每条边的低维向量表示。应用场景主要是判断两个节点间是否存在边。
边缘嵌入难点:如何定义边的邻近度?如果边是有方向的,这种不对称性质怎么表示?
3.2.3 Hybrid Embedding
混合嵌入:将边和节点(子结构)嵌入到一起,或者节点和社区嵌入到一起。子图嵌入:比如在两个很遥远的节点之间嵌入图结构,以支持语义接近搜索。
子结构或社区的嵌入也可以通过聚合单个节点和嵌入其中的边来得到。 节点嵌入和社区嵌入可以相互促进。通过引入社区感知的高阶邻近度,可以学习到更好的节点嵌入,而当生成更精确的节点嵌入时,可以检测到更好的社区。
难点:如何生成目标子结构?如何将不同类型的图进行嵌入?
3.2.4 Whole-Graph Embedding
全图嵌入,顾名思义,输出的是一个图的低维向量表示。比如蛋白质图、分子图等。
全图嵌入为图分类任务提供了一个简单而有效的方法(得到其向量表示后就能进行分类)。
难点:如何捕获整个图的属性?以及如何在表现力和效率之间进行权衡?所谓表现力是指向量能够表示这个图信息的能力,但如果想要完整表达图的所有信息,可能计算量是比较大的。
总结: 3.2节总结了图嵌入的输出类型,共4类:节点嵌入、边缘嵌入、混合嵌入以及全图嵌入。
4.Graph Embedding Techniques
第4节主要讲述图嵌入技术,算是一个重点。
4.1 Matrix Factorization
第一种图嵌入技术是矩阵分解。
基于矩阵分解的图嵌入将图的属性(如节点两两相似性)以矩阵的形式表示出来,然后对该矩阵进行分解得到节点嵌入。
一般对非显示图采用这种图嵌入技术,这点从非显式图的定义就可以看出来。
基于矩阵分解的图嵌入有两种类型:一种是对拉普拉斯特征映射进行因子分解,另一种是直接对节点的邻近矩阵进行因子分解。
4.1.1 Graph Laplacian Eigenmaps
第一种是对拉普拉斯特征映射进行因子分解,拉普拉斯特征映射是一种不太常见的降维算法。
主要思想:如果两个数据实例i和j很相似,那么i和j在降维后的目标子空间中应该尽量接近。 设数据实例的数目为n,最终降维目标的维度为m。定义n×m大小的矩阵Y,其中每一个行向量是一个数据实例在目标m维子空间中的向量表示。我们的目的是让相似的数据样例i和j在降维后的目标子空间里仍旧尽量接近,故目标函数如下:

其中W是邻近矩阵。现有不同方法的差异主要在于如何定义节点间两两邻近度
w
i
j
w_{ij}
wij。对邻近度的定义一般有这些:

不再一一赘述!
4.1.2 Node Proximity Matrix Factorization
对节点的邻近矩阵进行分解:

W
W
W是节点的邻近矩阵,
Y
Y
Y中每一行表示一个节点的嵌入表示,
Y
c
Y^c
Yc表示上下文节点的嵌入表示。
4.2 Deep Learning
基于深度学习技术的图嵌入,前面已经讲过一篇相关的文章:KDD2016 | node2vec:Scalable Feature Learning for Networks
此技术下的输入要么是从图中采样的路径(比如node2vec、Line和DeepWalk),要么是整个图本身。因此,将基于DL的图嵌入分为两类:采用随机漫步和不采用随机漫步。
4.2.1 DL Based Graph Embedding with Random Walk
第一种是采用随机漫步的DL图嵌入技术。即我们需要找到一个节点的邻域表示,然后再利用深度学习技术得到其向量表示。
常见的有DeepWalk(基于Skip-Gram)、Line以及node2vec,这里不再细讲了。
看一下前面讲的node2vec的算法流程:

得到每个节点的r条采样路径后,就能利用SGD方法得到每一个节点的向量表示。
常见的基于DL的随机漫步图嵌入技术有以下几种:

4.2.2 DL Based Graph Embedding without Random Walk
第二种就是不进行随机漫步:直接将深度学习模型应用于整幅图(或整幅图的邻近矩阵)。
常见的模型如下表所示:

4.3 Edge Reconstruction Based Optimization
第三种是基于边缘重构的优化技术。主要思想是通过最大化边缘重构概率或最小化边缘重构损失来建立节点的嵌入表示。
即有一个大前提:基于节点嵌入建立的边应尽可能与原图中的边相似。
4.3.1 Maximizing Edge Reconstruction Probability
优化方法的第一种:最大化边缘重构概率。
好的节点嵌入应该能够在原始输入图中重建边,即好的节点嵌入最大化了在图中观察到的边的生成概率。
节点对
v
i
v_i
vi和
v
j
v_j
vj之间的直接边表示它们的一阶邻近度(前面有讲),可以计算为联合使用
v
i
v_i
vi和
v
j
v_j
vj嵌入的概率:

上述一阶邻近度存在于图中的任何一对连接节点之间。 为了学习嵌入,我们最大化在图中观察这些近似度的对数似然函数,因此 目标函数定义为:
同理可得二阶邻近度:

它可以被解释为在图中随机游走的概率,它开始于
v
i
v_i
vi结束于
v
j
v_j
vj。 因此图嵌入目标函数是:

其中
P
P
P是采样的路径集合(始于
v
i
v_i
vi结束于
v
j
v_j
vj)。
4.3.2 Minimizing Distance-Based Loss
除了最大化边缘重构概率外,还可以最小化距离损失。
核心:基于节点嵌入计算的节点邻近度,应尽可能接近基于观察到的边计算的节点邻近度。
具体来说,可以基于节点嵌入来计算节点邻近度,或者可以基于观察到的边凭经验来计算节点邻近度,然后最小化两种类型的邻近度之间的差异。
对于一阶邻近度:
基于经验计算得到的一阶邻近度为:

其中
A
i
j
A_{ij}
Aij是两个节点间边的权值。
具体的一阶邻近度的计算方法前文已经提到,就是边权重
A
i
j
A_{ij}
Aij。因此,现在我们要最小化二者的差异:

上述目标函数使用了KL散度来衡量差异,并且最小化这个差异。
对于二阶邻近度:
基于经验计算得到的二阶邻近度为:

d
i
d_i
di的表达式为:

即节点的出度。
同样最小化KL散度描述的差异:

表8对现有的基于边重建的图嵌入算法进行了总结:

4.3.3 Minimizing Margin-Based Ranking Loss
第三种方式为最小化基于边距的排名损失。
这里的边是指节点对之间的相关性。
因此这种方式的大前提是:节点的嵌入更类似于相关节点的嵌入,而不是任何其他不相关节点的嵌入。
令
s
(
v
i
,
v
j
)
s(v_i,v_j)
s(vi,vj)表示两个节点的相似性得分,
V
i
+
V_i^+
Vi+表示与
v
i
v_i
vi相关的节点集合,
V
i
−
V_i^-
Vi−表示与之不相关的节点集合。则基于边距的排名损失定义为:

其中
γ
\gamma
γ是边距。减小排名损失,就可以加大
s
(
v
i
,
v
i
+
)
s(v_i,v_i^+)
s(vi,vi+)和
s
(
v
i
,
v
i
−
)
s(v_i,v_i^-)
s(vi,vi−)的差值,从而保证
v
i
v_i
vi的嵌入更接近其相关节点而不是任何其他不相关节点。
大多数现有知识图嵌入算法采用了此方法。
下表总结了基于边距排名损失的知识图嵌入算法:

4.4 Graph Kernel
前面讲到的三种图嵌入技术分别为:矩阵分解、深度学习和基于边重建的优化,第四种图嵌入技术为图核。
整个图结构可以表示为一个向量,包含从中分解的基本子结构的数量。
图核将每个图表示为向量,并且使用两个向量的内积来比较两个图。 图核中通常定义了三种类型的“原子”子结构:
- Graphlet:一个大小为K的感应的和非同构子图。
- Subtree Patterns:子树模式。
- Random Walks:随机漫步。
总结:图核是专为整图嵌入而设计的,因为它捕获了整图的全局属性。输入图的类型通常是同质图或者信息图。
4.5 Generative Model
第五种图嵌入技术是生成模型。
生成模型可以通过规定输入特征和类标签的联合分布来定义,它以一组参数为条件。 比如Latent Dirichlet Allocation(LDA)。
4.6 Hybrid Techniques and Others
混合技术就是结合前面提到的多项技术。比如通过最小化基于边的排序损失来学习基于边的嵌入,并通过矩阵分解来学习基于属性的嵌入。又比如优化基于边距的排名损失,并且将基于矩阵分解的损失作为正则化项。
除了前面提到的五种技术,还有一些其他技术,这里不细述了。
4.7 Summary
表10总结并比较了前面提到的五种图嵌入技术:

原文描述较多,做出以下简要总结:
- 矩阵分解:分为拉普拉斯特征映射和节点邻近矩阵分解。它们的缺点是巨大的时间和空间开销,不能扩展。
- 深度学习:分为带随机游走的和不带随机游走的。带随机游走的如node2vec、Line和Deepwalk,不带随机游走的如GCN ,struc2vec和GraphSAGE。带随机游走的DL可以通过图上的采样路径来自动利用邻域结构,它通常观测同一路径中的节点的局部邻居,从而忽略全局结构信息,另外我们很难找到最优采样策略,因为嵌入和路径采样不是在统一框架中联合优化的。 不带随机游走的DL。计算成本往往很大,我们知道传统的深度学习架构假设输入数据在1D或2D网格上,从而就能利用GPU来进行加速 。 然而,图没有这样的网格结构,因此需要不同的解决方案来提高效率。
- 基于边重建的图嵌入:核心思想是基于节点嵌入建立的边应尽可能与原图中的边相似。与前两类图嵌入相比,它更有效。 然而,使用直接观察到的局部信息来训练所获得的嵌入缺乏对全局图结构的认知。
- 图核:将图转换为单个向量,以便于图级别的分析任务,例如图分类。图核比其他类别的技术更有效,因为它只需要在图中枚举所需的原子子结构。 但是它有两个局限:首先,子结构不是独立的; 其次,当子结构的大小增加时,嵌入维度通常呈指数增长,这会导致嵌入中的稀疏问题。
- 生成模型:可以很好地通过统一模型来利用来自不同源(例如,图结构,节点属性)的信息。直接将图嵌入到潜在语义空间中,会生成可以使用语义解释的嵌入。缺点:生成模型需要大量的训练数据来估计适合数据的适当模型。因此,它可能不适用于小图或少量图。
5.Applications
在本节中,将图嵌入的应用场景分为节点相关、边缘相关和图相关。
5.1 Node Related Applications
第一类应用场景跟节点有关。
5.1.1 Node Classification
节点应用的第一种就是最常见的节点分类。
核心思想:相似的节点具有相同的标签。我们在标记节点嵌入表示集合中训练出一个分类器,然后就能进行节点分类。
5.1.2 Node Clustering
第二种节点应用是节点聚类,这一点在KDD2016 | node2vec:Scalable Feature Learning for Networks中有提到。
节点聚类,简而言之就是将相似的节点分在一起,通常直接对得到的节点嵌入向量应用传统聚类算法即可。
5.1.3 Node Recommendation/Retrieval/Ranking
相比于前两种比较常见的应用,我对节点的推荐/检索/排序更感兴趣。
- 节点推荐:根据某些标准(如相似度)将最感兴趣的K个节点推荐给给定的节点。这个在日常生活中很常见,比如淘宝的商品推荐,抖音的好友推荐等等。
- 节点检索:例如基于关键字的图像/视频搜索。
- 节点排序:对某一节点的特定节点集合进行排序,比如对某一用户的同学进行排序。
5.2 Edge Related Applications
第二大类是边相关的应用场景。
5.2.1 Link Prediction
最容易想到的肯定是链接预测。比如在社交网络中预测两个用户是否可能相互认识。
5.2.2 Triple Classification
第二种应用场景是三重分类,这个主要是应用在知识图中的。Triple Classification就是来预测三元组中头部和尾部的关系是否正确,比如老子是孔子的老师这一关系是否正确。
5.3 Graph Related Applications
第三大类是图相关的应用场景。
5.3.1 Graph Classification
第一种是图分类。比如每个图是一个化合物,一个有机分子或一个蛋白质结构,然后我们对每一个图进行全图嵌入得到其特征表示,然后求它们的相似度来进行分类。
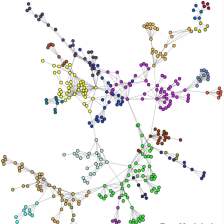
5.3.2 Visualization
第二种是图可视化:将图中所有的节点都嵌入到二维向量中,然后用不同的颜色表示节点的类别进行画图。从图中可以看出属于同一类别的节点是否嵌入得更近。
6.Future Directions
本节总结了图嵌入领域未来的四个研究方向:
- Computation:前面提到“传统的深度学习架构假设输入数据在1D或2D网格上,从而就能利用GPU加速 。 然而,图没有这样的网格结构,因此需要不同的解决方案来提高效率。”因此,如何提高计算效率是一个比较重要的研究方向。
- Problem settings:图并不总是静态的,例如Twitter中的社交网络,DBLP中的引用图等等。所谓动态图:比如随着时间推移,某些边/节点消失了,又或者出现了新的节点/边。因此,这是一个比较新的研究方向。
- Techniques:DL是现在比较常用的图嵌入技术,如何设计基于非深度学习的方法来进行一个比较充分的嵌入是一个比较好的研究方向。
- Applications:除了第5节中讲的三种应用场景外,我们是否能利用图嵌入来解决其他问题呢?
7. Conclusions
本文对图嵌入进行了全面的回顾:
- 第2节给出了图嵌入问题的形式化定义,并引入了一些基本概念。
- 第3节和第4节提出了图嵌入的两种分类方法:基于问题设置和基于嵌入技术。在问题设置分类方面,介绍了四种类型的嵌入输入和四种类型的嵌入输出,并总结了在每一种设置中所面临的挑战。在嵌入技术分类中,介绍了每一类嵌入技术并比较了它们的优缺点。
- 第5节总结了图嵌入的三种应用场景。
- 第6节探讨了未来图嵌入的四个研究方向:计算效率、问题设置、技术和应用场景。
















 2219
2219

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











