






在这篇文章中,我将向大家展示如何将预训练的大语言模型(LLM)打造成强大的文本分类器。
但为什么要专注于分类任务呢?首先,将预训练模型微调为分类器,是学习模型微调的一个简单且有效的入门方式。其次,在现实生活和商业场景中,许多挑战都围绕文本分类展开,比如垃圾邮件检测、情感分析、客户反馈分类、主题标注等。
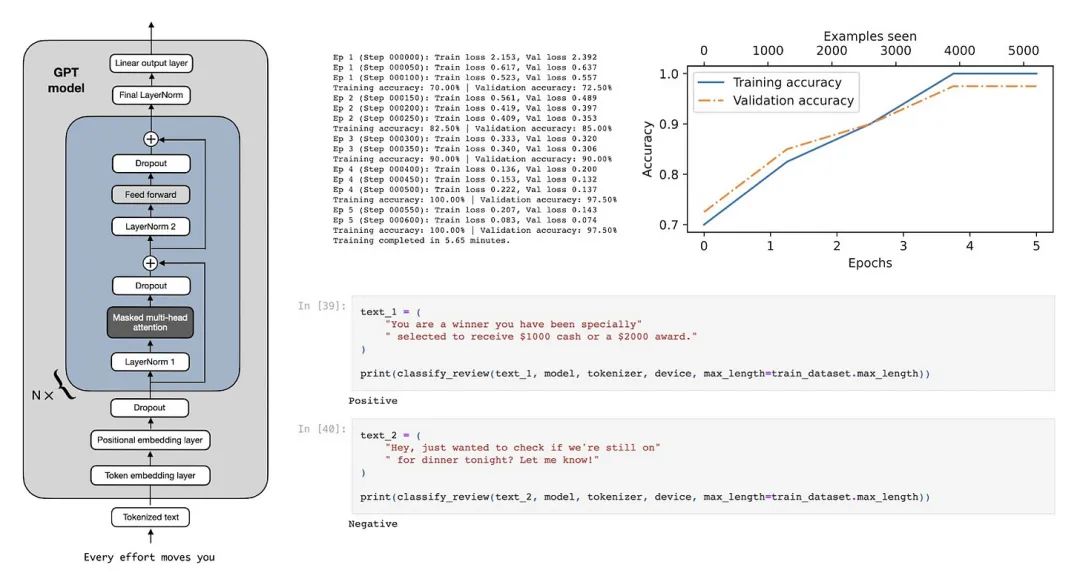
将 GPT 模型转变为文本分类器
我的新书发布!
我非常激动地宣布,我的新书《Build a Large Language Model From Scratch》已经由 Manning 出版社正式发布,中文版也很快要跟大家见面(预计2月底)。

在我的经验中,理解一个概念最深刻的方式就是从零开始构建它。这本书耗时近两年打磨,在书中我将带着你从头开始构建一个类似 GPT 的大语言模型,包括实现数据输入以及使用指令数据进行微调。我的目标是,在读完这本书之后,你能够深入、全面地了解 LLM 的工作原理。
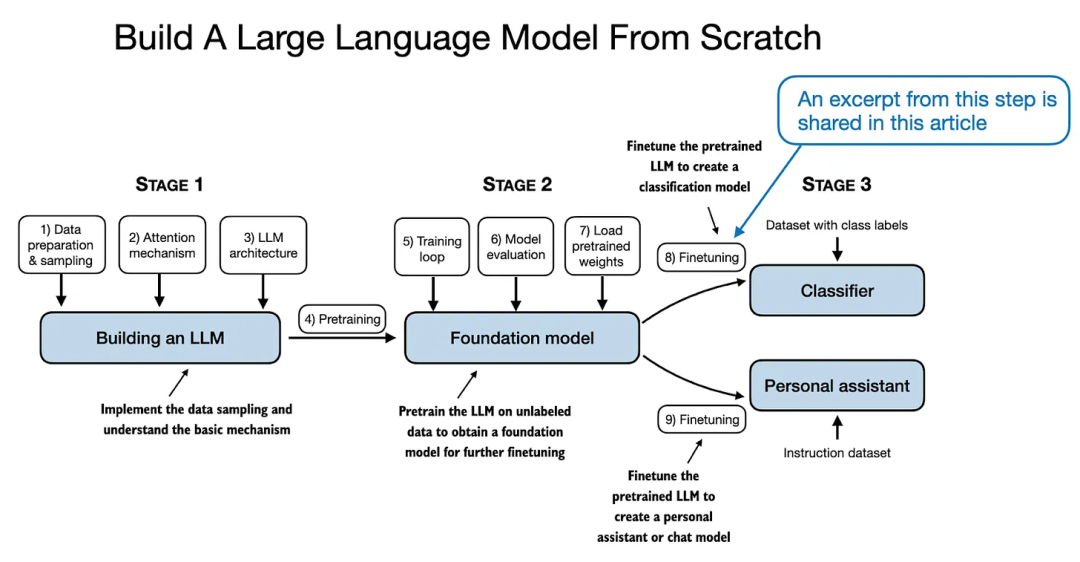
本文主要内容
为了庆祝新书发布,我将分享书中一个章节的节选,带你一步步完成如何微调预训练 LLM,使其成为一个垃圾邮件分类器。
重要提示
书中关于分类任务微调的章节共有 35 页,内容较多,不适合一次性在文章中全部呈现。因此,本篇文章将聚焦于其中约 10 页的核心内容,帮助你了解分类微调的背景和核心概念。
此外,我还会分享一些书中未涉及的其他实验见解,并解答读者可能提出的常见问题。(需要注意的是,以下节选基于我的个人草稿,尚未经过 Manning 的专业编辑或最终设计。)
文章完整代码可以在https://github.com/rasbt/LLMs-from-scratch/blob/main/ch06/01_main-chapter-code/ch06.ipynb 中找到。
7 个关于训练 LLM 分类器的常见问题
-
我们需要训练所有层吗?
-
为什么选择微调最后一个 token,而不是第一个?
-
BERT 和 GPT 在性能上有何区别?
-
我们是否应该禁用因果掩码(causal mask)?
-
增大模型规模会带来什么影响?
-
使用 LoRA(低秩适配)能带来哪些改进?
-
是否需要填充(padding)?
祝阅读愉快!
微调的不同类型
微调语言模型最常见的方式包括指令微调(instruction finetuning)和分类微调(classification finetuning)。
指令微调的核心是通过一组任务对语言模型进行训练,并使用具体的指令来提升模型理解和执行自然语言提示中任务的能力。下图(图 1)展示了这一过程的基本原理。
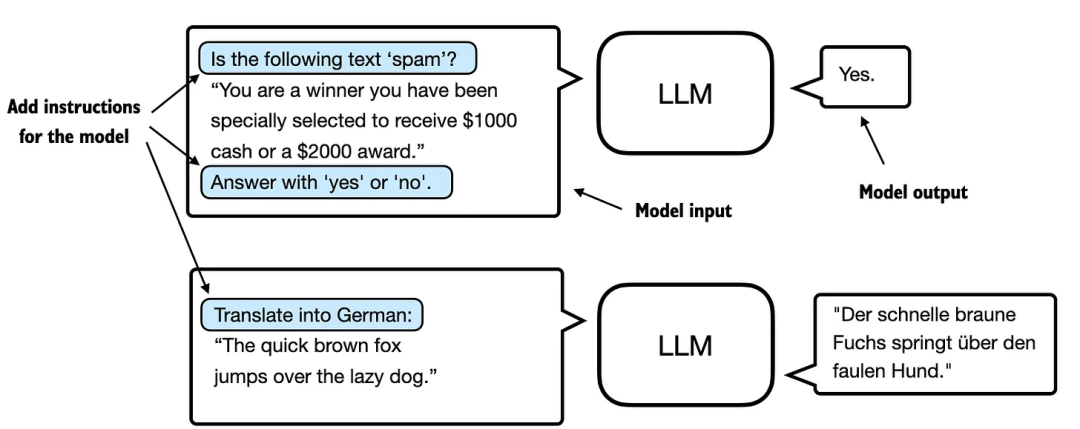
图 1:两种不同指令微调场景的说明。上方的模型任务是判断给定文本是否为垃圾邮件,下方的模型则被赋予将英文句子翻译成德语的指令。
下一章将讨论图 1 中所示的指令微调内容。而本章则聚焦于分类微调,这个概念如果你有机器学习的背景,可能已经有所了解。
在分类微调中,模型被训练来识别一组特定的类别标签,例如“垃圾邮件”和“非垃圾邮件”。分类任务不仅限于大语言模型和电子邮件过滤,还包括从图像中识别不同植物种类、将新闻文章分类为体育、政治或科技等主题,以及在医学影像中区分良性和恶性肿瘤等。
重点在于,经过分类微调的模型只能预测它在训练中遇到过的类别。例如,它可以判断某件事物是否是“垃圾邮件”或“非垃圾邮件”,如图 2 所示,但除此之外无法对输入文本作出其他判断。
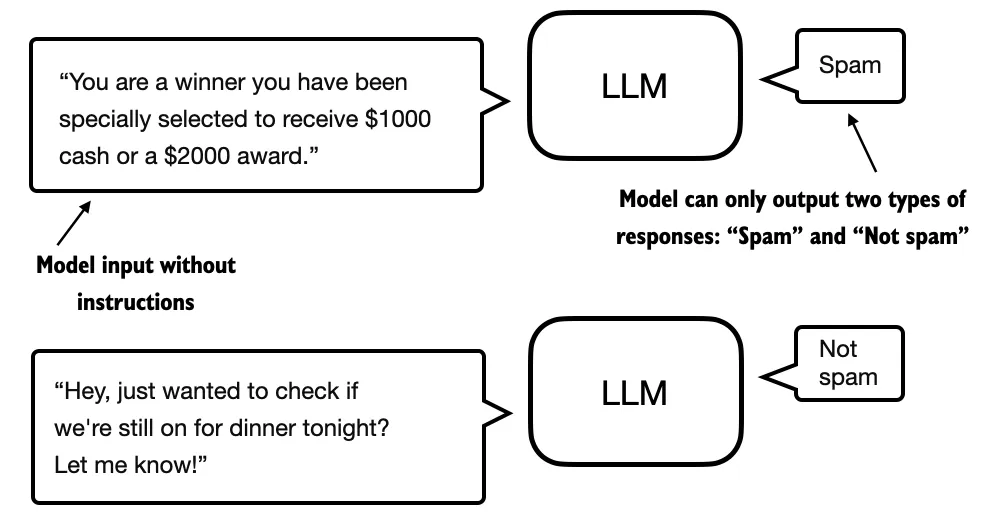
图 2:使用 LLM 进行文本分类场景的说明。一个针对垃圾邮件分类微调的模型不需要额外的指令来处理输入。然而,与指令微调模型相比,它只能给出“垃圾邮件”和“非垃圾邮件”的回应。
与图 2 所示的分类微调模型相比,指令微调模型通常能够承担更广泛的任务。我们可以将分类微调模型看作是高度专业化的模型,而开发一个能很好地处理多种任务的通用模型通常比开发一个专门模型更具挑战性。
选择合适的方法
指令微调提高了模型根据用户特定指令理解和生成回应的能力。它更适合需要根据复杂用户指令处理各种任务的模型,从而提高模型的灵活性和交互质量。而分类微调则适用于需要将数据精确分类为预定义类别的项目,例如情感分析或垃圾邮件检测。
尽管指令微调用途更广,但它需要更大的数据集和更多的计算资源来开发擅长多种任务的模型。而分类微调则需要较少的数据和计算资源,但其用途仅限于模型训练时涉及的特定类别。
使用预训练权重初始化模型
由于这是一个节选,我们将跳过数据准备和模型初始化的部分,这些内容已经在前几章中进行了实施和预训练。根据我的经验,与纸质书相比,阅读较长的数字文章时保持专注可能会更具挑战性。因此,我会尽量让这部分节选内容紧紧围绕本章的关键要点。
为了给这部分节选提供一些背景信息,这段内容主要聚焦于将一个通用的预训练大语言模型转变为专门用于分类任务的模型所需的修改,如图 3 所示。
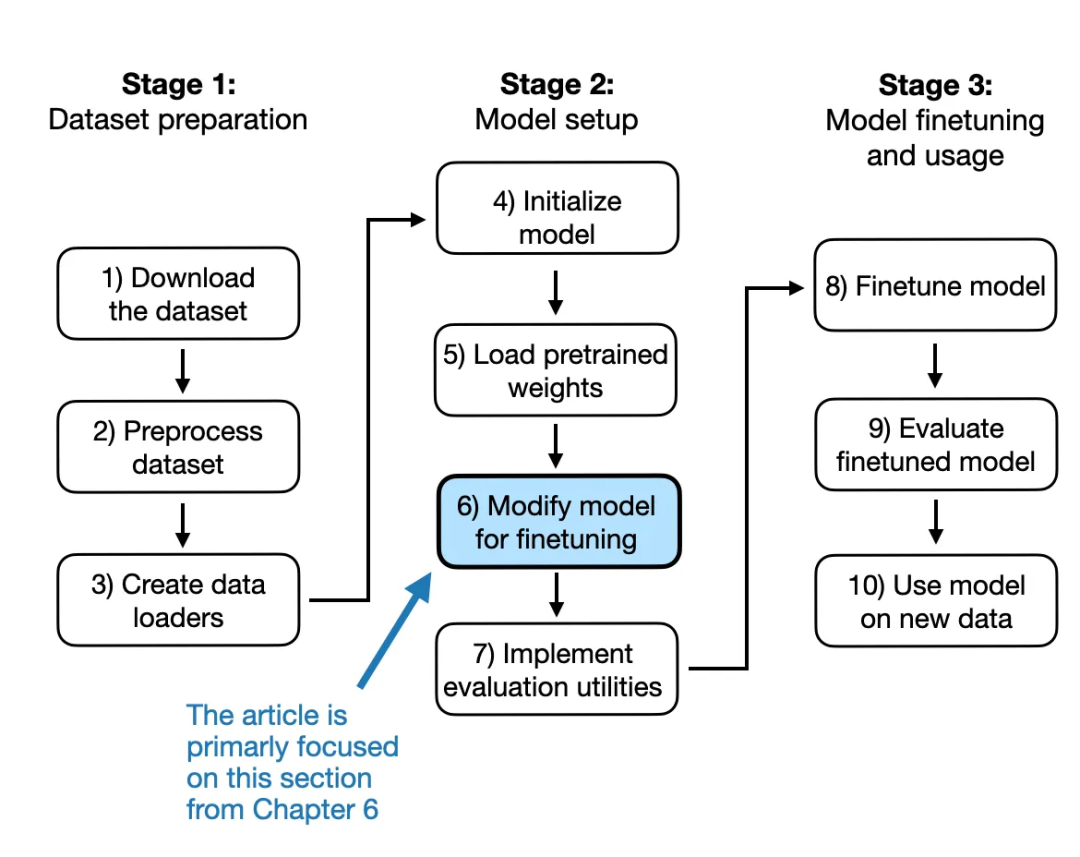
图 3:在这部分节选中,我们跳过步骤 1-5,直接进入第 6 步(从下一节开始)。
但在进行图 3 中提到的 LLM 修改之前,我们先简要了解一下我们正在使用的预训练 LLM。
为了简化讨论,我们假设已经设置好加载模型的代码,流程如下:
model = GPTModel(BASE_CONFIG)
load_weights_into_gpt(model, params)
model.eval()
在将模型权重加载到 GPTModel 后,我们使用前几章中的文本生成工具函数,确保模型能够生成连贯的文本:
from chapter04 import generate_text_simple
from chapter05 import text_to_token_ids, token_ids_to_text
text_1 = "Every effort moves you"
token_ids = generate_text_simple(
model=model,
idx=text_to_token_ids(text_1, tokenizer),
max_new_tokens=15,
context_size=BASE_CONFIG["context_length"]
)
print(token_ids_to_text(token_ids, tokenizer))
从以下输出中可以看出,模型生成了连贯的文本,这表明模型权重已正确加载:
Every effort moves you forward.
The first step is to understand the importance of your work
现在,在开始将模型微调为垃圾邮件分类器之前,我们先试试通过提示给出指令,看看模型是否已经可以将垃圾邮件进行分类:
text_2 = (
"Is the following text 'spam'? Answer with 'yes' or 'no':"
" 'You are a winner you have been specially"
" selected to receive $1000 cash or a $2000 award.'"
)
token_ids = generate_text_simple(
model=model,
idx=text_to_token_ids(text_2, tokenizer),
max_new_tokens=23,
context_size=BASE_CONFIG["context_length"]
)
print(token_ids_to_text(token_ids, tokenizer))
模型输出如下:
Is the following text 'spam'? Answer with 'yes' or 'no': 'You are a winner you have been specially selected to receive $1000 cash or a $2000 award.'
The following text 'spam'? Answer with 'yes' or 'no': 'You are a winner
根据输出可以明显看出,模型在执行指令时存在困难。
这是预料之中的,因为模型仅经过预训练,并未进行指令微调,我们将在接下来的章节中探讨这一点。
下一节将为分类微调准备模型。
添加分类头
在本节中,我们将修改预训练的大语言模型,为分类微调做好准备。具体来说,我们将原始输出层(将隐藏表示映射到包含 50,257 个唯一 token 的词汇表)替换为一个较小的输出层,该输出层将隐藏表示映射到两个类别:0(“非垃圾邮件”)和 1(“垃圾邮件”),如图 4 所示。
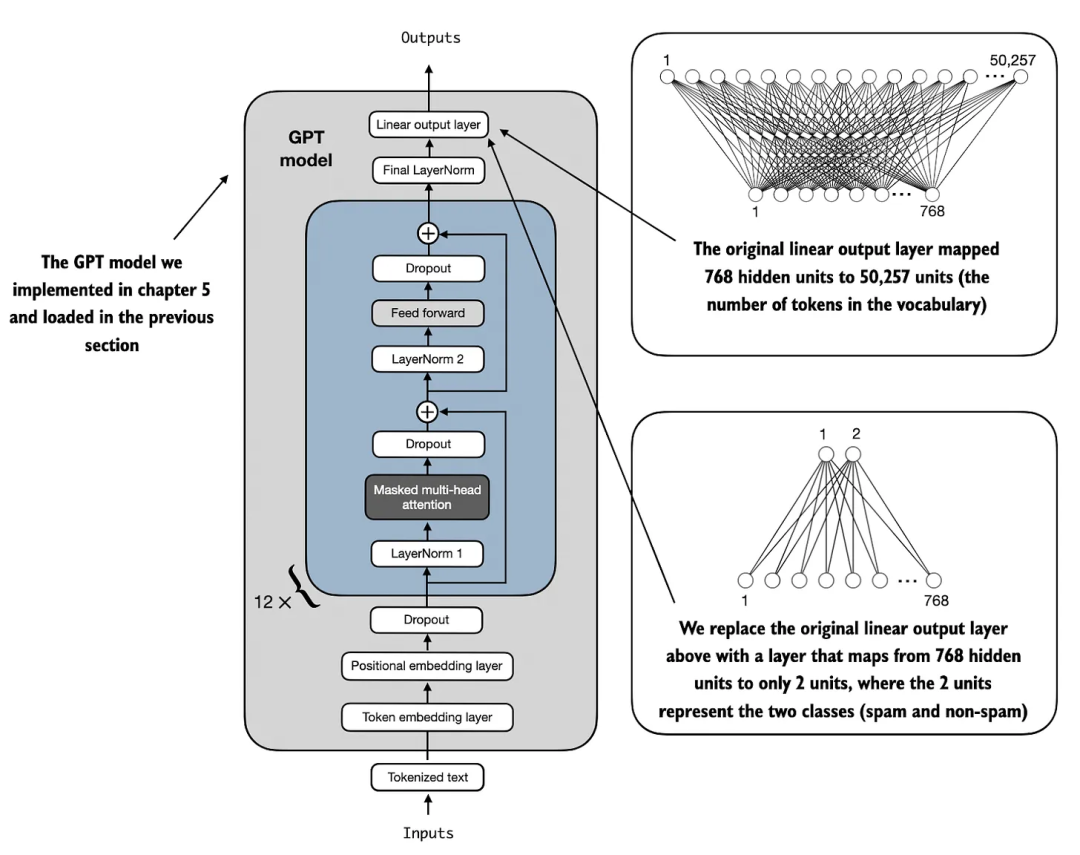
图 4 展示了通过修改架构将 GPT 模型适配为垃圾邮件分类器。最初,模型的线性输出层将 768 个隐藏单元映射到包含 50,257 个 token 的词汇表中。而在垃圾邮件检测任务中,这个输出层被替换为新的输出层,将相同的 768 个隐藏单元映射到两个类别,分别代表“垃圾邮件”和“非垃圾邮件”。
如上图 4 所示,除了替换输出层外,我们使用的模型与前几章中的相同。
输出层节点
由于我们处理的是一个二分类任务,技术上我们可以只使用一个输出节点。然而,这需要修改损失函数,这部分内容已在附录 B 的参考文献中讨论过。因此,我们选择了一种更通用的方法,即输出节点的数量与类别数量相匹配。例如,对于一个三分类问题,如将新闻文章分类为“科技”、“体育”或“政治”,我们将使用三个输出节点,以此类推。
在尝试图 4 所示的修改之前,我们通过 print(model) 打印模型架构,输出如下:
GPTModel(
(tok_emb): Embedding(50257, 768)
(pos_emb): Embedding(1024, 768)
(drop_emb): Dropout(p=0.0, inplace=False)
(trf_blocks): Sequential(
...
(11): TransformerBlock(
(att): MultiHeadAttention(
(W_query): Linear(in_features=768, out_features=768, bias=True)
(W_key): Linear(in_features=768, out_features=768, bias=True)
(W_value): Linear(in_features=768, out_features=768, bias=True)
(out_proj): Linear(in_features=768, out_features=768, bias=True)
(dropout): Dropout(p=0.0, inplace=False)
)
(ff): FeedForward(
(layers): Sequential(
(0): Linear(in_features=768, out_features=3072, bias=True)
(1): GELU()
(2): Linear(in_features=3072, out_features=768, bias=True)
)
)
(norm1): LayerNorm()
(norm2): LayerNorm()
(drop_resid): Dropout(p=0.0, inplace=False)
)
)
(final_norm): LayerNorm()
(out_head): Linear(in_features=768, out_features=50257, bias=False)
)
如上文所示,我们可以看到在第 4 章中实现的模型架构已经清晰地展示出来。如第 4 章所讨论的,GPTModel 由嵌入层、后续的 12 个相同的 Transformer 块(为简洁起见,仅展示了最后一个块)、一个最终的 LayerNorm 层,以及输出层 out_head 组成。
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 2835
2835

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









