






近期收到很多同学的私信,发现大家对LLM基础技术还是比较感兴趣,故根据我现在已有的知识,给大家整理一个脑图;主要梳理了基础技术篇的脑图,后续文章会继续给出开发、应用偏的脑图;辅助小伙伴们对LLM认知。
脑图下载地址:https://github.com/PulsarPioneers/llm-learn/blob/main/assets/llm-learn-base-mind.svg
1. LLM基础概念
1.1 定义与背景
什么是LLM:
基于深度学习的自然语言处理模型,具备生成、理解和处理文本能力。
发展历史
- 早期NLP:规则系统、统计模型(HMM、CRF)。
- Transformer时代:2017年《Attention is All You Need》。
- 规模化模型:GPT系列、BERT、T5等。
核心特点
- 大规模参数(亿级到万亿级)。
- 自监督学习(Pre-training + Fine-tuning)。
- 多任务适应性。
1.2 工作原理
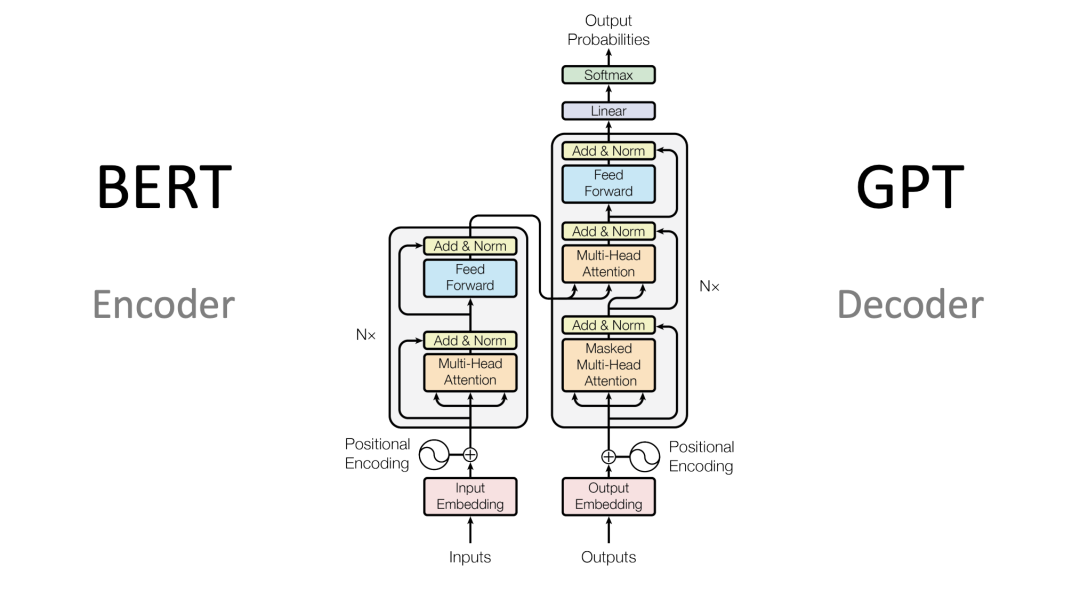
Transformer架构
- Encoder-Decoder结构(BERT vs GPT)。
- Attention机制:Self-Attention、Multi-Head Attention。
- Positional Encoding:处理序列顺序。
训练过程
- 预训练:大规模无标注文本(Common Crawl、Wikipedia)。
- 微调:针对特定任务(分类、生成)。
- 指令微调(Instruction Tuning):提升指令理解。
关键技术
- Tokenization:WordPiece、BPE。
- Embedding:Word、Position、Segment。
- Layer Normalization与残差连接。
2. LLM核心技术与算法
2.1 模型架构
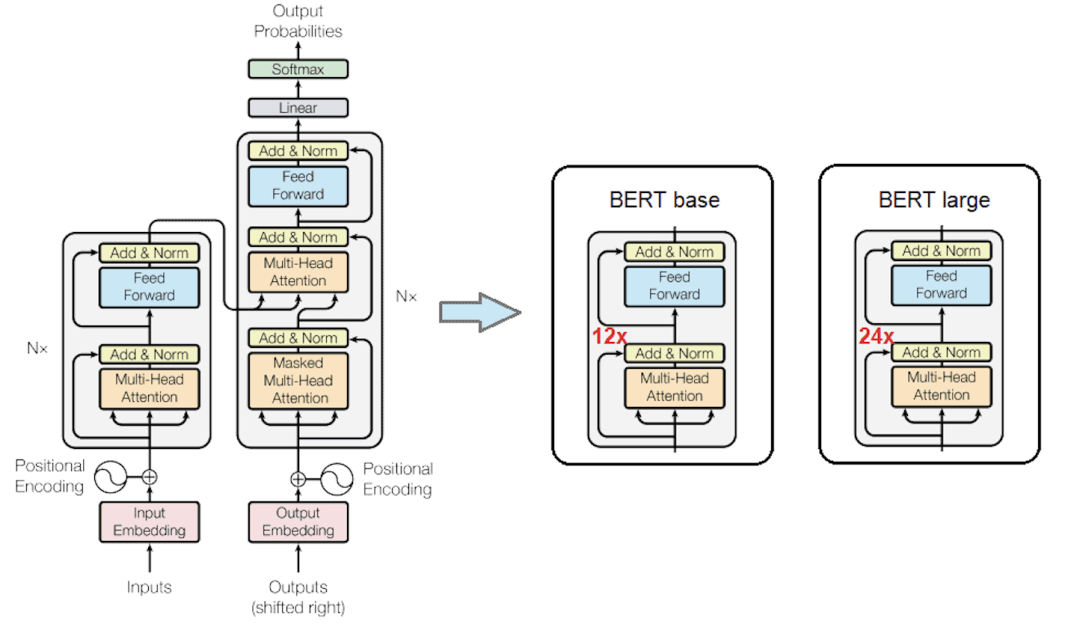
主流模型
- GPT:生成式,自回归。
- BERT:双向,掩码语言模型。
- T5:文本到文本框架。
- LLaMA:高效研究模型。
架构优化
- Sparse Attention:降低计算复杂度。
- Mixture of Experts(MoE):动态路由提升效率。
- FlashAttention:优化GPU内存使用。
2.2 训练与优化
数据处理
- 数据清洗与去重。
- 多语言与多模态数据。
优化算法
- Adam/AdamW:主流优化器。
- Learning Rate Schedule:Warm-up与衰减。
分布式训练
- 数据并行 vs 模型并行。
- Pipeline Parallelism与Tensor Parallelism。
- ZeRO(DeepSpeed):内存优化。
2.3 评估与指标
通用指标
- Perplexity:生成质量。
- BLEU/ROUGE:文本生成评估。
- F1/Accuracy:分类任务。
任务特定指标
- GLUE/SuperGLUE:NLP综合基准。
- MMLU:多任务语言理解。
- 人类评估
- 流畅性、相关性、一致性。
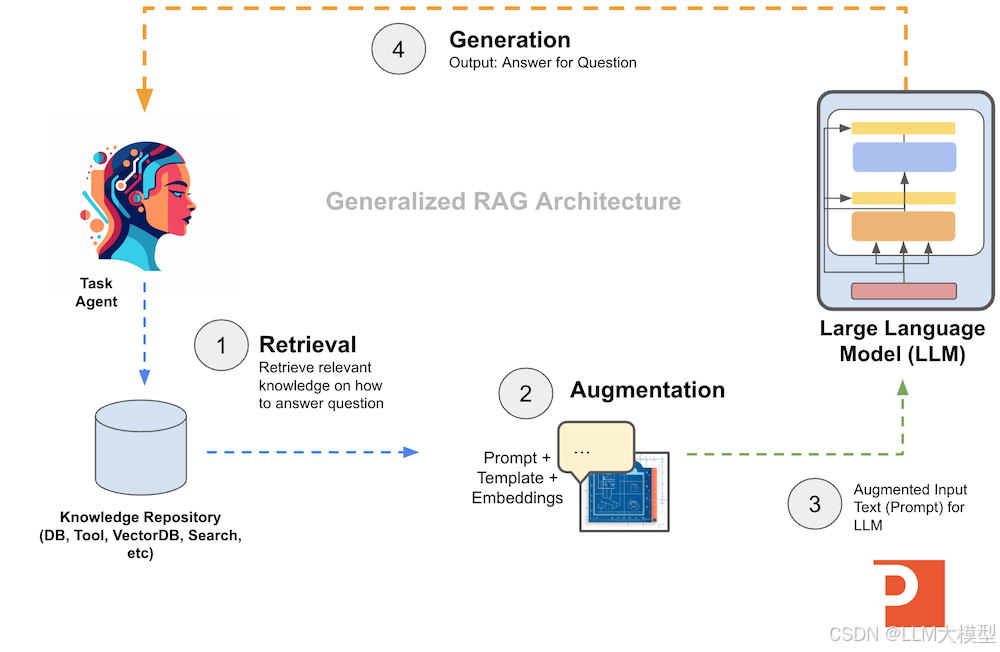
3. LLM应用场景
3.1 文本生成
应用案例
- 文章创作、故事生成。
- 代码生成(Copilot、CodeLLaMA、Cursor)。
- 对话系统(ChatGPT、Grok、 DeepSeek)。
挑战
- 事实性(Hallucination)。
- 上下文一致性。
3.2 文本理解
任务类型
- 情感分析、文本分类。
- 命名实体识别(NER)。
- 问答系统(QA)。
技术要点
- 上下文建模。
- 知识增强(Knowledge-Augmented Models)。
3.3 多模态与跨领域
多模态LLM
- 文本+图像:CLIP、DALL·E、Flamingo。
- 文本+音频:Whisper。
跨领域应用
- 医疗:临床记录分析。
- 法律:合同审查。
- 教育:自动批改、智能辅导。
4. LLM开发与部署
4.1 开发工具与框架

主流框架
- PyTorch/TensorFlow:模型开发。
- Hugging Face Transformers:预训练模型库。
- DeepSpeed/Megatron:分布式训练。
开发流程
- 数据准备与预处理。
- 模型选择与微调。
- 超参数调优。
4.2 部署与优化
部署方式
- 云端API(OpenAI、DeepSeek)。
- 本地部署(ONNX、Triton、Ollama)。
优化技术
- 量化(Quantization):INT8、FP16。
- 剪枝(Pruning):减少冗余参数。
- 蒸馏(Distillation):小模型继承大模型能力。
硬件加速
- GPU/TPU:主流训练硬件。
- Inference优化:NVIDIA TensorRT。
4.3 开源与生态
开源模型
- LLaMA、Mistral、Grok(部分开源)。
- Hugging Face社区模型。
数据集
- The Pile、C4、RedPajama。
社区与工具
- GitHub、Kaggle。
- Weights & Biases:实验跟踪。
5. LLM挑战与未来
5.1 技术挑战
计算成本
- 训练与推理的高昂算力需求。
- 能耗与环境影响。
模型局限
- 偏见与公平性。
- 鲁棒性与对抗攻击。
伦理问题
- 隐私保护。
- 虚假信息生成。
5.2 未来方向
高效模型
- 更小、更快、更节能的模型。
- 模块化与可组合模型。
多模态融合
- 统一文本、图像、音频、视频。
自主学习
- 在线学习与自适应。
- 强化学习与人类反馈(RLHF)。
6. 学习资源与路径
6.1 入门资源

书籍
- 《Deep Learning》(Goodfellow et al.)。
- 《Natural Language Processing with Transformers》(Hugging Face)。
课程
- Stanford CS224N:NLP课程。
- Fast.ai:实用深度学习。
博客与教程
- Hugging Face Blog。
- Distill.pub。
6.2 进阶资源
论文
- 《Attention is All You Need》(Vaswani et al.)。
- GPT-3、PaLM、LLaMA系列论文。
项目实践
- Kaggle竞赛:NLP任务。
- GitHub项目:微调LLM。
社区
- Reddit:r/MachineLearning。
- Discord:Hugging Face社区。
6.3 学习路径
初学者
- 学习Python与PyTorch基础。
- 理解NLP基础(词向量、RNN)。
- 实践简单Transformer模型。
中级
- 微调BERT/GPT模型。
- 参与Kaggle NLP任务。
- 阅读核心论文。
高级
- 开发定制LLM。
- 优化分布式训练。
- 研究多模态与RLHF。
结束语
脑图最后结果在这里可以下载:
https://github.com/PulsarPioneers/llm-learn/blob/main/assets/llm-learn-base-mind.svg
如何系统的去学习大模型LLM ?
大模型时代,火爆出圈的LLM大模型让程序员们开始重新评估自己的本领。 “AI会取代那些行业?”“谁的饭碗又将不保了?”等问题热议不断。
事实上,抢你饭碗的不是AI,而是会利用AI的人。
继科大讯飞、阿里、华为等巨头公司发布AI产品后,很多中小企业也陆续进场!超高年薪,挖掘AI大模型人才! 如今大厂老板们,也更倾向于会AI的人,普通程序员,还有应对的机会吗?
与其焦虑……
不如成为「掌握AI工具的技术人」,毕竟AI时代,谁先尝试,谁就能占得先机!
但是LLM相关的内容很多,现在网上的老课程老教材关于LLM又太少。所以现在小白入门就只能靠自学,学习成本和门槛很高。
基于此,我用做产品的心态来打磨这份大模型教程,深挖痛点并持续修改了近70次后,终于把整个AI大模型的学习门槛,降到了最低!
在这个版本当中:
第一您不需要具备任何算法和数学的基础
第二不要求准备高配置的电脑
第三不必懂Python等任何编程语言
您只需要听我讲,跟着我做即可,为了让学习的道路变得更简单,这份大模型教程已经给大家整理并打包,现在将这份 LLM大模型资料 分享出来:包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

一、LLM大模型经典书籍
AI大模型已经成为了当今科技领域的一大热点,那以下这些大模型书籍就是非常不错的学习资源。

二、640套LLM大模型报告合集
这套包含640份报告的合集,涵盖了大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。(几乎涵盖所有行业)

三、LLM大模型系列视频教程

四、LLM大模型开源教程(LLaLA/Meta/chatglm/chatgpt)

五、AI产品经理大模型教程

LLM大模型学习路线 ↓
阶段1:AI大模型时代的基础理解
-
目标:了解AI大模型的基本概念、发展历程和核心原理。
-
内容:
- L1.1 人工智能简述与大模型起源
- L1.2 大模型与通用人工智能
- L1.3 GPT模型的发展历程
- L1.4 模型工程
- L1.4.1 知识大模型
- L1.4.2 生产大模型
- L1.4.3 模型工程方法论
- L1.4.4 模型工程实践
- L1.5 GPT应用案例
阶段2:AI大模型API应用开发工程
-
目标:掌握AI大模型API的使用和开发,以及相关的编程技能。
-
内容:
- L2.1 API接口
- L2.1.1 OpenAI API接口
- L2.1.2 Python接口接入
- L2.1.3 BOT工具类框架
- L2.1.4 代码示例
- L2.2 Prompt框架
- L2.3 流水线工程
- L2.4 总结与展望
阶段3:AI大模型应用架构实践
-
目标:深入理解AI大模型的应用架构,并能够进行私有化部署。
-
内容:
- L3.1 Agent模型框架
- L3.2 MetaGPT
- L3.3 ChatGLM
- L3.4 LLAMA
- L3.5 其他大模型介绍
阶段4:AI大模型私有化部署
-
目标:掌握多种AI大模型的私有化部署,包括多模态和特定领域模型。
-
内容:
- L4.1 模型私有化部署概述
- L4.2 模型私有化部署的关键技术
- L4.3 模型私有化部署的实施步骤
- L4.4 模型私有化部署的应用场景
这份 LLM大模型资料 包括LLM大模型书籍、640套大模型行业报告、LLM大模型学习视频、LLM大模型学习路线、开源大模型学习教程等, 😝有需要的小伙伴,可以 扫描下方二维码领取🆓↓↓↓

















 5440
5440

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









