







第一章统计学习方法概论
1.1统计学习
- 统计学习特点:计算机网络平台,数据驱动,构建模型,预测分析
- 统计学习对象:data,具有一定统计规律的数据
- 统计学习目的:预测分析
- 统计学习方法:模型,策略,算法; 统计学习方法的步骤:
- 统计学习方法的研究:理论与应用
- 统计学习方法重要性:数据挖掘领域核心技术

1.2监督学习
1.2.1基本概念
- 输入空间,输出空间,特征空间
实例的特征向量表示:
特征空间:表示实例的特征向量的集合
训练集的表示: - 联合概率分布
输入与输出的随机变量X和Y遵循联合概率分布P(X,Y),P(X,Y)表示分布函数。 - 假设空间
输入空间到输出空间的模型集合,就是假设空间。
监督学习的模型分非概率模型(决策函数Y=F(X))和概率模型(条件概率表示)
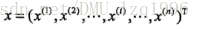
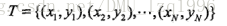
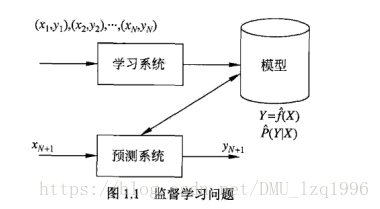
1.2.2问题形式化
监督学习问题:
1.3统计学习三要素(模型,策略,算法)
1.3.1模型
模型:由输入到输出的一个函数,所有模型(函数)构成假设空间。
模型分类:由决策函数表示的模型称为非概率模型;由条件概率表示的模型称为概率模型。
非概率模型:

概率模型:

1.3.2策略(如何从假设空间选择最优模型)
策略即衡量模型好坏的一个度量标准。
- 损失函数与风险函数
损失函数:利用模型进行预测的输出值f(X)与真实值Y的度量函数,记为L(Y,f(X))。
统计学习中常用的损失函数:
风险函数(期望损失):平均意义下的损失,即损失函数的期望值。
模型选择即策略就是选择期望风险最小的模型。 - 经验风险最小化与结构风险最小化
经验风险:当具体到某一训练集上时,风险函数就变为经验风险,经验风险是关于训练样本集的平均损失。根据大数定律可以知道,当样本足够大时,经验风险就是风险函数。
经验风险最小化策略:最优模型即经验风险最小时的模型。
当样本容量过小时存在问题:过拟合现象—结构风险最小化
结构风险最小化:在经验风险上加上表示模型复杂度的正则化项(罚项)
结构风险定义为:
尾项表示模型复杂度,模型越复杂,结构风险越大,反之,模型越简单,结构风险越小。即可以有效防止过拟合问题。

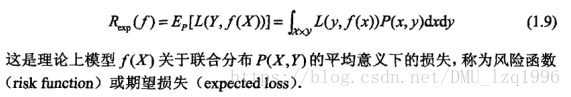

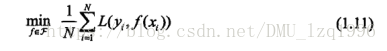
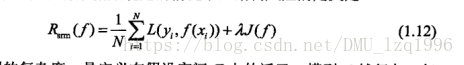
1.3.3算法

1.4模型评估与模型选择
1.4.1训练误差与测试误差
训练误差:关于训练数据集
测试误差:关于测试数据集


1.4.2 过拟合与模型选择
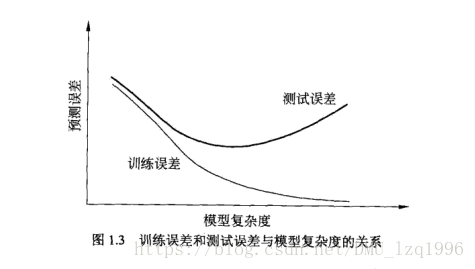
过拟合现象:对于训练数据预测能力极高的高复杂度的模型 ,这类模型过于追求对于训练数据的拟合程度,训练误差极低,但导致模型参数过多,复杂度太高,而且对于未知数据的预测能力低,测试误差太大。
如何衡量模型复杂度与测试误差及训练误差的关系?

1.5正则化与交叉验证
1.5.1正则化
正则化:结构风险最小化策略的实现,为了选择经验风险与模型复杂度同时较小的模型。
正则化项:模型复杂度的单调递增函数,模型复杂度越高,正则化值越大。
正则化项不同形式:(范数?)

1.5.2交叉验证
数据集分为训练集,验证集,测试集,利用三个集合对模型进行来回验证,即交叉验证。
分类:简单交叉验证;S折交叉验证;留一交叉验证
1.6泛化能力
1.6.1 泛化误差
泛化误差即模型的期望风险。

1.6.2泛化误差上界
泛化误差上界性质:与样本容量成反比,与假设空间容量成正比。
二分类的泛化误差上界:

1.7生成模型与判别模型
生成模型:
判别模型:
优缺点:



1.8 三大监督学习问题
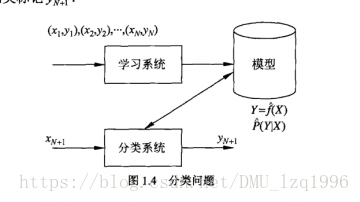
- 分类问题
分类问题中的模型称为分类器,评价分类器性能的指标有以下:
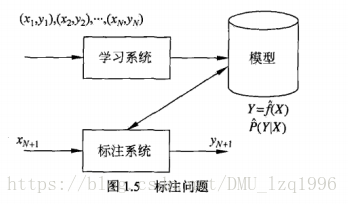
- 标注问题
经典应用:词性标注问题
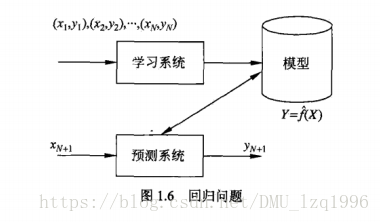
常用统计学习方法:隐马尔科夫模型,条件随机场 - 回归问题
















 650
650











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









