







SimAM注意力机制
SimAM(Similarity-based Attention Mechanism)是一种注意力机制,用于计算序列数据中的相似度。
论文地址:http://proceedings.mlr.press/v139/yang21o/yang21o.pdf
在SimAM中,给定一个查询序列Q和一个键值对序列K,注意力机制通过计算查询序列和键序列之间的相似度来确定注意力权重。具体来说,SimAM使用余弦相似度来度量查询序列和键序列之间的相似度。
SimAM的计算过程如下:
(1) 对于查询序列Q中的每个元素q,计算其与键序列K中每个元素k的余弦相似度。
(2) 对于每个查询序列元素q,通过对其与键序列元素k的相似度进行归一化,得到注意力权重。
(3) 使用注意力权重对值序列V进行加权求和,得到最终的注意力表示。
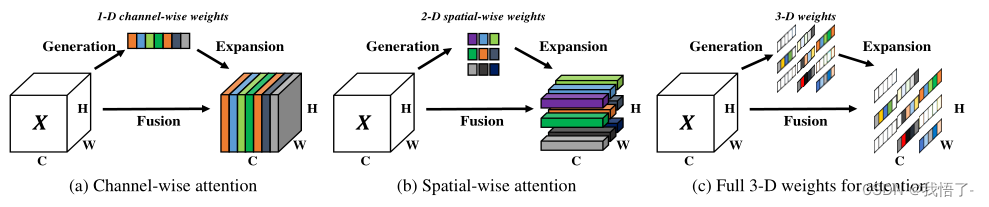
代码如下:
import torch
import torch.nn as nn
class SimAM(torch.nn.Module):
def __init__(self, e_lambda=1e-4):
super(SimAM, self).__init__()
self.activaton = nn.Sigmoid()
self.e_lambda = e_lambda
def __repr__(self):
s = self.__class__.__name__ + '('
s += ('lambda=%f)' % self.e_lambda)
return s
@staticmethod
def get_module_name():
return "simam"
def forward(self, x):
b, c, h, w = x.size()
n = w * h - 1
x_minus_mu_square = (x - x.mean(dim=[2, 3], keepdim=True)).pow(2)
y = x_minus_mu_square / (4 * (x_minus_mu_square.sum(dim=[2, 3], keepdim=True) / n + self.e_lambda)) + 0.5
return x * self.activaton(y)
if __name__ == '__main__':
input = torch.randn(3, 64, 7, 7)
model = SimAM()
outputs = model(input)
print(outputs.shape)

















 3789
3789











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











