







GE注意力机制
GE注意力机制,全称Gather-Excite Attention,来源于《Gather-Excite: Exploiting Feature Context in Convolutional Neural Networks》。
摘要:虽然在卷积神经网络中使用自下而上的局部算子 (CNN)与自然图像的一些统计数据非常匹配,也可能 防止此类模型捕获上下文远程特征交互。 在这项工作中,我们提出了一种简单、轻量级的方法,以获得更好的上下文 CNN中的剥削。我们通过引入一对运算符来做到这一点:收集, 从大空间范围内有效地聚合要素响应,以及 excite,将池化信息重新分发到本地要素。这 运算符很便宜,无论是在添加参数的数量方面还是 计算复杂,可直接集成到现有的 提高其性能的体系结构。在多个数据集上进行实验 表明聚集激发可以带来与增加深度相当的好处 的CNN成本仅为其中的一小部分。例如,我们发现 ResNet-50 与 Gather-Excite算子能够在以下方面优于其101层的对应物 没有其他可学习参数的 ImageNet。我们还提出了一个参数 收集-激励运算符对,可产生进一步的性能提升,将其关联起来 到最近推出的挤压和激励网络,并分析了 这些更改对 CNN 特征激活统计信息的影响。
论文地址:Gather-Excite: Exploiting Feature Context in Convolutional Neural Networks
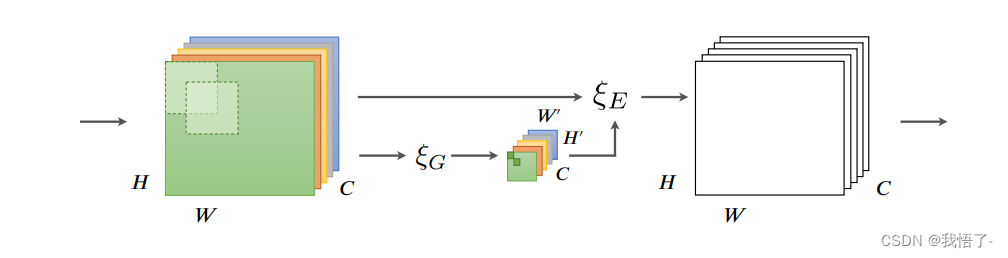
代码实现:
import math, torch
from torch import nn as nn
import torch.nn.functional as F
from timm.models.layers.create_act import create_act_layer, get_act_layer
from timm.models.layers.create_conv2d import create_conv2d
from timm.models.layers import make_divisible
from timm.models.layers.mlp import ConvMlp
class GatherExcite(nn.Module):
def __init__(
self, channels, feat_size=None, extra_params=False, extent=0, use_mlp=True,
rd_ratio=1./16, rd_channels=None, rd_divisor=1, add_maxpool=False,
act_layer=nn.ReLU, norm_layer=nn.BatchNorm2d, gate_layer='sigmoid'):
super(GatherExcite, self).__init__()
self.add_maxpool = add_maxpool
act_layer = get_act_layer(act_layer)
self.extent = extent
if extra_params:
self.gather = nn.Sequential()
if extent == 0:
assert feat_size is not None, 'spatial feature size must be specified for global extent w/ params'
self.gather.add_module(
'conv1', create_conv2d(channels, channels, kernel_size=feat_size, stride=1, depthwise=True))
if norm_layer:
self.gather.add_module(f'norm1', nn.BatchNorm2d(channels))
else:
assert extent % 2 == 0
num_conv = int(math.log2(extent))
for i in range(num_conv):
self.gather.add_module(
f'conv{i + 1}',
create_conv2d(channels, channels, kernel_size=3, stride=2, depthwise=True))
if norm_layer:
self.gather.add_module(f'norm{i + 1}', nn.BatchNorm2d(channels))
if i != num_conv - 1:
self.gather.add_module(f'act{i + 1}', act_layer(inplace=True))
else:
self.gather = None
if self.extent == 0:
self.gk = 0
self.gs = 0
else:
assert extent % 2 == 0
self.gk = self.extent * 2 - 1
self.gs = self.extent
if not rd_channels:
rd_channels = make_divisible(channels * rd_ratio, rd_divisor, round_limit=0.)
self.mlp = ConvMlp(channels, rd_channels, act_layer=act_layer) if use_mlp else nn.Identity()
self.gate = create_act_layer(gate_layer)
def forward(self, x):
size = x.shape[-2:]
if self.gather is not None:
x_ge = self.gather(x)
else:
if self.extent == 0:
# global extent
x_ge = x.mean(dim=(2, 3), keepdims=True)
if self.add_maxpool:
# experimental codepath, may remove or change
x_ge = 0.5 * x_ge + 0.5 * x.amax((2, 3), keepdim=True)
else:
x_ge = F.avg_pool2d(
x, kernel_size=self.gk, stride=self.gs, padding=self.gk // 2, count_include_pad=False)
if self.add_maxpool:
# experimental codepath, may remove or change
x_ge = 0.5 * x_ge + 0.5 * F.max_pool2d(x, kernel_size=self.gk, stride=self.gs, padding=self.gk // 2)
x_ge = self.mlp(x_ge)
if x_ge.shape[-1] != 1 or x_ge.shape[-2] != 1:
x_ge = F.interpolate(x_ge, size=size)
return x * self.gate(x_ge)
if __name__ == '__main__':
input=torch.randn(50,512,7,7)
GE = GatherExcite(512)
output=GE(input)
print(output.shape)

















 4589
4589











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











