







 Gather-Excite是一种新型注意力机制,旨在通过不同层级的空间上下文信息增强特征图。该方法通过全局平均池化或深度卷积等方式收集特征,并通过多层感知机调整通道权重,最终与原始特征图融合提升模型性能。
Gather-Excite是一种新型注意力机制,旨在通过不同层级的空间上下文信息增强特征图。该方法通过全局平均池化或深度卷积等方式收集特征,并通过多层感知机调整通道权重,最终与原始特征图融合提升模型性能。
paper:Gather-Excite: Exploiting Feature Context in Convolutional Neural Networks
前言
SENET作者的另一篇注意力机制的文章,和SENET以及BAM、CBAM的思想差不多,其实不用看文章,看下面的代码和结构图就知道具体的实现过程了。
本文的切入点在于context exploitation,其实就是空间维度的注意力机制,和BAM、CBAM的区别在于BAM在空间维度使用的普通卷积,最后输出的是单通道的特征图,因此在与原始特征图进行element-wise multiplication时每一个像素在所有通道上的权重是相同的。而GENET中使用的是深度卷积,最后的输出特征图通道数和原始输入一致,因此同一位置在不同通道上的权重是不同的。
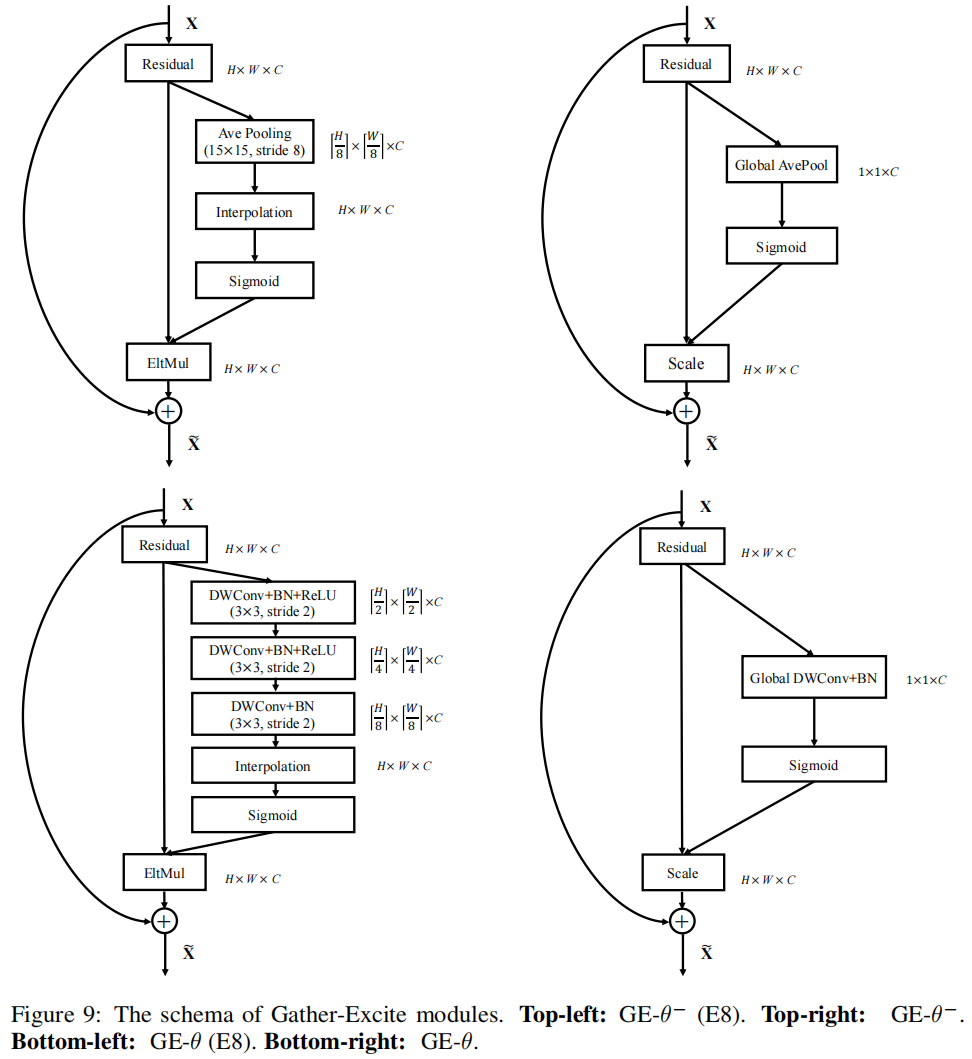
文中设计了GE的多种不同结构,\(GE-\theta^{-}\)中gather的过程是通过全局平均池化实现的,因此没有增加额外需要训练的参数。\(GE-\theta\)中gather是通过深度卷积实现的。\(GE-\theta^{+}\)则是结合了SE的思想,在\(GE-\theta\)的后面先通过一个1x1卷积缩减通道,再通过一个1x1卷积还原回去。
文中提到的extent ratio和SE中的reduction ratio差不多,SE中r=16,第一个1x1卷积后通道数减为1/16。第二个1x1卷积再还原回去。GE中当e=8时,\(GE-\theta^{-}\)是一个stride=8的平均池化,池化的kernel size可以自己设置。\(GE-\theta^{+}\)中的gather则是通过3个stride=2的dwconv+bn+relu实现的。若e=16,则前者平均池化的stride=16,后者则是堆叠4个stride=2的dwconv+bn+relu,以此类推。
实现代码
下面的代码是timm中的实现
""" Gather-Excite Attention Block
Paper: `Gather-Excite: Exploiting Feature Context in CNNs` - https://arxiv.org/abs/1810.12348
Official code here, but it's only partial impl in Caffe: https://github.com/hujie-frank/GENet
I've tried to support all of the extent both w/ and w/o params. I don't believe I've seen another
impl that covers all of the cases.
NOTE: extent=0 + extra_params=False is equivalent to Squeeze-and-Excitation
Hacked together by / Copyright 2021 Ross Wightman
"""
import math
from torch import nn as nn
import torch.nn.functional as F
from .create_act import create_act_layer, get_act_layer
from .create_conv2d import create_conv2d
from .helpers import make_divisible
from .mlp import ConvMlp
class GatherExcite(nn.Module):
""" Gather-Excite Attention Module
"""
def __init__(
self, channels, feat_size=None, extra_params=False, extent=0, use_mlp=True,
rd_ratio=1./16, rd_channels=None, rd_divisor=1, add_maxpool=False,
act_layer=nn.ReLU, norm_layer=nn.BatchNorm2d, gate_layer='sigmoid'):
super(GatherExcite, self).__init__()
self.add_maxpool = add_maxpool
act_layer = get_act_layer(act_layer)
self.extent = extent
if extra_params:
self.gather = nn.Sequential()
if extent == 0:
assert feat_size is not None, 'spatial feature size must be specified for global extent w/ params'
self.gather.add_module(
'conv1', create_conv2d(channels, channels, kernel_size=feat_size, stride=1, depthwise=True))
if norm_layer:
self.gather.add_module(f'norm1', nn.BatchNorm2d(channels))
else:
assert extent % 2 == 0
num_conv = int(math.log2(extent))
for i in range(num_conv):
self.gather.add_module(
f'conv{i + 1}',
create_conv2d(channels, channels, kernel_size=3, stride=2, depthwise=True))
if norm_layer:
self.gather.add_module(f'norm{i + 1}', nn.BatchNorm2d(channels))
if i != num_conv - 1:
self.gather.add_module(f'act{i + 1}', act_layer(inplace=True))
else:
self.gather = None
if self.extent == 0:
self.gk = 0
self.gs = 0
else:
assert extent % 2 == 0
self.gk = self.extent * 2 - 1
self.gs = self.extent
if not rd_channels:
rd_channels = make_divisible(channels * rd_ratio, rd_divisor, round_limit=0.)
self.mlp = ConvMlp(channels, rd_channels, act_layer=act_layer) if use_mlp else nn.Identity()
self.gate = create_act_layer(gate_layer)
def forward(self, x):
size = x.shape[-2:]
if self.gather is not None:
x_ge = self.gather(x)
else:
if self.extent == 0:
# global extent
x_ge = x.mean(dim=(2, 3), keepdims=True)
if self.add_maxpool:
# experimental codepath, may remove or change
x_ge = 0.5 * x_ge + 0.5 * x.amax((2, 3), keepdim=True)
else:
x_ge = F.avg_pool2d(
x, kernel_size=self.gk, stride=self.gs, padding=self.gk // 2, count_include_pad=False)
if self.add_maxpool:
# experimental codepath, may remove or change
x_ge = 0.5 * x_ge + 0.5 * F.max_pool2d(x, kernel_size=self.gk, stride=self.gs, padding=self.gk // 2)
x_ge = self.mlp(x_ge)
if x_ge.shape[-1] != 1 or x_ge.shape[-2] != 1:
x_ge = F.interpolate(x_ge, size=size)
return x * self.gate(x_ge)
结构图
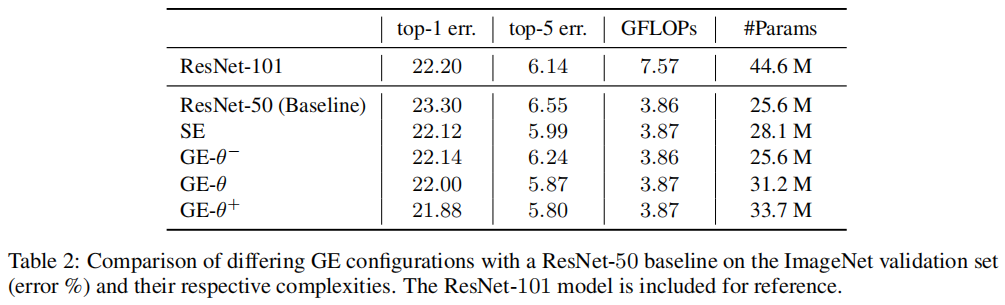
实验结果


















 1153
1153

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











