








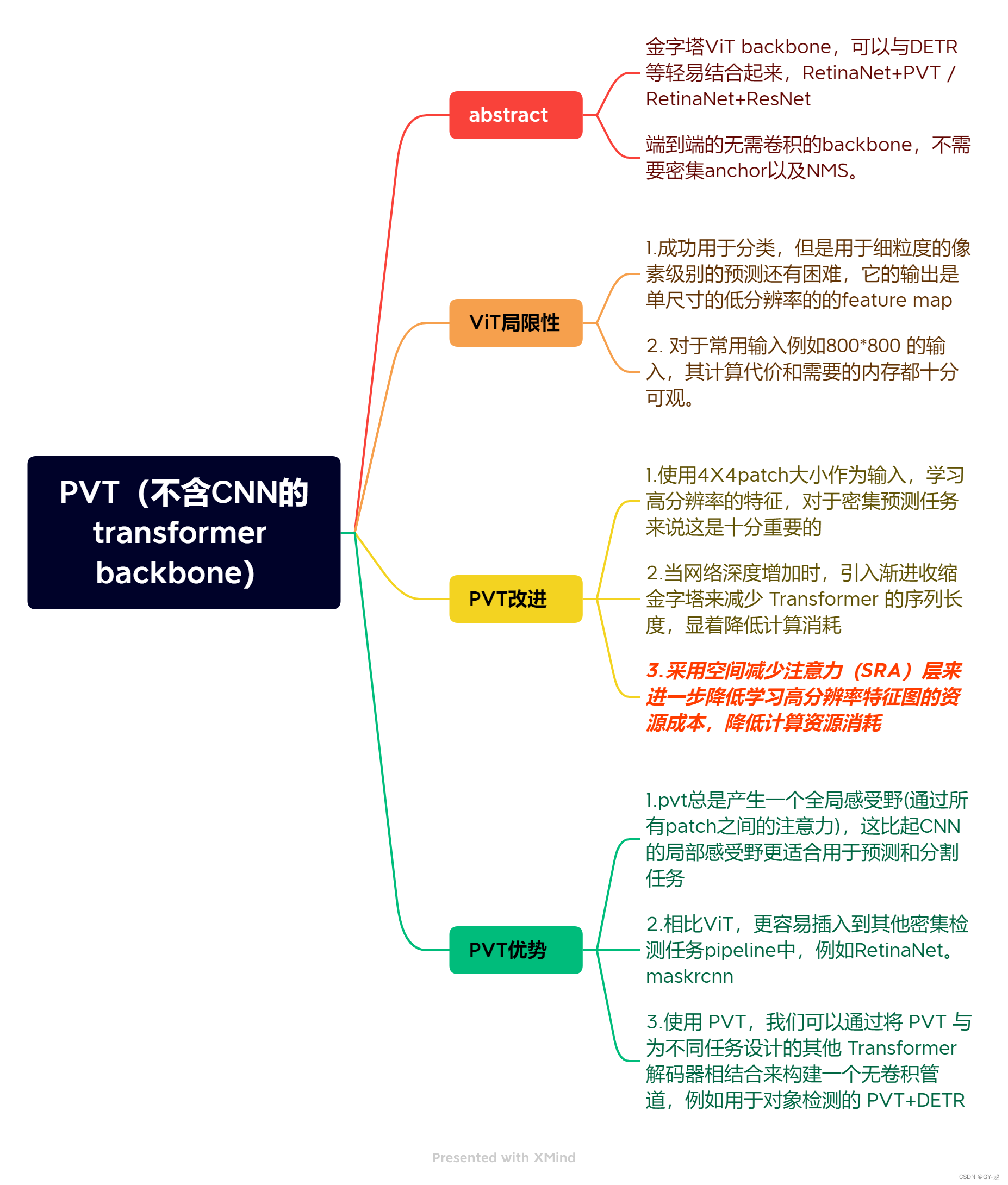
1. 网络框图
1.输入一张 H × W × 3 H \times W\times 3 H×W×3的图片,经过一个PatchEmbeeding将其分割成 H W 4 2 \frac{HW}{4^2} 42HW patches,每一个Patch大小是 4 × 4 × 3 4\times 4 \times 3 4×4×3,经过一个Linear Projection 得到embeeding patches : H × W 4 2 × C 1 \frac{H\times W}{4^2}\times C_1 42H×W×C1,之后通过一个有 L 1 L_1 L1层的encoder, 输出的特征被reshape为3D特征 F 1 F1 F1 ( H 4 × W 4 × C 1 \frac{H}{4}\times \frac{W}{4}\times C_1 4H×4W×C1 ).
将 F 1 F_1 F1作为下一阶段的输入,重新对其进行patch划分,此时采用patch_size=2 ,也就是采用这种对feature map多次划分patch的方法,层层降低了分辨率,以此类推可以得到不同分辨率的 F 2 , F 3 , F 4 {F_2,F_3,F_4} F2,F3,F4
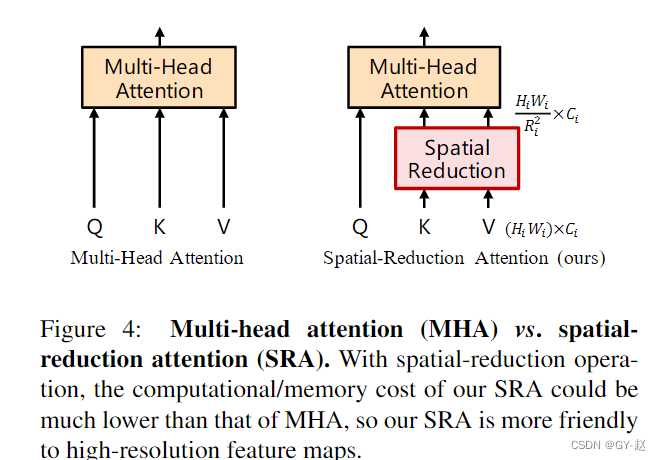
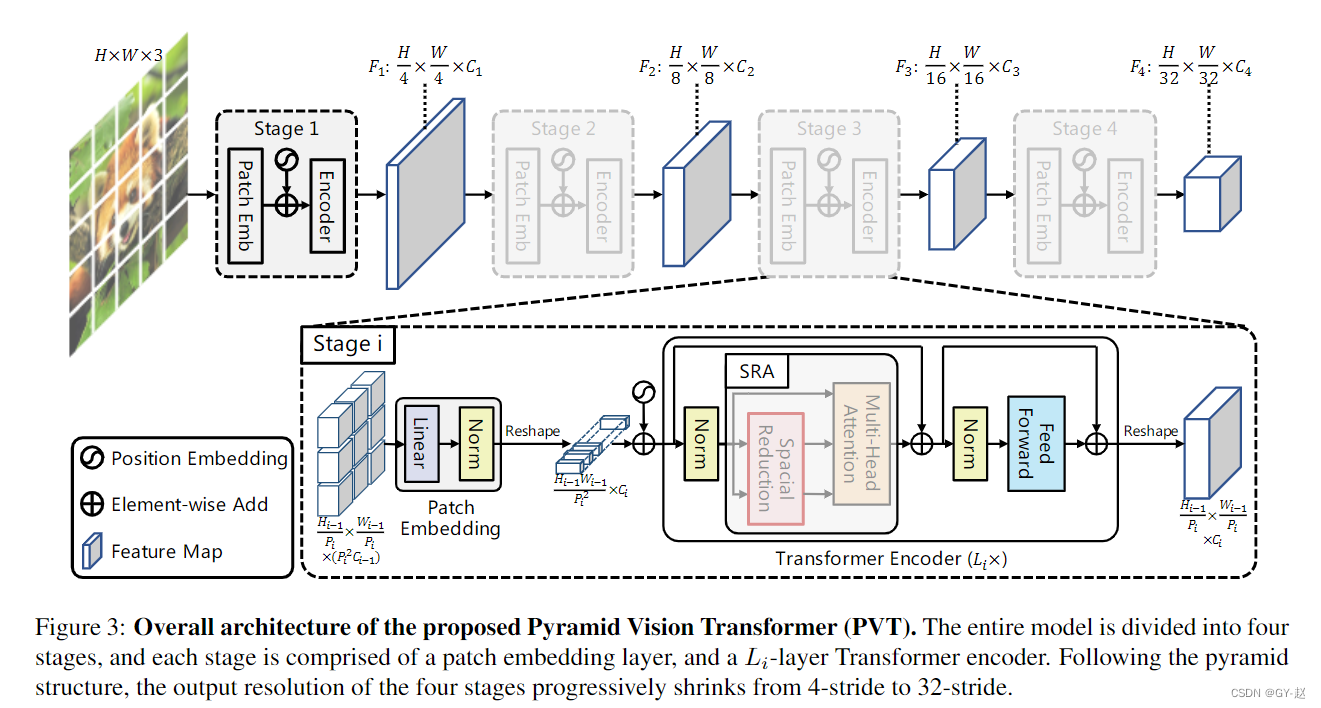
由于使用了 4 × 4 4 \times 4 4×4 大小的patch,计算transformer所需的资源巨大, 因此必须想办法减少计算代价。作者这里主要使用一种SRA的方法,将计算attention需要的输入 K,V通过一个线性投影,减少计算维度。

R i R_i Ri 代表缩减率,reshape操作就是将输入 x ∈ R H i W i × C i x \in \mathbb{R}^{H_iW_i\times C_i} x∈RHiWi×Ci,通过线性投影 W s ∈ R ( R i 2 C i ) × C i W_s \in \mathbb{R}^{(R_i^2C_i)\times C_i} Ws∈R(Ri2Ci)×Ci,变为 H i W i R i 2 × ( R i 2 C i ) \frac{H_iW_i}{R_i^2}\times (R_i^2C_i) Ri2HiWi×(Ri2Ci),Norm代表layer Norm。

attention的计算还是以前的公式。通过这些公式,可以计算出 Attention(·) 操作的计算/内存成本比 MHA 低 R 2 R^2 R2 倍,因此它可以在资源有限的情况下处理更大的输入特征图/序列。
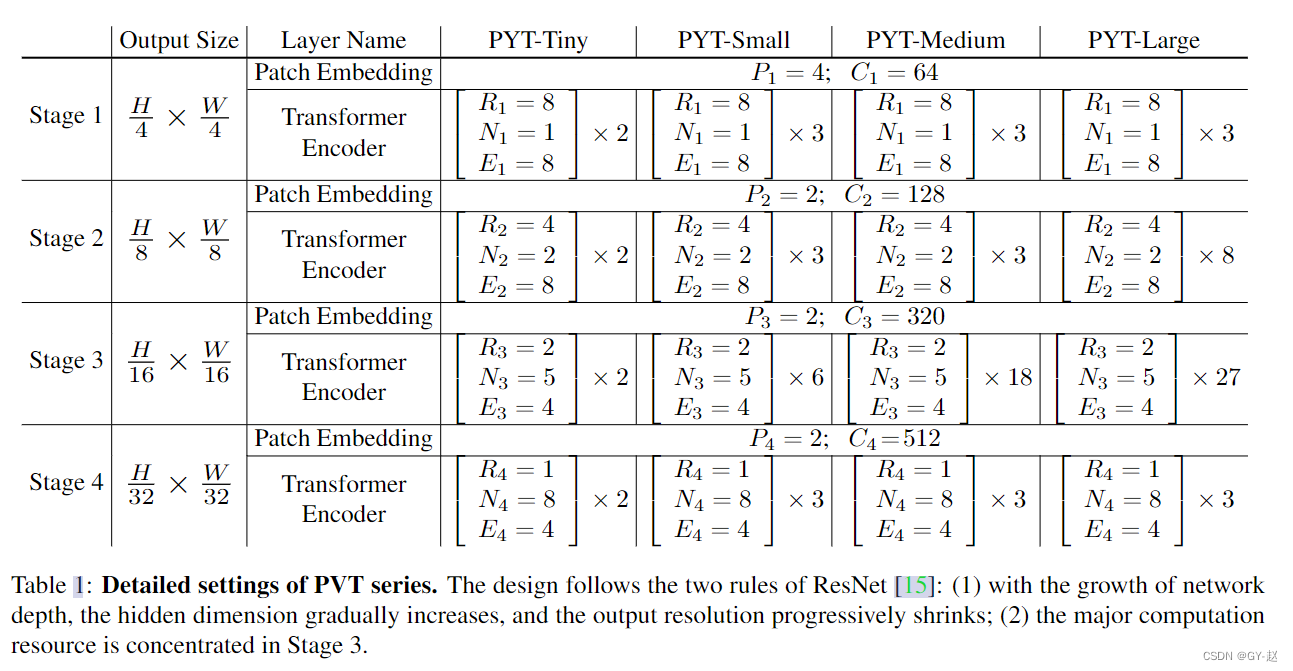
论文所说,主要消耗资源的地方在stage 3















 3026
3026











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









