







EAST: An Efficient and Accurate Scene Text Detector
用于场景文本检测的先前方法已经在各种基准测试中获得了良好的性能。然而,在处理具有挑战性的场景时,即使配备了深度神经网络模型,通常也会达不到很好性能,因为整体性能取决于pipline中多个阶段和组件的相互作用。EAST提出了一个简单而强大的pipline,可以在自然场景中产生快速准确的文本检测。算法流程直接预测完整图像中任意方向和四边形形状的单词或文本行,消除了使用单个神经网络的不必要的中间步骤(例如,候选聚合和字分区)。在标准数据集(包括ICDAR 2015,COCO-Text和MSRA-TD500)的实验表明,所提出的算法在准确性和效率方面明显优于最先进的方法。在ICDAR 2015数据集上,所提出的算法在720p分辨率下以13.2fps达到0.7820的F-score。
算法在ICDAR 2015 [15](在多尺度下测试时为0.8072),在MSRA-TD500 [40]上为0.7608,在COCO-Text上为0.3945 [36]时,得分为0.7820,优于之前的状态 - 性能最先进的算法,同时平均花费的时间少得多(在Titan-X GPU上,对于最好的模型,在720p分辨率下为13.2fps,对于我们最快的模型,为16.8fps)。
主要创新点:
- 提出了一种场景文本检测方法,包括两个阶段:全卷积网络和NMS合并阶段。 FCN直接生成文本区域,不包括冗余和耗时的中间步骤。
- 算法可以灵活地生成字级或线级预测,其几何形状可以是旋转框或四边形,具体取决于具体应用。
- 所提出的算法在精度和速度方面明显优于最先进的方法。

模型框架:

预测通道之一是得分图,其像素值在[0,1]的范围内。 其余通道表示从每个像素的视图中包围该单词的几率。 分数代表在相同位置预测的几何形状的置信度。
我们已经为文本区域,旋转框(RBOX)和四边形(QUAD)实验了两种几何形状,并为每种几何设计了不同的损失函数。 然后将阈值处理应用于每个预测区域,其中得分超过预定阈值的几何被认为是有效的并且被保存用于稍后的非最大抑制。 NMS之后的结果被认为是管道的最终输出。
def resnet_east(backbone='resnet50', inputs=None, modifier=None, **kwargs):
# choose default input
if inputs is None:
if keras.backend.image_data_format() == 'channels_first':
inputs = keras.layers.Input(shape=(3, None, None))
else:
inputs = keras.layers.Input(shape=(None, None, 3))
# create the vgg backbone
if backbone == 'resnet50':
resnet = keras.applications.ResNet50(input_tensor=inputs, include_top=False, weights=None)
elif backbone == 'resnet101':
resnet = keras.applications.ResNet101(input_tensor=inputs, include_top=False, weights=None)
elif backbone == 'resnet152':
resnet = keras.applications.ResNet152(input_tensor=inputs, include_top=False, weights=None)
else:
raise ValueError("Backbone '{}' not recognized.".format(backbone))
if modifier:
resnet = modifier(resnet)
layer_names = ['activation_49', 'activation_40', 'activation_22', 'activation_10']
backbone_layers = [resnet.get_layer(i).output for i in layer_names]
return east(input=inputs, backbone_layers=backbone_layers, **kwargs)
def east(
input,
backbone_layers,
config = None,
name = 'east'
):
overly_small_text_region_training_mask = Input(shape=(None, None, 1), name='overly_small_text_region_training_mask')
text_region_boundary_training_mask = Input(shape=(None, None, 1), name='text_region_boundary_training_mask')
target_score_map = Input(shape=(None, None, 1), name='target_score_map')
act_49, act_40, act_22, act_10 = backbone_layers
if config is None:
config = cfg
x = Lambda(resize_bilinear, name='resize_1')(act_49)
x = concatenate([x, act_40], axis=3)
x = Conv2D(128, (1, 1), padding='same', kernel_regularizer=l2(1e-5))(x)
x = BatchNormalization(momentum=0.997, epsilon=1e-5, scale=True)(x)
x = Activation('relu')(x)
x = Conv2D(128, (3, 3), padding='same', kernel_regularizer=l2(1e-5))(x)
x = BatchNormalization(momentum=0.997, epsilon=1e-5, scale=True)(x)
x = Activation('relu')(x)
x = Lambda(resize_bilinear, name='resize_2')(x)
x = concatenate([x, act_22], axis=3)
x = Conv2D(64, (1, 1), padding='same', kernel_regularizer=l2(1e-5))(x)
x = BatchNormalization(momentum=0.997, epsilon=1e-5, scale=True)(x)
x = Activation('relu')(x)
x = Conv2D(64, (3, 3), padding='same', kernel_regularizer=l2(1e-5))(x)
x = BatchNormalization(momentum=0.997, epsilon=1e-5, scale=True)(x)
x = Activation('relu')(x)
x = Lambda(resize_bilinear, name='resize_3')(x)
x = concatenate([x, act_10], axis=3)
x = Conv2D(32, (1, 1), padding='same', kernel_regularizer=l2(1e-5))(x)
x = BatchNormalization(momentum=0.997, epsilon=1e-5, scale=True)(x)
x = Activation('relu')(x)
x = Conv2D(32, (3, 3), padding='same', kernel_regularizer=l2(1e-5))(x)
x = BatchNormalization(momentum=0.997, epsilon=1e-5, scale=True)(x)
x = Activation('relu')(x)
x = Conv2D(32, (3, 3), padding='same', kernel_regularizer=l2(1e-5))(x)
x = BatchNormalization(momentum=0.997, epsilon=1e-5, scale=True)(x)
x = Activation('relu')(x)
pred_score_map = Conv2D(1, (1, 1), activation=keras.backend.sigmoid, name='pred_score_map')(x)
rbox_geo_map = Conv2D(4, (1, 1), activation=keras.backend.sigmoid, name='rbox_geo_map')(x)
rbox_geo_map = Lambda(lambda x: x * config.INPUT_SIZE)(rbox_geo_map)
angle_map = Conv2D(1, (1, 1), activation=keras.backend.sigmoid, name='rbox_angle_map')(x)
angle_map = Lambda(lambda x: (x - 0.5) * np.pi / 2)(angle_map)
pred_geo_map = concatenate([rbox_geo_map, angle_map], axis=3, name='pred_geo_map')
model = keras.models.Model(inputs=[input, overly_small_text_region_training_mask,
text_region_boundary_training_mask,
target_score_map],
outputs=[pred_score_map, pred_geo_map],
name=name)
return model几何输出可以是RBOX或QUAD之一,在Tab中汇总.1

对于RBOX,几何形状由4个通道的轴对齐边界框(AABB)R和1个通道旋转角θ表示。R的公式与[9]中的公式相同,其中4个通道分别表示从像素位置到矩形的顶部,右侧,底部,左边界的4个距离。
对于QUAD Q,我们使用8个数字来表示从四个角顶点{p i |的坐标偏移 i∈{1,4,3,4}}四边形到像素位置。由于每个距离偏移包含两个数字(Δxi,Δyi),因此几何输出包含8个通道。
上述代码为RBOX
前处理:
只考虑几何是四边形的情况。分数图上的四边形的正面积被设计为大致缩小(shrunk) 的原始面积,如图所示。

对于四边形
![]()
其中p_i= {x i,y i}是四边形上的顶点,以顺时针顺序排列。为了缩小Q,我们首先计算每个顶点pi的参考长度ri
![]()
首先缩小四边形的两个较长边,然后缩短两个较短边。对于每对两个相对的边,我们通过比较它们的长度的平均值来确定“更长”的对。
对于每个边![]() 通过将两个端点沿着边缘向内移动0.3ri和
通过将两个端点沿着边缘向内移动0.3ri和 来缩小它。
来缩小它。
def compute_targets_east(self, imggroup, anngroup):
score_maps = []
geo_maps = []
overly_small_text_region_training_masks = []
text_region_boundary_training_masks = []
for img, ann in zip(imggroup, anngroup):
gtbox = ann['bboxes'].reshape(((-1, 4, 2)))
label = ann['labels']
h, w, c = img.shape
score_map, geo_map, overly_small_text_region_training_mask, text_region_boundary_training_mask = generate_rbox(
(h, w), gtbox, label, self.config)
score_maps.append(score_map[::4, ::4, np.newaxis].astype(np.float32))
geo_maps.append(geo_map[::4, ::4, :].astype(np.float32))
overly_small_text_region_training_masks.append(
overly_small_text_region_training_mask[::4, ::4, np.newaxis].astype(np.float32))
text_region_boundary_training_masks.append(
text_region_boundary_training_mask[::4, ::4, np.newaxis].astype(np.float32))
return [np.array(overly_small_text_region_training_masks),
np.array(text_region_boundary_training_masks),
np.array(score_maps)], \
[np.array(score_maps), np.array(geo_maps)]
def generate_rbox(im_size, polys, tags, config = None):
if config is None:
config = cfg
h, w = im_size
shrinked_poly_mask = np.zeros((h, w), dtype=np.uint8)
orig_poly_mask = np.zeros((h, w), dtype=np.uint8)
score_map = np.zeros((h, w), dtype=np.uint8)
geo_map = np.zeros((h, w, 5), dtype=np.float32)
# mask used during traning, to ignore some hard areas
overly_small_text_region_training_mask = np.ones((h, w), dtype=np.uint8)
for poly_idx, poly_data in enumerate(zip(polys, tags)):
poly = poly_data[0]
tag = poly_data[1]
#确定短边距ri
r = [None, None, None, None]
for i in range(4):
r[i] = min(np.linalg.norm(poly[i] - poly[(i + 1) % 4]),
np.linalg.norm(poly[i] - poly[(i - 1) % 4]))
# 四边形缩减
shrinked_poly = shrink_poly(poly.copy(), r).astype(np.int32)[np.newaxis, :, :]
# 填充得分图,
cv2.fillPoly(score_map, shrinked_poly, 1)
cv2.fillPoly(shrinked_poly_mask, shrinked_poly, poly_idx + 1)
# 填充原四边形
cv2.fillPoly(orig_poly_mask, poly.astype(np.int32)[np.newaxis, :, :], 1)
# 四边形太小则忽略
poly_h = min(np.linalg.norm(poly[0] - poly[3]), np.linalg.norm(poly[1] - poly[2]))
poly_w = min(np.linalg.norm(poly[0] - poly[1]), np.linalg.norm(poly[2] - poly[3]))
if min(poly_h, poly_w) < config.min_text_size:
cv2.fillPoly(overly_small_text_region_training_mask, poly.astype(np.int32)[np.newaxis, :, :], 0)
if tag:
cv2.fillPoly(overly_small_text_region_training_mask, poly.astype(np.int32)[np.newaxis, :, :], 0)
xy_in_poly = np.argwhere(shrinked_poly_mask == (poly_idx + 1))
# if geometry == 'RBOX':
# generate a parallelogram for any combination of two vertices
fitted_parallelograms = []
for i in range(4):
p0 = poly[i]
p1 = poly[(i + 1) % 4]
p2 = poly[(i + 2) % 4]
p3 = poly[(i + 3) % 4]
edge = fit_line([p0[0], p1[0]], [p0[1], p1[1]]) #[k, -1, b], [1., 0., -p1[0]] if p1[0] == p1[1]:
backward_edge = fit_line([p0[0], p3[0]], [p0[1], p3[1]])
forward_edge = fit_line([p1[0], p2[0]], [p1[1], p2[1]])
#p2 到p0-p1的距离》p3 到p0-p1的距离
if point_dist_to_line(p0, p1, p2) > point_dist_to_line(p0, p1, p3):
# 经过p2平行于p0-p1的直线
if edge[1] == 0:
edge_opposite = [1, 0, -p2[0]]
else:
edge_opposite = [edge[0], -1, p2[1] - edge[0] * p2[0]]
else:
# # 经过p3平行于p0-p1的直线
if edge[1] == 0:
edge_opposite = [1, 0, -p3[0]]
else:
edge_opposite = [edge[0], -1, p3[1] - edge[0] * p3[0]]
# move forward edge
new_p0 = p0
new_p1 = p1
new_p2 = p2
new_p3 = p3
new_p2 = line_cross_point(forward_edge, edge_opposite) #p2-p3直线与p1-p2的交点
if point_dist_to_line(p1, new_p2, p0) > point_dist_to_line(p1, new_p2, p3):
# across p0
if forward_edge[1] == 0:
forward_opposite = [1, 0, -p0[0]]
else:
forward_opposite = [forward_edge[0], -1, p0[1] - forward_edge[0] * p0[0]]
else:
# across p3
if forward_edge[1] == 0:
forward_opposite = [1, 0, -p3[0]]
else:
forward_opposite = [forward_edge[0], -1, p3[1] - forward_edge[0] * p3[0]]
new_p0 = line_cross_point(forward_opposite, edge)
new_p3 = line_cross_point(forward_opposite, edge_opposite)
fitted_parallelograms.append([new_p0, new_p1, new_p2, new_p3, new_p0])
# or move backward edge
new_p0 = p0
new_p1 = p1
new_p2 = p2
new_p3 = p3
new_p3 = line_cross_point(backward_edge, edge_opposite) #p2-p3直线与p0-p3的交点
if point_dist_to_line(p0, p3, p1) > point_dist_to_line(p0, p3, p2):
# across p1
if backward_edge[1] == 0:
backward_opposite = [1, 0, -p1[0]]
else:
backward_opposite = [backward_edge[0], -1, p1[1] - backward_edge[0] * p1[0]]
else:
# across p2
if backward_edge[1] == 0:
backward_opposite = [1, 0, -p2[0]]
else:
backward_opposite = [backward_edge[0], -1, p2[1] - backward_edge[0] * p2[0]]
new_p1 = line_cross_point(backward_opposite, edge)
new_p2 = line_cross_point(backward_opposite, edge_opposite)
fitted_parallelograms.append([new_p0, new_p1, new_p2, new_p3, new_p0])
areas = [Polygon(t).area for t in fitted_parallelograms] #计算所有拟合四边形的面积
parallelogram = np.array(fitted_parallelograms[np.argmin(areas)][:-1], dtype=np.float32) #取最小的
# sort thie polygon
parallelogram_coord_sum = np.sum(parallelogram, axis=1) #分别对x和y坐标求和
min_coord_idx = np.argmin(parallelogram_coord_sum) #x,y的极小值
parallelogram = parallelogram[
[min_coord_idx, (min_coord_idx + 1) % 4, (min_coord_idx + 2) % 4, (min_coord_idx + 3) % 4]]
rectange = rectangle_from_parallelogram(parallelogram) #最小外接旋转矩形
rectange, rotate_angle = sort_rectangle(rectange)#最小外接旋转矩形顶点顺时针排序
p0_rect, p1_rect, p2_rect, p3_rect = rectange
for y, x in xy_in_poly:
point = np.array([x, y], dtype=np.float32)
# top
geo_map[y, x, 0] = point_dist_to_line(p0_rect, p1_rect, point)
# right
geo_map[y, x, 1] = point_dist_to_line(p1_rect, p2_rect, point)
# down
geo_map[y, x, 2] = point_dist_to_line(p2_rect, p3_rect, point)
# left
geo_map[y, x, 3] = point_dist_to_line(p3_rect, p0_rect, point)
# angle
geo_map[y, x, 4] = rotate_angle
shrinked_poly_mask = (shrinked_poly_mask > 0).astype('uint8')
text_region_boundary_training_mask = 1 - (orig_poly_mask - shrinked_poly_mask)
return score_map, geo_map, overly_small_text_region_training_mask, text_region_boundary_training_mask
def shrink_poly(poly, r):
'''
fit a poly inside the origin poly, maybe bugs here...
used for generating the score map
:param poly: the text poly
:param r: r in the paper
:return: the shrinked poly
'''
# shrink ratio
R = 0.3
# find the longer pair
if np.linalg.norm(poly[0] - poly[1]) + np.linalg.norm(poly[2] - poly[3]) > \
np.linalg.norm(poly[0] - poly[3]) + np.linalg.norm(poly[1] - poly[2]):
# first move (p0, p1), (p2, p3), then (p0, p3), (p1, p2)
## p0, p1
theta = np.arctan2((poly[1][1] - poly[0][1]), (poly[1][0] - poly[0][0]))
poly[0][0] += R * r[0] * np.cos(theta)
poly[0][1] += R * r[0] * np.sin(theta)
poly[1][0] -= R * r[1] * np.cos(theta)
poly[1][1] -= R * r[1] * np.sin(theta)
## p2, p3
theta = np.arctan2((poly[2][1] - poly[3][1]), (poly[2][0] - poly[3][0]))
poly[3][0] += R * r[3] * np.cos(theta)
poly[3][1] += R * r[3] * np.sin(theta)
poly[2][0] -= R * r[2] * np.cos(theta)
poly[2][1] -= R * r[2] * np.sin(theta)
## p0, p3
theta = np.arctan2((poly[3][0] - poly[0][0]), (poly[3][1] - poly[0][1]))
poly[0][0] += R * r[0] * np.sin(theta)
poly[0][1] += R * r[0] * np.cos(theta)
poly[3][0] -= R * r[3] * np.sin(theta)
poly[3][1] -= R * r[3] * np.cos(theta)
## p1, p2
theta = np.arctan2((poly[2][0] - poly[1][0]), (poly[2][1] - poly[1][1]))
poly[1][0] += R * r[1] * np.sin(theta)
poly[1][1] += R * r[1] * np.cos(theta)
poly[2][0] -= R * r[2] * np.sin(theta)
poly[2][1] -= R * r[2] * np.cos(theta)
else:
## p0, p3
theta = np.arctan2((poly[3][0] - poly[0][0]), (poly[3][1] - poly[0][1]))
poly[0][0] += R * r[0] * np.sin(theta)
poly[0][1] += R * r[0] * np.cos(theta)
poly[3][0] -= R * r[3] * np.sin(theta)
poly[3][1] -= R * r[3] * np.cos(theta)
## p1, p2
theta = np.arctan2((poly[2][0] - poly[1][0]), (poly[2][1] - poly[1][1]))
poly[1][0] += R * r[1] * np.sin(theta)
poly[1][1] += R * r[1] * np.cos(theta)
poly[2][0] -= R * r[2] * np.sin(theta)
poly[2][1] -= R * r[2] * np.cos(theta)
## p0, p1
theta = np.arctan2((poly[1][1] - poly[0][1]), (poly[1][0] - poly[0][0]))
poly[0][0] += R * r[0] * np.cos(theta)
poly[0][1] += R * r[0] * np.sin(theta)
poly[1][0] -= R * r[1] * np.cos(theta)
poly[1][1] -= R * r[1] * np.sin(theta)
## p2, p3
theta = np.arctan2((poly[2][1] - poly[3][1]), (poly[2][0] - poly[3][0]))
poly[3][0] += R * r[3] * np.cos(theta)
poly[3][1] += R * r[3] * np.sin(theta)
poly[2][0] -= R * r[2] * np.cos(theta)
poly[2][1] -= R * r[2] * np.sin(theta)
return poly
def fit_line(p1, p2):
# fit a line ax+by+c = 0
if p1[0] == p1[1]:
return [1., 0., -p1[0]]
else:
[k, b] = np.polyfit(p1, p2, deg=1)
return [k, -1., b]





![]()

损失函数:

λg 用于平衡分类损失和回归损失,设为1
在大多数最先进的检测算法中,训练图像通过平衡采样和hard negative mining 精心处理,以解决目标物体的不平衡分布[9,28]。这样做可能会提高网络性能。然而,使用这些技术不可避免地引入了不可微分的阶段和更多的参数来调谐和更复杂的pipline,这与我们的设计原理相矛盾。
为方便更简单的训练程序,使用[38]中引入的平衡交叉熵,由下式给出:
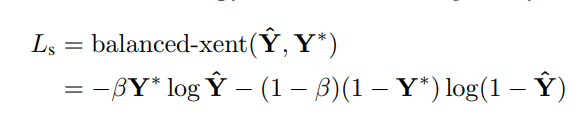
参数β是正样本和负样本之间的平衡因子,由下式给出
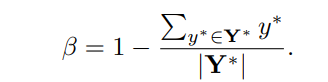
Y*为GT,Y^为预测值
这种平衡的交叉熵损失首先在Yao等人的文本检测中被采用。 [41]作为得分图预测的目标函数。它在实践中运作良好。
以下代码为激活函数为sigmoid时的损失(dice loss),它的收敛速度会比类平衡交叉熵快:
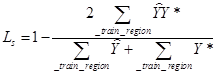
def east_dice_loss(overly_small_text_region_training_mask, text_region_boundary_training_mask, loss_weight, small_text_weight):
def loss(y_true, y_pred):
eps = 1e-5
_training_mask = keras.backend.minimum(overly_small_text_region_training_mask + small_text_weight, 1) * text_region_boundary_training_mask
intersection = backend.reduce_sum(y_true * y_pred * _training_mask)
union = backend.reduce_sum(y_true * _training_mask) + backend.reduce_sum(y_pred * _training_mask) + eps
loss = 1. - (2. * intersection / union)
return loss * loss_weight
return loss if multi_gpu > 1:
from keras.utils import multi_gpu_model
with tf.device('/cpu:0'):
model = model_with_weights(backbone_east(modifier=modifier, config=config),
weights=weights, skip_mismatch=True)
training_model = multi_gpu_model(model, gpus=multi_gpu)
else:
model = model_with_weights(backbone_east(modifier=modifier, config=config),
weights=weights, skip_mismatch=True)
training_model = model
# make prediction model
prediction_model = convert_model(model, 'east')
score_map_loss_weight = keras.backend.variable(0.01, name='score_map_loss_weight')
small_text_weight = keras.backend.variable(0., name='small_text_weight')
# compile model
training_model.compile(
loss=[losses.east_dice_loss(model.inputs[1], model.inputs[2], score_map_loss_weight, small_text_weight),
losses.east_rbox_loss(model.inputs[1], model.inputs[2], small_text_weight, model.inputs[3])],
loss_weights=[1., 1.],
optimizer=keras.optimizers.adam(lr=lr, clipnorm=0.001)
)
return model, training_model, prediction_model回归损失:
文本检测的一个挑战是自然场景图像中文本的大小差别很大。直接使用L1或L2损失进行回归将指导损失偏向更大和更长的文本区域。由于我们需要为大文本区域和小文本区域生成准确的文本几何预测,因此回归损失应该是尺寸不变的。因此,我们再RBOX的AABB部分中的采用IoU-loss,以及再QUAD回归采用尺度标准化平滑L1损失。
RBOX 对于AABB部分,我们采用[46]中的IoU损失,因为它对不同尺度的物体是不变的。
其中R代表预测的AABB几何,R * 代表其相应的ground truth。 很容易看出相交矩形的宽度和高度 |R∩R* | 是
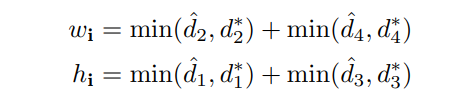
对应的联合区域是
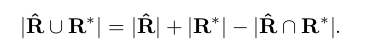
因此,可以容易地计算交叉/联合区域。 接下来,旋转角度的损失计算为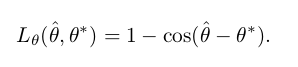
其中θ是对旋转角度的预测,θ*表示GT。 最后,整体几何损失是AABB损失和角度损失的加权和,由下式给出

其中λθ在我们的实验中设置为10。(以下代码设置为20)
请注意,无论旋转角度如何,我们都会计算LAABB 。 当角度被完美预测时,这可以看作是四边形IoU的近似值。 虽然在训练期间并非如此,但它仍然可以为网络施加正确的梯度以学习预测R.
def east_rbox_loss(overly_small_text_region_training_mask, text_region_boundary_training_mask, small_text_weight, target_score_map):
def loss(y_true, y_pred):
# d1 -> top, d2->right, d3->bottom, d4->left
d1_gt, d2_gt, d3_gt, d4_gt, theta_gt = backend.split(value=y_true, num_or_size_splits=5, axis=3)
d1_pred, d2_pred, d3_pred, d4_pred, theta_pred = backend.split(value=y_pred, num_or_size_splits=5, axis=3)
area_gt = (d1_gt + d3_gt) * (d2_gt + d4_gt)
area_pred = (d1_pred + d3_pred) * (d2_pred + d4_pred)
w_union = keras.backend.minimum(d2_gt, d2_pred) + keras.backend.minimum(d4_gt, d4_pred)
h_union = keras.backend.minimum(d1_gt, d1_pred) + keras.backend.minimum(d3_gt, d3_pred)
area_intersect = w_union * h_union
area_union = area_gt + area_pred - area_intersect
L_AABB = -keras.backend.log((area_intersect + 1.0)/(area_union + 1.0))
L_theta = 1 - keras.backend.cos(theta_pred - theta_gt)
L_g = L_AABB + 20 * L_theta
_training_mask = keras.backend.minimum(overly_small_text_region_training_mask + small_text_weight, 1) * text_region_boundary_training_mask
return backend.reduce_mean(L_g * target_score_map * _training_mask)
return loss附Geo损失(代码未实现):
通过添加为单词四边形设计的额外归一化项来扩展smooth-L1损失,这通常在一个更长方向上。 设Q的所有坐标值都是有序集:
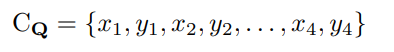
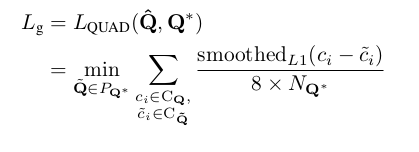
其中归一化项NQ *是四边形的短边长度,由下式给出

且PQ是具有不同顶点排序的Q *的所有等效四边形的集合。 由于公共训练数据集中的四边形注释不一致,因此需要这种排序排列。
模型预测:
class East:
def __init__(self,
weight_path,
show_log = True,
):
self.weight_path = weight_path
self.show_log = show_log
self.model = ResNetBackbone("resnet50").east(isTest=True, input_size=512)
if self.show_log:
print(self.model.summary())
self.model.load_weights(self.weight_path, by_name=True)
def detect_img_path(self, path):
image = read_image_bgr(path)
return self.detect_rgbimg(image)
def detect_rgbimg(self,img):
img_resized, (ratio_h, ratio_w) = self.resize_image(img)
img_resized = preprocess_image(img_resized, mode='tf-1to1')
timer = {'net': 0, 'restore': 0, 'nms': 0}
start = time.time()
score_map, geo_map = self.model.predict(img_resized[np.newaxis, :, :, :])
timer['net'] = time.time() - start
boxes, timer = self.detect(score_map=score_map, geo_map=geo_map, timer=timer)
if boxes is not None:
boxes = boxes[:, :8].reshape((-1, 4, 2))
boxes[:, :, 0] /= ratio_w
boxes[:, :, 1] /= ratio_h
duration = time.time() - start
print('[timing] {}'.format(duration))
return boxes
def detect_with_show(self, path):
image = read_image_rgb(path)
boxes = self.detect_rgbimg(image)
for box in boxes:
# to avoid submitting errors
box = self.sort_poly(box.astype(np.int32))
if np.linalg.norm(box[0] - box[1]) < 5 or np.linalg.norm(box[3] - box[0]) < 5:
continue
cv2.polylines(image, [box.astype(np.int32).reshape((-1, 1, 2))], True, color=(255, 255, 0),
thickness=2)
plt.imshow(image)
plt.show()
def resize_image(self, im, max_side_len=2400):
'''
resize image to a size multiple of 32 which is required by the network
:param im: the resized image
:param max_side_len: limit of max image size to avoid out of memory in gpu
:return: the resized image and the resize ratio
'''
h, w, _ = im.shape
resize_w = w
resize_h = h
# limit the max side
if max(resize_h, resize_w) > max_side_len:
ratio = float(max_side_len) / resize_h if resize_h > resize_w else float(max_side_len) / resize_w
else:
ratio = 1.
resize_h = int(resize_h * ratio)
resize_w = int(resize_w * ratio)
resize_h = resize_h if resize_h % 32 == 0 else (resize_h // 32) * 32
resize_w = resize_w if resize_w % 32 == 0 else (resize_w // 32) * 32
im = cv2.resize(im, (int(resize_w), int(resize_h)))
ratio_h = resize_h / float(h)
ratio_w = resize_w / float(w)
return im, (ratio_h, ratio_w)
def sort_poly(self, p):
min_axis = np.argmin(np.sum(p, axis=1))
p = p[[min_axis, (min_axis + 1) % 4, (min_axis + 2) % 4, (min_axis + 3) % 4]]
if abs(p[0, 0] - p[1, 0]) > abs(p[0, 1] - p[1, 1]):
return p
else:
return p[[0, 3, 2, 1]]
def detect(self, score_map, geo_map, timer, score_map_thresh=0.8, box_thresh=0.1, nms_thres=0.2):
'''
restore text boxes from score map and geo map
:param score_map:
:param geo_map:
:param timer:
:param score_map_thresh: threshhold for score map
:param box_thresh: threshhold for boxes
:param nms_thres: threshold for nms
:return:
'''
if len(score_map.shape) == 4:
score_map = score_map[0, :, :, 0]
geo_map = geo_map[0, :, :, ]
# filter the score map
xy_text = np.argwhere(score_map > score_map_thresh)
# sort the text boxes via the y axis
xy_text = xy_text[np.argsort(xy_text[:, 0])]
# restore
start = time.time()
text_box_restored = restore_rectangle(xy_text[:, ::-1] * 4, geo_map[xy_text[:, 0], xy_text[:, 1], :]) # N*4*2
print('{} text boxes before nms'.format(text_box_restored.shape[0]))
boxes = np.zeros((text_box_restored.shape[0], 9), dtype=np.float32)
boxes[:, :8] = text_box_restored.reshape((-1, 8))
boxes[:, 8] = score_map[xy_text[:, 0], xy_text[:, 1]]
timer['restore'] = time.time() - start
# nms part
start = time.time()
boxes = nms_locality(boxes.astype(np.float64), nms_thres)
# boxes = lanms.merge_quadrangle_n9(boxes.astype('float32'), nms_thres)
timer['nms'] = time.time() - start
if boxes.shape[0] == 0:
return None, timer
# here we filter some low score boxes by the average score map, this is different from the orginal paper
for i, box in enumerate(boxes):
mask = np.zeros_like(score_map, dtype=np.uint8)
cv2.fillPoly(mask, box[:8].reshape((-1, 4, 2)).astype(np.int32) // 4, 1)
boxes[i, 8] = cv2.mean(score_map, mask)[0]
boxes = boxes[boxes[:, 8] > box_thresh]
return boxes, timer
def restore_rectangle_rbox(origin, geometry):
d = geometry[:, :4]
angle = geometry[:, 4]
# for angle > 0
origin_0 = origin[angle >= 0]
d_0 = d[angle >= 0]
angle_0 = angle[angle >= 0]
if origin_0.shape[0] > 0:
p = np.array([np.zeros(d_0.shape[0]), -d_0[:, 0] - d_0[:, 2],
d_0[:, 1] + d_0[:, 3], -d_0[:, 0] - d_0[:, 2],
d_0[:, 1] + d_0[:, 3], np.zeros(d_0.shape[0]),
np.zeros(d_0.shape[0]), np.zeros(d_0.shape[0]),
d_0[:, 3], -d_0[:, 2]])
p = p.transpose((1, 0)).reshape((-1, 5, 2)) # N*5*2
rotate_matrix_x = np.array([np.cos(angle_0), np.sin(angle_0)]).transpose((1, 0))
rotate_matrix_x = np.repeat(rotate_matrix_x, 5, axis=1).reshape(-1, 2, 5).transpose((0, 2, 1)) # N*5*2
rotate_matrix_y = np.array([-np.sin(angle_0), np.cos(angle_0)]).transpose((1, 0))
rotate_matrix_y = np.repeat(rotate_matrix_y, 5, axis=1).reshape(-1, 2, 5).transpose((0, 2, 1))
p_rotate_x = np.sum(rotate_matrix_x * p, axis=2)[:, :, np.newaxis] # N*5*1
p_rotate_y = np.sum(rotate_matrix_y * p, axis=2)[:, :, np.newaxis] # N*5*1
p_rotate = np.concatenate([p_rotate_x, p_rotate_y], axis=2) # N*5*2
p3_in_origin = origin_0 - p_rotate[:, 4, :]
new_p0 = p_rotate[:, 0, :] + p3_in_origin # N*2
new_p1 = p_rotate[:, 1, :] + p3_in_origin
new_p2 = p_rotate[:, 2, :] + p3_in_origin
new_p3 = p_rotate[:, 3, :] + p3_in_origin
new_p_0 = np.concatenate([new_p0[:, np.newaxis, :], new_p1[:, np.newaxis, :],
new_p2[:, np.newaxis, :], new_p3[:, np.newaxis, :]], axis=1) # N*4*2
else:
new_p_0 = np.zeros((0, 4, 2))
# for angle < 0
origin_1 = origin[angle < 0]
d_1 = d[angle < 0]
angle_1 = angle[angle < 0]
if origin_1.shape[0] > 0:
p = np.array([-d_1[:, 1] - d_1[:, 3], -d_1[:, 0] - d_1[:, 2],
np.zeros(d_1.shape[0]), -d_1[:, 0] - d_1[:, 2],
np.zeros(d_1.shape[0]), np.zeros(d_1.shape[0]),
-d_1[:, 1] - d_1[:, 3], np.zeros(d_1.shape[0]),
-d_1[:, 1], -d_1[:, 2]])
p = p.transpose((1, 0)).reshape((-1, 5, 2)) # N*5*2
rotate_matrix_x = np.array([np.cos(-angle_1), -np.sin(-angle_1)]).transpose((1, 0))
rotate_matrix_x = np.repeat(rotate_matrix_x, 5, axis=1).reshape(-1, 2, 5).transpose((0, 2, 1)) # N*5*2
rotate_matrix_y = np.array([np.sin(-angle_1), np.cos(-angle_1)]).transpose((1, 0))
rotate_matrix_y = np.repeat(rotate_matrix_y, 5, axis=1).reshape(-1, 2, 5).transpose((0, 2, 1))
p_rotate_x = np.sum(rotate_matrix_x * p, axis=2)[:, :, np.newaxis] # N*5*1
p_rotate_y = np.sum(rotate_matrix_y * p, axis=2)[:, :, np.newaxis] # N*5*1
p_rotate = np.concatenate([p_rotate_x, p_rotate_y], axis=2) # N*5*2
p3_in_origin = origin_1 - p_rotate[:, 4, :]
new_p0 = p_rotate[:, 0, :] + p3_in_origin # N*2
new_p1 = p_rotate[:, 1, :] + p3_in_origin
new_p2 = p_rotate[:, 2, :] + p3_in_origin
new_p3 = p_rotate[:, 3, :] + p3_in_origin
new_p_1 = np.concatenate([new_p0[:, np.newaxis, :], new_p1[:, np.newaxis, :],
new_p2[:, np.newaxis, :], new_p3[:, np.newaxis, :]], axis=1) # N*4*2
else:
new_p_1 = np.zeros((0, 4, 2))
return np.concatenate([new_p_0, new_p_1])
def restore_rectangle(origin, geometry):
return restore_rectangle_rbox(origin, geometry)以上,主要根据预测得到的得分图和几何图计算得到文本区域的外接旋转矩形
算法检测结果:



参考文章:
https://blog.csdn.net/qq_34886403/article/details/86710446
原文地址:















 5598
5598











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









