










一、SPI简介
1、SPI(Serial Peripheral Interfac)即串行外围设备接口,标准SPI总线由四根线组成:串行时钟线(SCLK)、主机输入/从机输出线(MISO)、主机输出/从机输入线(MOSI)和片选信号(CS)。SPI是一种高速的,全双工,同步的通信总线,并且在芯片的管脚上只占用四根线,节约了芯片的管脚,同时为PCB的布局上节省空间,提供方便,主要应用在EEPROM,FLASH,实时时钟,AD转换器,还有数字信号处理器和数字信号解码器之间。
SPI允许芯片与外部设备以半/全双工、同步、串行方式通信。此接口可以被配置成主模式,并为外部从设备提供通信时钟(SCLK)。接口还能以多主配置方式工作。 它可用于多种用途,包括使用一条双向数据线的双线单工同步传输,还可使用CRC校验的可靠通信。
2、内部结构图
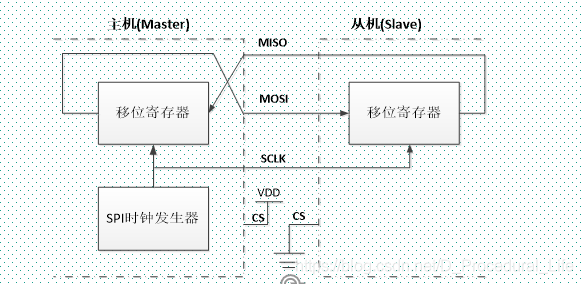
注:
MOSI脚相互连接,MISO脚相互连接。这样,数据在主和从之间串行地传输(MSB位在前)。 通信总是由主设备发起。主设备通过MOSI脚把数据发送给从设备,从设备通过MISO引脚回传数据。这意味全双工通信的数据输出和数据输入是用同一个时钟信号同步的;时钟信号由主设备通过SCLK脚提供。
SPI接口一般使用4条线通信:
(1)MISO: 主设备数据输入,从设备数据输出
(2)MOSI :主设备数据输出,从设备数据输入
(3)SCLK:时钟信号,由主设备产生
(4)CS:从设备片选信号,由主设备控制
3、SPI工作原理总结
(1)硬件上为4根线。
(2)主机和从机都有一个串行移位寄存器,主机通过向它的SPI串行寄存器写入一个字节来发起一次传输。
(3)串行移位寄存器通过MOSI信号线将字节传送给从机,从机也将自己的串行移位寄存器中的内容通过MISO信号线返回给主机。所以两个移位寄存器中的内容就被交换。
(4)外设的写操作和读操作是同步完成的。如果只进行写操作,主机只需忽略接收到的字节;反之,若主机要读取从机的一个字节,就必须发送一个空字节来引发从机的传输。
二、SPI总线数据传输时的时序图(即设备和从设备的SCLK脚、 MISO脚、MOSI脚直接连接的主或从时序图)
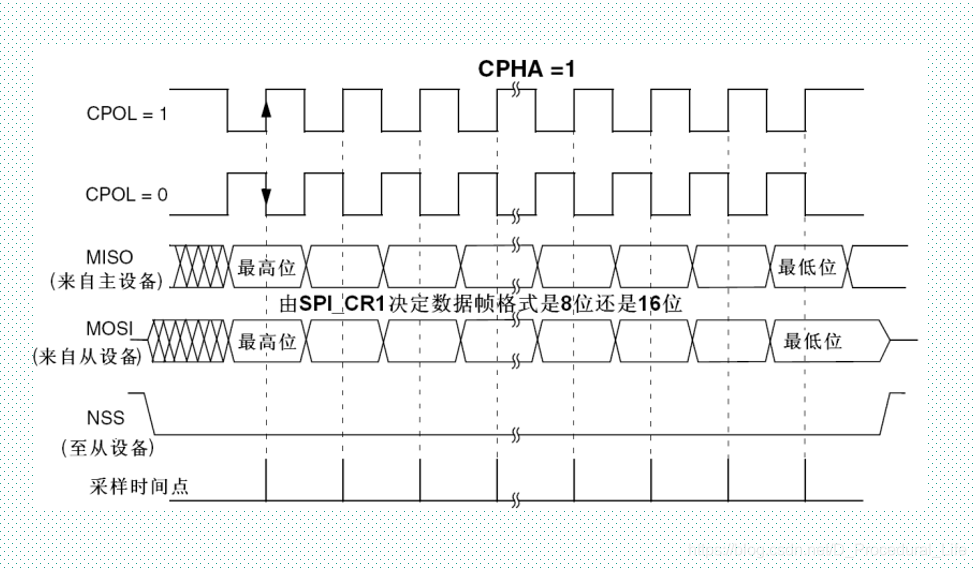
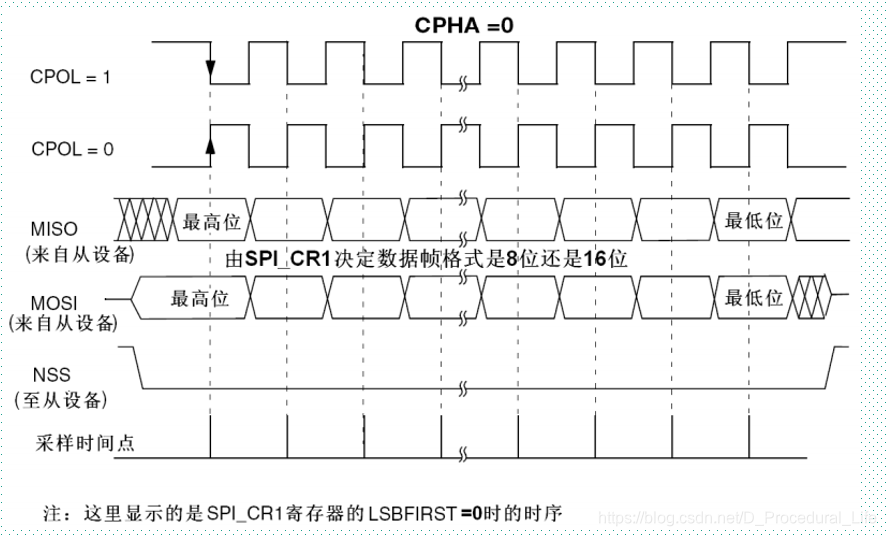
时序解读:
CPOL时钟极性和CPHA时钟相位的组合选择数据捕捉的时钟边沿。故SPI_CR寄存器的CPOL和CPHA位,能够组合成四种可能的时序关系,如上图所示。CPOL(时钟极性)位控制在没有数据传输时时钟的空闲状态电平,此位对主模式和从模式下的设备都有效。如果CPOL被清'0',SCLK引脚在空闲状态保持低电平;如果CPOL被置'1',SCLK引脚在空闲状态保持高电平。如果CPHA(时钟相位)位被置'1',SCLK时钟的第二个边沿(CPOL位为0时就是下降沿,CPOL位为'1'时就是上升沿)进行数据位的采样,数据在第二个时钟边沿被锁存。如果CPHA位被清'0',SCLK时钟的第一边沿(CPOL位为'0'时就是下降沿,CPOL位为'1'时就是上升沿)进行数据位采样,数据在第一个时钟边沿被锁存。故数据输出通过SDO线,数据在时钟上沿或下沿时改变,在紧接着的下沿或上沿被读取。完成一位数据传输,输入也使用同样原理。这样,在至少8次时钟信号的改变(上沿和下沿为一次),就可以完成8位数据的传输。
SCLK信号线只由主设备控制,从设备不能控制信号线。同样,在一个基于SPI的设备中,至少有一个主控设备。这样的传输方式有一个优点,与普通的串行通讯不同,普通的串行通讯一次连续传送至少8位数据,而SPI允许数据一位一位的传送,甚至允许暂停,因为SCLK时钟线由主控设备控制,当没有时钟跳变时,从设备不采集或传送数据。即主设备通过对SCLK时钟线的控制可以完成对通讯的控制。需要注意的是,不同的SPI设备的实现方式不尽相同,主要是数据改变和采集的时间不同,在时钟信号上沿或下沿采集有不同定义。
注:
(1)在改变 CPOL/CPHA 位之前,必须清除SPE位将 SPI 禁止。
(2)主和从必须配置成相同的时序模式。
(3)SCLK 的空闲状态必须和 SPI_CR1 寄存器指定的极性一致 (CPOL为'1'时,空闲时应上拉 SCLK 为高电平;CPOL为'0'时,空闲时应下拉 SCLK 为低电平 ) 。
(4)数据帧格式 (8 位或 16 位 ) 由 SPI_CR1 寄存器的DFF位选择,并且决定发送 / 接收的数据长度。
下面以STM32FI的SPI2为例,分别进行初始化(参数配置)、SPI速度设置(如1、8、16、256分频)、读写一个字节功能的实现,其代码实现参考如下三张图:
1、SPI2的初始化
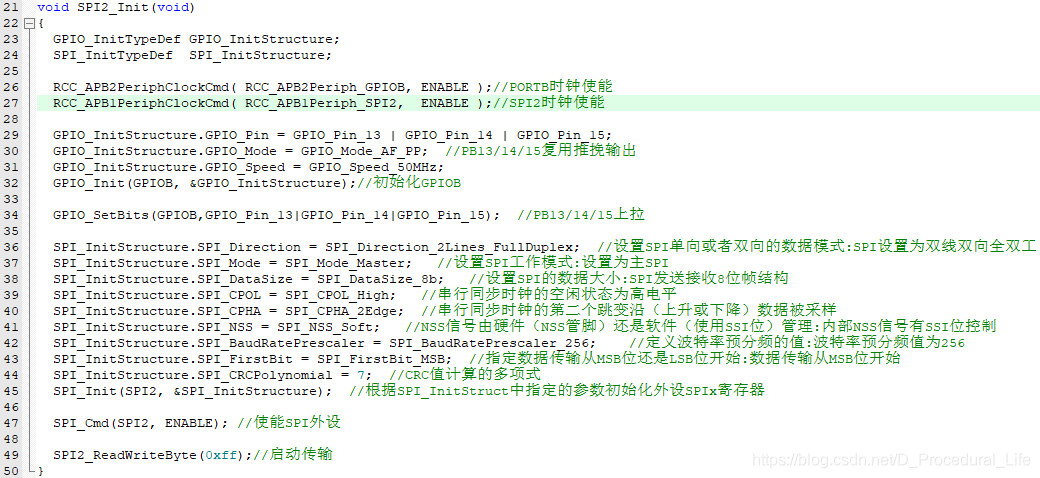
2、SPI速度设置函数

3、读写一个字节功能函数

另:
软件SPI:用IO模拟SPI时序,这个模拟过程全部是CPU在负责执行,为了知稳定得存取数据,你可能会插入软件延时,这个时间在读取数据量不大的情况下并不明显,但是基本上你在读取过程中,其他非中断非异常程序是无法得到执行。
硬件SPI:首先这个数据存道储的过程是不需要CPU参与得,程序中配置好SPI的访问时序,开启中断,CPU就可以在中断函数中搬移数据,省下了软件模拟IO得存取时间。
仔细研究就会发现,CPU在进行SPI中断服务程序还版是需要耽误时间得,这个过程在大数据量传输中还是很耗时,ARM中Cortex-M3内核得处理器在硬件SPI上加入了DMA,这个DMA直接从SPI的数据寄存器,软件配置好DMA之后,基本上整个传输都不要权CPU参与,软件设计得好的话,整个数据传输都不要CPU参与,此时CPU就可以做更多其他有意义的事了。
附:此文为本人经STM32实战后总结所得,欢迎大家参考指点,谢谢。














 3万+
3万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









