







论文链接:UniAD
背景
现代自动驾驶系统的特点是按顺序执行模块化任务
- 为单个任务部署独立的模型,但是他们需要优化的目标函数并不相同
- 设计具有独立头部的多任务范式,他们可能会出现累积错误或者任务协调不足的情况
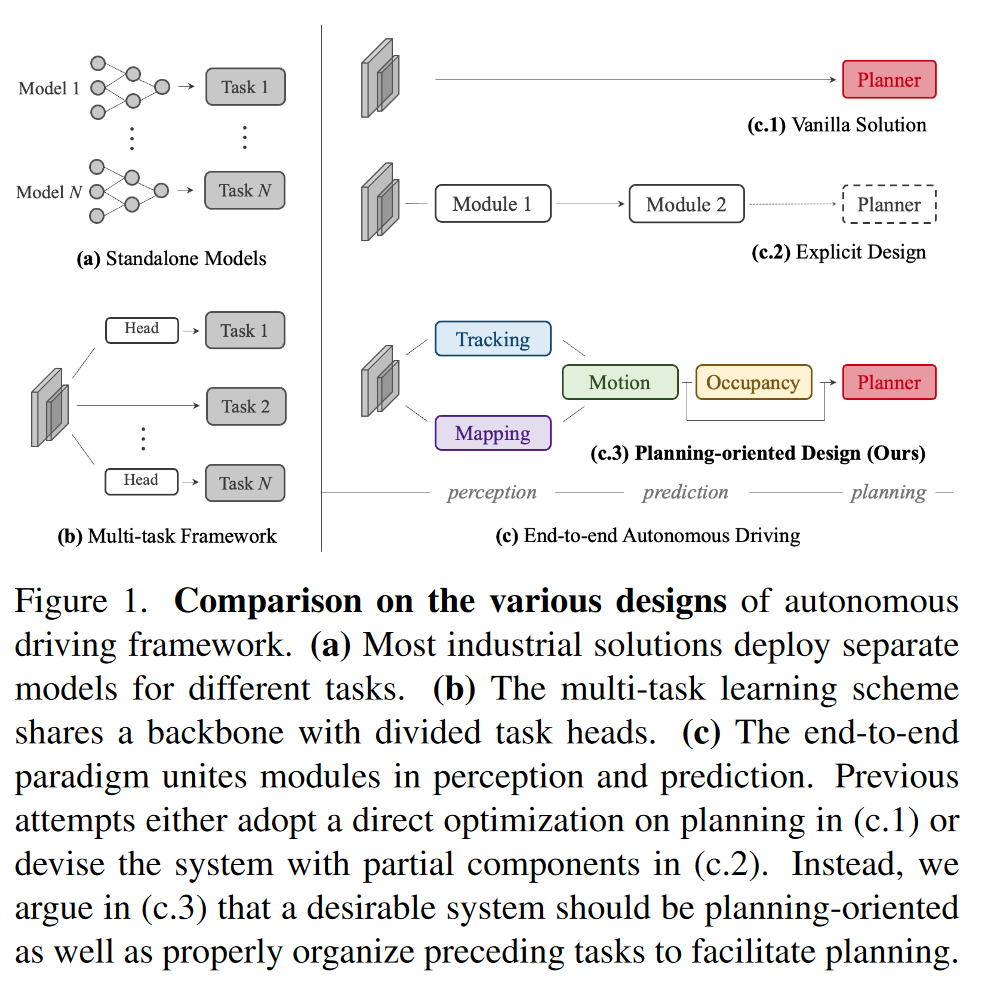
由于自动驾驶任务的快速发展,自动驾驶算法衍生除了一系列的任务:检测、规划、预测算法。 - 如(a)所示,大多数企业为每个任务设计了独立的模型,这样的设计虽然简化了跨团队研发的难度,但也导致了跨模块信息的丢失问题(由于优化目标的孤立性导致的误差累积和特征错位)。
- 如(b)所示,另一种更优雅的方法是将广泛的任务整合到多任务学习的范式中,通过将多个任务特定的头插入到一个共享的特征提取器当中。跨任务的协同训练可以利用抽象特征,毫不费力地扩展到额外的任务上,但是这种方法可能引起“负迁移”。(负迁移:一种学习对另一种学习的干扰或者抑制作用)
- 如(c.1)所示,不采用任何的监督、检测,直接采用端到端的方式对其进行预测,但是此种方法不能保证驾驶的安全性,也不具有可解释性,尤其是在高度动态化的城市场景。
- 如(c.2)所示,一个直观的解决方案是感知周围的物体,预测未来的行为,并计算一个明确的安全动机。但是缺少了某些重要的组件(智能体主体信息和动态信息)
- 如(c.3)所示,UniAD是以规划为导向进行设计的,模型的一个关键组件是连接所有节点的基于查询的设计,与经典的边界框表示相比,查询可以从更大的感受野中获益,并且灵活的对各种交互进行建模和编码,如多个代理之间的关系。
UniAD
主体框架
本文贡献
- 我们接受了一种新的自动驾驶框架,遵循以规划为导向的理念,并证明了有效的任务协调的必要性,而不是独立设计或简单的多任务学习。
- 我们提出了UniAD,一个综合的端到端系统,它利用了广泛的任务跨度。模型的关键组件是将查询设计为连接所有节点的接口。因此,UniAD具有灵活的中间表示和面向规划的多任务知识交换。
- 我们在现实场景的挑战性基准上实例化UniAD。通过广泛的消融,我们验证了我们的方法在各方面都优于以前的最先进的方法。
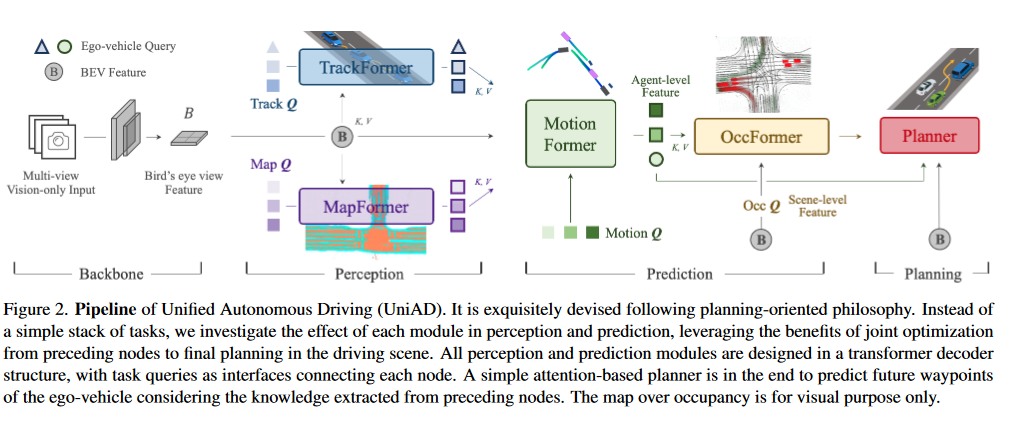
UniAD由四个基于Transformer解码器的观测和预测模块和一个最终的规划模块组成,查询Q可以起到连接的作用,对驾驶场景中实体的不同交互进行建模。(所有感知和预测模块都在Transformer解码器结构中设计,任务查询作为连接每个节点的接口)
首先多相机视角的图片序列被送入特征提取器,经过BEVFormer中的编码器得到BEV特征(也可以采用别的编码器,不一定使用BEV的编码器。在TrackFormer中,称为追踪查询的可学习嵌入从BEV特征中检测和追踪代理。MapFormer中的地图查询用于查询道路元素,来进行场景分割。MotionFormer用于捕智能体之间的交互,并且去映射和预测每个智能体的未来的轨迹。OccFormer采用BEV特征中的B作为query,在保留代理人身份的情况下预测未来的占有率。Planner利用MotionFormer提供的自车查询预测规划结果,并远离OccFormer预测的占用区域以避免碰撞。
Perception: Tracking and Mapping
TrackFormer
它联合进行检测和多目标跟踪,且无需不可微的后处理工作,除了在目标检测任务中使用传统的检测查询外,还引入了额外的跟踪查询来跨帧跟踪代理:在每个时间帧中,初始化的检测查询负责检测首次被感知的代理,而跟踪查询则对前一帧中检测到的代理进行建模操作。两者都是通过BEV特征来进行捕获代理抽象特征。此外还在查询集中引入一个显示的自车查询,对自动驾驶车辆本身进行显示建模,并进一步用于规划。
MapFormer
我们将道路要素稀疏表示为地图查询,以帮助下游运动预测,并对位置和结构知识进行编码。对于自动驾驶场景,我们将车道,斑马线等物体设定为things,并将那些可以移动的物体设为stuff。MapFormer具有N个堆叠层,每层的输出结果都是有监督的,但是只有最后一层更新的查询 Q M Q_M QM被用于进行代理-地图交互。
Prediction: Motion Forecasting
通过先前的抽象查询 Q A , Q M Q_A,Q_M QA,QM,MotionFormer可以预测所有代理人未来的多模态运动轨迹(qiank个可能的轨迹,以场景为中心的方式),该范式在单一前向通道的框架下产生多智能体轨迹,极大地节省了将整个场景对齐到每个智能体坐标的计算成本。同时,在MotionFormer中利用自我车辆查询,将自我车辆和其他智能体进行交互。其中运动预测以稀疏的航路点输出的形式保留智能体的身份。
MotionFormer
MotionFormer由N个层结构组成,每个层抓获三种交互信息:代理人-代理人;代理人-地图;代理人-目标点(目标点是预定的位置,预定轨迹的精细化)
Q
(
a
/
m
)
=
M
H
C
A
(
M
H
S
A
(
Q
)
,
Q
A
/
Q
M
)
Q_(a/m)=MHCA(MHSA(Q),Q_A/Q_M)
Q(a/m)=MHCA(MHSA(Q),QA/QM)
对于每一个motion query,他首先通过多头自注意力机制进行自我交互,之后分别和
Q
A
Q_A
QA、
Q
M
Q_M
QM进行多头交叉注意力交互。同时关注预定的位置(目标点),对预测的轨迹进行精化也很重要,我们通过DeformAttn机制来确定agent-goal之间的关系,
Q
g
=
D
e
f
o
r
m
A
t
t
n
(
Q
,
x
^
T
l
−
1
,
B
)
Q_g=DeformAttn(Q,\hat{x}_T^{l-1},B)
Qg=DeformAttn(Q,x^Tl−1,B)
其中
x
^
T
l
−
1
\hat{x}_T^{l-1}
x^Tl−1表示上一层预测出的轨迹。所有的交互都是并行运行的,最终生成的
Q
a
,
Q
m
,
Q
g
Q_a,Q_m,Q_g
Qa,Qm,Qg经过拼接后通过MLP结构,生成
Q
c
t
x
Q_{ctx}
Qctx,
Q
c
t
x
Q_{ctx}
Qctx发送到后续层进行细化,或者在最后一层作为检测结果进行解码操作。
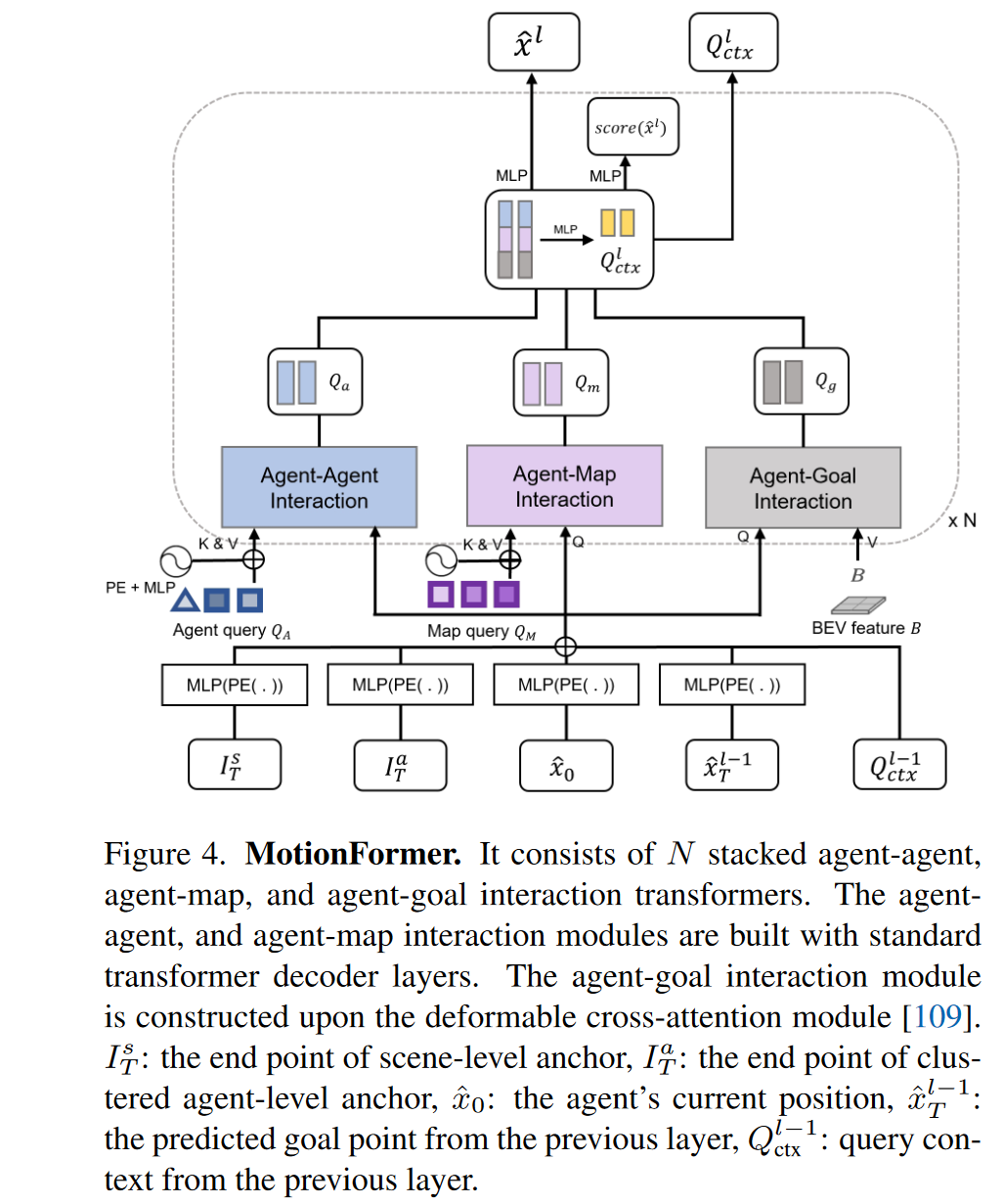
motion query: MotionFormer每一层的输入查询称为运动查询,由两部分组成,前一层产生的查询
Q
c
t
x
Q_{ctx}
Qctx和查询位置
Q
p
o
s
Q_{pos}
Qpos,
其中
Q
p
o
s
Q_{pos}
Qpos对位置i进行了四种整合:
- 场景级锚点的位置(全局视角下的先验运动统计)
- Agent级锚的位置(局部坐标下的可能意图)
- 智能体的当前位置(为每个智能体提供定制的位置嵌入)
- 预测的目标点(由粗到细的方式作为逐层优化的动态描点)
Q p o s = M L P ( P E ( I s ) ) + M L P ( P E ( I a ) ) + M L P ( P E ( x ^ 0 ) ) + M L P ( P E ( x ^ T l − 1 ) ) Q_{pos} = MLP(PE(I^s)) + MLP(PE(I^a)) + MLP(PE(\hat{x}_0)) + MLP(PE(\hat{x}^{l-1}_T)) Qpos=MLP(PE(Is))+MLP(PE(Ia))+MLP(PE(x^0))+MLP(PE(x^Tl−1))
Prediction: Occupancy Prediction
占用栅格地图是一个离散化的BEV表示,其中每个单元格都持有一个表示是否被占用的概率,而占用预测任务是发现栅格地图在未来如何变化,以前的网络由于将BEV特征整体压缩送入RNN层,因此是代理状态不可知类型,由于缺少代理层面的信息,从全局层面上预测代理人的运动轨迹是十分具有挑战性的。
OccFormer在两个方面同时包含场景级信息和代理级信息。
- 密集场景特征在展开到未来视域时通过精心设计的注意力模块获取代理级特征;
- 通过代理级特征和稠密场景特征之间的矩阵乘法,我们可以很容易地产生实例级占用率,而无需繁重的后处理。
OccFormer
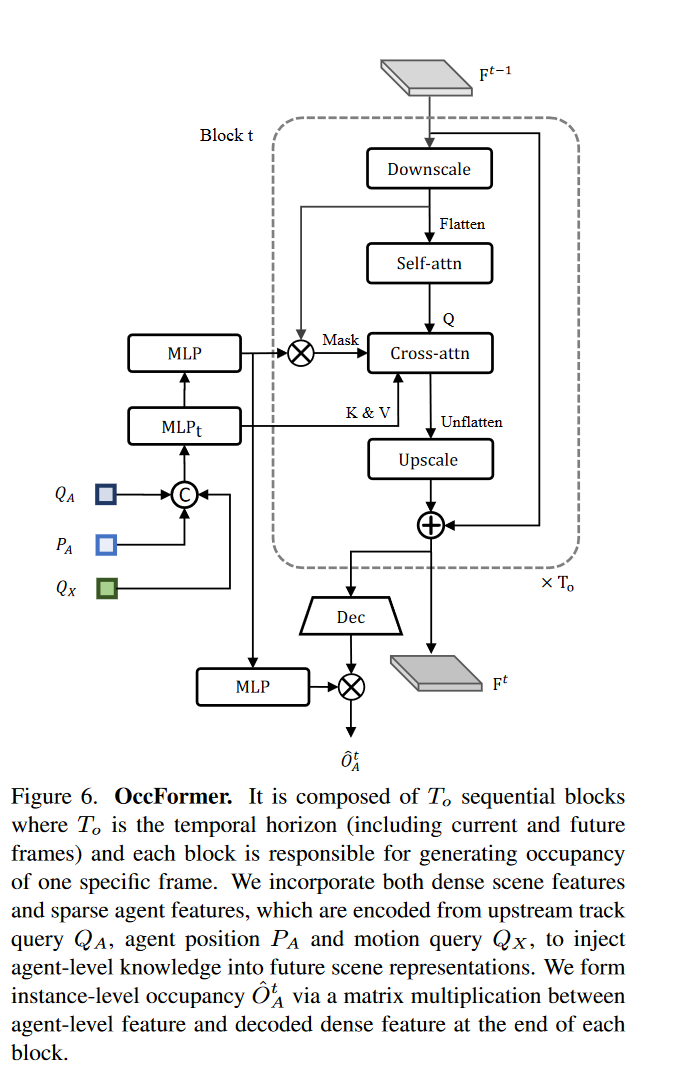
OccFormer由
T
0
T_0
T0个连续块组成,每一个块都将上一层的丰富的代理人特征KaTeX parse error: Expected group after '_' at position 3: Gt_̲和状态(稠密特征)
F
t
−
1
F_{t - 1}
Ft−1作为输入,并且综合考虑实例级和场景级信息,生成时步t的
F
t
F_t
Ft。
为了得到具有动力学和空间先验的智能体特征
G
t
G_t
Gt,我们在模态维度上对MotionFormer的运动查询进行最大池化操作,记为
Q
X
∈
R
N
a
×
D
,其中
D
为特征维度,之后和
Q_X∈R^{N_a × }D,其中D为特征维度,之后和
QX∈RNa×D,其中D为特征维度,之后和Q_A,P_A$拼接,最后经过MLP结构
G
t
=
M
L
P
(
[
Q
A
,
P
A
,
Q
X
]
)
,
t
=
1
,
.
.
.
,
T
0
G^t = MLP([Q_A,P_A,Q_X]),t=1,...,T_0
Gt=MLP([QA,PA,QX]),t=1,...,T0
对于场景信息,为了提高训练效率将BEV特征B的尺度降到1/4作为第一块的输入
F
0
F_0
F0,为了进一步保存训练记忆,每个块遵循下采样-上采样的方式,中间有一个注意力模块,以在1 / 8降尺度特征处进行像素-代理交互,记为
F
d
s
t
F^t_{ds}
Fdst
像素代理交互:为了在预测未来占有率是统一场景和智能体级别的理解,我们将稠密特征
F
d
s
t
F^t_{ds}
Fdst作为查询,实例级特征作为键和值来随时间更新稠密特征。具体来说,
F
d
s
t
F^t_{ds}
Fdst通过一个自注意力层来建模远程网格之间的响应,然后通过一个交叉注意力层来建模代理特征KaTeX parse error: Expected group after '_' at position 2: G_̲t和每网格特征之间的交互,生成
D
d
s
t
D^t_{ds}
Ddst,
D
d
s
t
D^t_{ds}
Ddst被上采样到B的1 / 4大小。我们进一步将
D
d
s
t
D^t_{ds}
Ddst与块输入
F
t
−
1
F_{t - 1}
Ft−1相加作为残差连接,并将得到的特征
F
t
F_t
Ft传递给下一个块。
D
d
s
t
=
M
H
C
A
(
M
H
S
A
(
F
d
s
t
)
,
G
t
,
a
t
t
n
m
a
s
k
=
O
m
t
)
D_{ds}^t = MHCA(MHSA(F_{ds}^t),G^t,attn_mask = O_m^t)
Ddst=MHCA(MHSA(Fdst),Gt,attnmask=Omt)
其中
O
m
t
O_m^t
Omt由密集特征
F
d
s
t
F^t_{ds}
Fdst和代理级特征
M
t
M^t
Mt矩阵相乘得到,
M
t
=
M
L
P
(
G
t
)
M^t = MLP(G^t)
Mt=MLP(Gt)
实例级的占用:表示每个代理人被保留下来的占有率。在形式上,为了得到BEV特征B原始尺寸H × W的占用预测,场景级特征
F
t
F^t
Ft通过卷积解码器上采样到
F
d
e
c
t
∈
R
C
×
H
×
W
F^t_{dec}∈R^{C × H × W}
Fdect∈RC×H×W。对于代理级特征,我们进一步通过另一个MLP将粗掩码特征
M
t
M_t
Mt更新为占用特征
U
t
∈
R
N
a
×
C
U_t∈ R^{N_a × C}
Ut∈RNa×C。
O
^
A
t
=
U
t
⋅
F
d
e
c
t
\hat{O}^t_A = U^t · F^t_{dec}
O^At=Ut⋅Fdect
Planning

在没有高清地图和预定义路线的情况下进行规划,通常需要一个高级别的命令来确定前进的方向。因此我们将原始导航信号转换为三个可学习的嵌入(命令嵌入),由于来自MotionFormer的自我车辆查询已经表达了其多模态意图,我们为其配备了命令嵌入以形成"规划查询"。我们对BEV特征B进行规划查询,使其感知周围环境,然后解码到未来的路点。
具体来说,我们的规划器采用跟踪和运动预测模块生成的自车查询,分别用蓝色三角形和黄色矩形表示。这两个查询以及命令嵌入通过MLP层进行编码,通过最大池化层,选择最显著的模态特征并进行聚合。为了嵌入位置信息,我们将具有学习位置嵌入的特征和具有正弦位置嵌入的BEV特征进行融合。然后,我们用MLP层回归规划轨迹,同时我们设计了用于避障的碰撞优化器。














 1006
1006











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









