






Dify系列推荐阅读:
Dify 0.15.3版本 本地部署指南_dify0.15.3-CSDN博客
使用pycharm社区版调试DIFY后端python代码_dify项目debug-CSDN博客
背景
在AI技术快速发展的背景下,开发者面临着众多选择。Dify作为主流的AI开发平台工具,具有独特的优势。通过Dify系统架构分析,有助于用户更好地了解工具,从而为研发过程提供有力支持。
Dify是一款功能强大的AI开发平台工具,它以其简洁的界面设计和强大的实用性著称。平台提供了丰富且强大的算法库和模型训练功能,使得用户能够快速上手,轻松构建出符合需求的AI应用。这些算法库涵盖了图像识别、语音识别、自然语言处理等多个方面,为用户提供了全面的AI解决方案。用户可以通过简单的拖拽和点击,快速搭建出完整的AI应用,极大地提高了开发效率。
Dify架构特点
在人工智能领域,模型的复杂度和大规模数据的需求是两大核心挑战。为了有效应对这两大挑战,Dify采取了一系列独特的策略,特别是在模块化设计、可扩展性以及兼容性方面展现出了显著的优势。
- 在模块化设计方面,Dify将系统划分为多个独立的功能模块。这些模块包括数据预处理、模型训练、模型部署等,每个模块都有其特定的功能和接口。这种设计使得这些模块可以独立开发和测试,也可以根据业务需求进行组合和扩展。通过灵活的组合和扩展,Dify能够快速地适应不同的业务场景,满足不同的需求。
- 在可扩展性方面,Dify的架构支持根据需求动态添加或删除模块。随着业务的发展,如果原有的模块已经无法满足需求,Dify可以快速地添加新的模块,而不需要对原有的系统进行大规模的修改。Dify的计算资源也可以进行动态扩展。通过调整计算资源的分配,可以优化系统,以满足不同场景下的性能要求。
- 在兼容性方面,Dify展现出了强大的能力。它能够兼容多种数据来源和格式,如结构化数据、非结构化数据、文本数据等。这意味着Dify可以灵活地处理各种类型的数据,而不需要对原有的数据进行特殊的处理或转换。
Dify核心架构
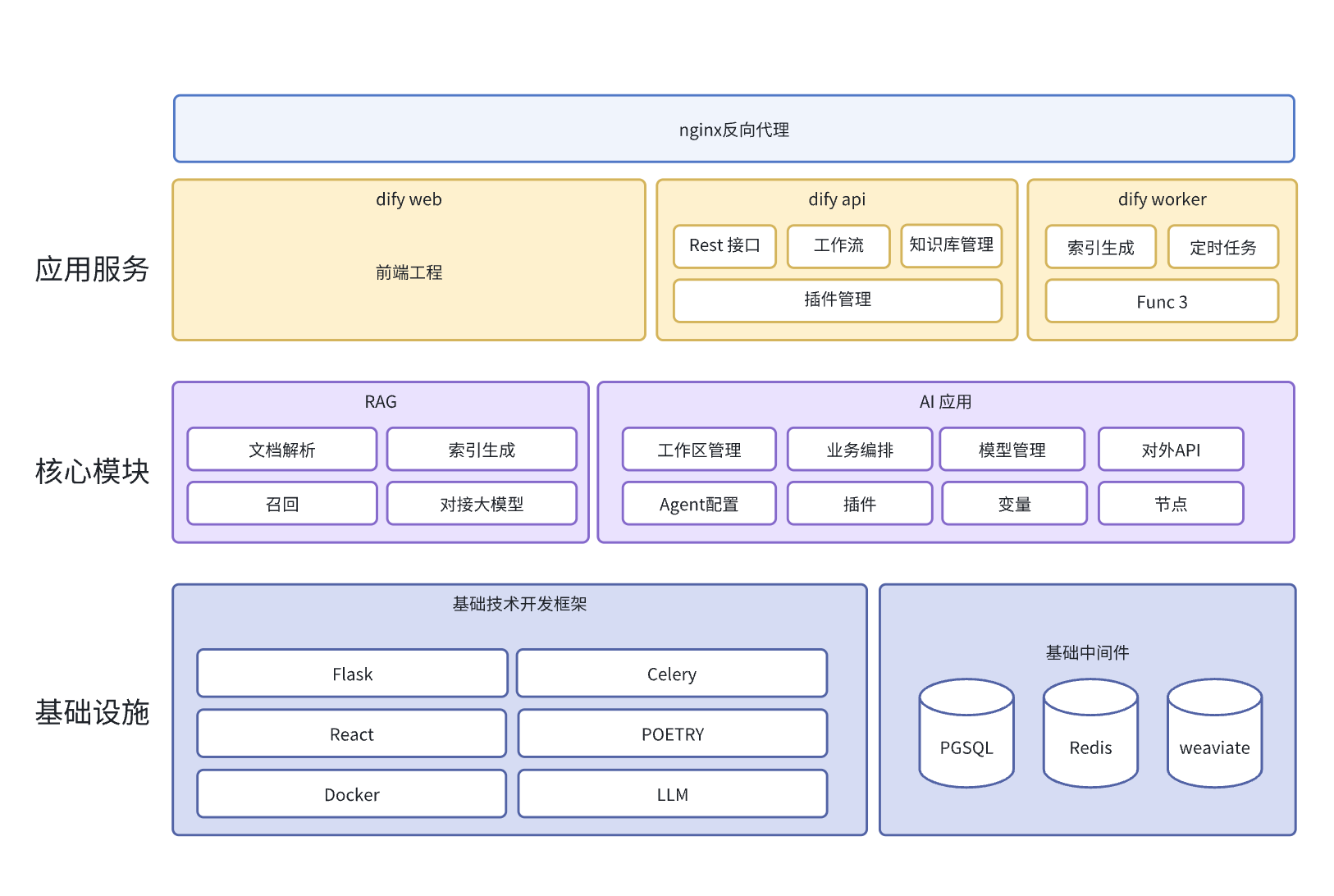
dify一共有三个核心服务:前端、接口服务dify api、异步任务服务dify worker
这里主要介绍一下技术栈:
- Flask:Python的web的开发框架
- Celery:Python的分布式消息队列框架,用于异步任务开发
- Poetry:Python的依赖管理工具
- Docker:容器化
- LLM:各种大模型的对接
- PGSql:关系型数据库
- Redis:缓存中间件
- weaviate:向量数据库
Dify核心模块
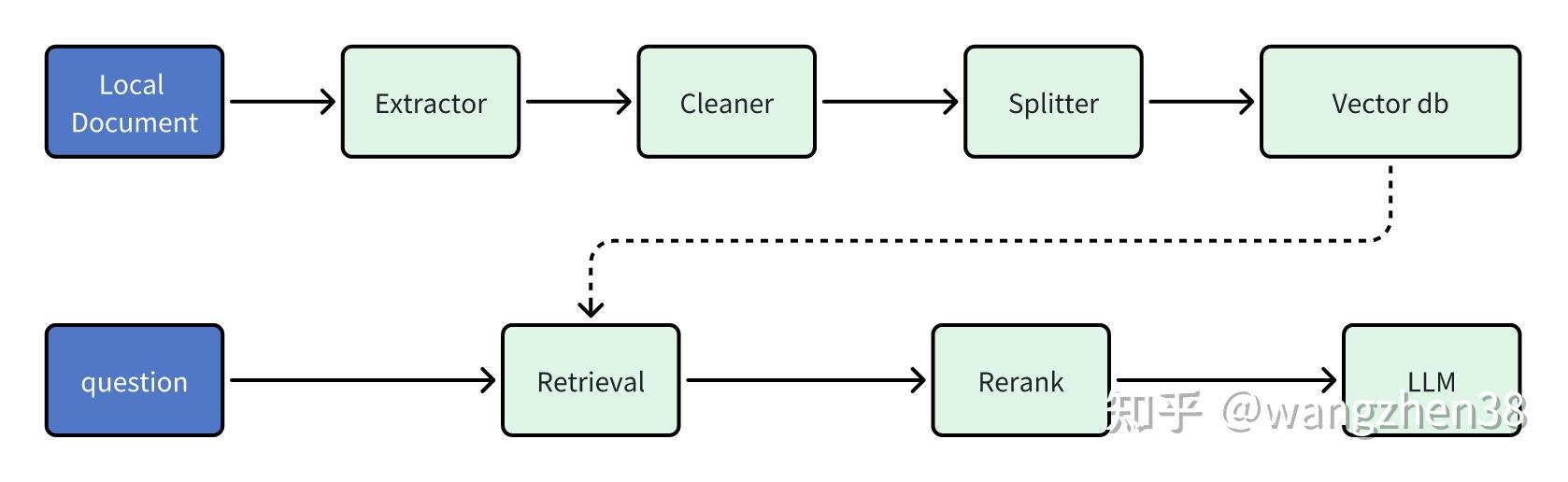
RAG模块
rag模块实现了多种文档格式的解析、清洗、分段、关键字提取以及向量语义入库。核心模块可以细分为文档解析、索引构建、召回测试、对接大模型。
● 文档解析:
支持txt、pdf、word等等多种文件,使用的是python里面的各种开源框架进行解析。
● 索引构建:
将文档解析的文本提取关键字,清洗、分段,然后根据配置进行语义向量计算并保存到向量数据库。
● 召回:
根据配置的TopN实现多路的召回测试,在agent使用时,提供Top N个文本片段作为prompt的上下文,放到<Context>标签中
● 对接大模型:
配置embadding模型,调用embadding模型的通用REST接口,获取对应文本片段的语义向量并进行保存。
工作流模块
● 工作流的特性
主要有节点自动流转、节点停留、条件流转,同时支持不同节点类型,每个节点有对应的输入和输出。
● 支持的节点类型
目前已知的节点类型如下,无实现的技术难度。
这里核心的节点是LLM节点,用于编辑使用什么模型以及需要提什么问题给大模型。
知识检索节点,用于将用户的提问问题和知识库的知识进行匹配的节点,使大模型拥有知识库上下文的节点。
问题分类器,根据节点配置,配置大模型对应的分类输出。
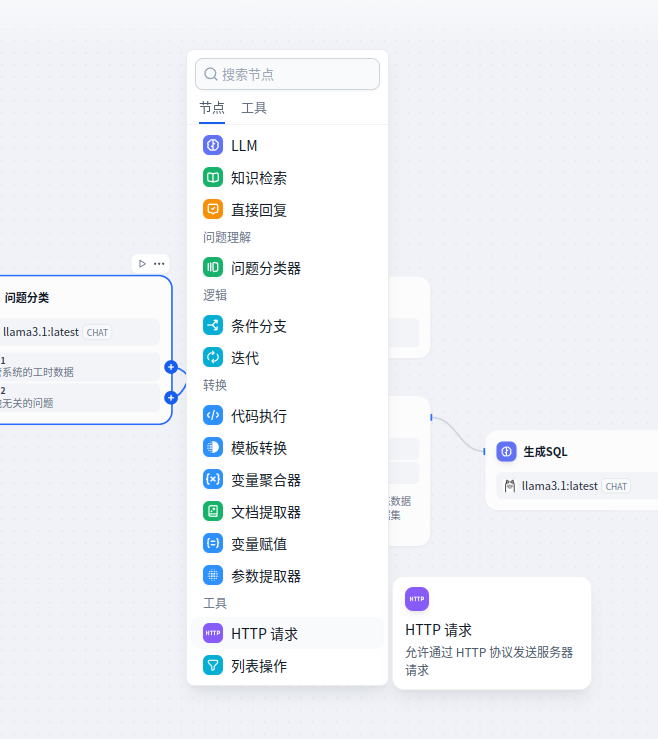
● 变量系统
如下图,用于提供每个节点配置prompt、配置输入、配置输出的一项核心功能,核心本质是根据不同的节点类型,作为节点的上下文,对这个节点的输入和输出进行字符串替换,无实现的技术难度。
扩展发散一下,这里的变量也可能是低代码平台的字段
● 调试
实际上调试使用的功能就是工作流节点的节点停留,可以调试从开头节点到当前节点的实现逻辑,并将每个节点的运行信息显示在前端的一个基础功能,无实现的技术难度。
大模型对接与管理
市面大模型的配置与接入,也不存在技术难度。
每个模型的运行时都会提供Rest API以及对应的SDK,例如ollama作为模型的运行框架,只需要接入ollama的REST API,以及完成页面配置需要的文件即可。
插件实现模块
● 核心实现过程如下:

使用python作为插件语言,扫描内部的dify/api/core/tools/provider/builtin目录,以获取内置插件,开源版本需要重启核心api服务。本质上是使用脚本引擎实现的,组件定义使用的是yaml作为格式。我们可以自研实现这块完全的逻辑,或者实现其他类似的插件系统,以复用当前的dify插件。
插件的本质是通过YAML文件定义插件的服务名、组织、以及对应的实现脚本。
如下:
aws.yaml的内容
identity:
author: AWS
name: aws
label:
en_US: AWS
zh_Hans: 亚马逊云科技
pt_BR: AWS
description:
en_US: Services on AWS.
zh_Hans: 亚马逊云科技的各类服务
pt_BR: Services on AWS.
icon: icon.svg
tags:
- search
credentials_for_provider:aws.py的内容
from core.tools.errors import ToolProviderCredentialValidationError
from core.tools.provider.builtin.aws.tools.sagemaker_text_rerank import SageMakerReRankTool
from core.tools.provider.builtin_tool_provider import BuiltinToolProviderController
class SageMakerProvider(BuiltinToolProviderController):
def _validate_credentials(self, credentials: dict) -> None:
try:
SageMakerReRankTool().fork_tool_runtime(
runtime={
"credentials": credentials,
}
).invoke(
user_id="",
tool_parameters={
"sagemaker_endpoint": "",
"query": "misaka mikoto",
"candidate_texts": "hello$$$hello world",
"topk": 5,
"aws_region": "",
},
)
except Exception as e:
raise ToolProviderCredentialValidationError(str(e))
总结
Dify 是一款功能强大的 AI 开发平台工具,以其模块化设计、高可扩展性和广泛兼容性著称。其架构分为应用服务、核心模块和基础设施三部分,支持从数据预处理到模型部署的全流程开发。核心模块包括 RAG(支持多格式文档解析、索引构建和语义向量入库)、工作流(支持节点自动流转和条件分支)以及插件系统(基于 YAML 和 Python 实现)。Dify 兼容多种数据格式和大模型(如通过 REST API 对接 LLM),并利用 Flask、Celery、Docker 等技术栈实现高效开发与部署。此外,平台通过 PGSQL、Redis 和向量数据库(如 Weaviate)管理数据,满足高性能需求。Dify 的灵活性和易用性使其能够快速适应不同业务场景,显著提升 AI 应用的开发效率。
作者:道一云低代码
作者想说:喜欢本文请点点关注~


















 366
366

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











