






小白一名,记录踩坑过程以及经验总结,方便自己查看问题,还有理清自己的思路
大家好像都是导入pycharm做的,所以我安装了社区版的pycharm,参考了以下博客:
在Ubuntu中安装并配置Pycharm教程_ubuntu安装pycharm-CSDN博客
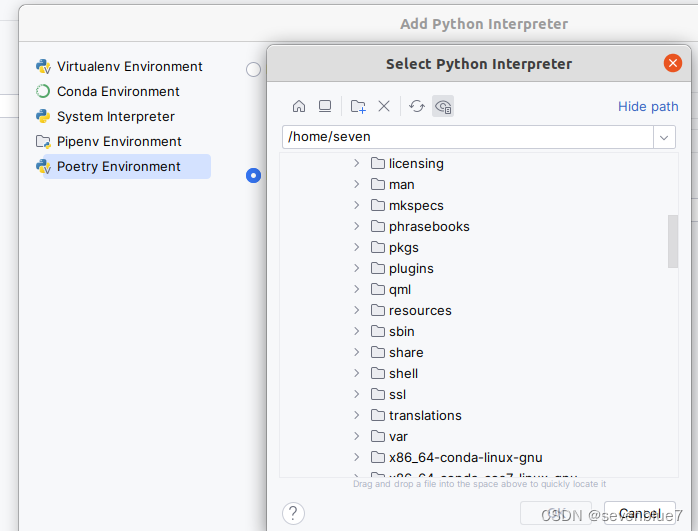
这里我找不到自己虚拟环境的位置了,记录一下,免得忘记:
![]()
不知道当初安装的时候为什么放在了这个目录。。。
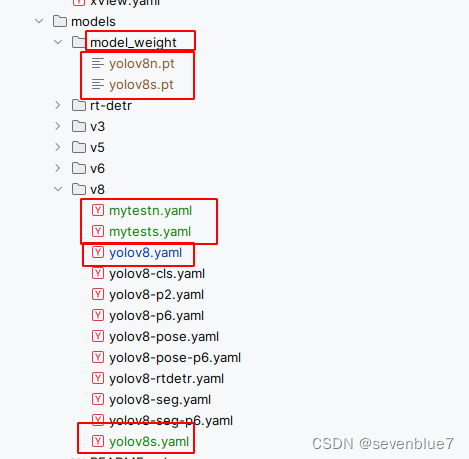
目前修改了三个文件:在cfg/models文件夹下创建了一个model_weight文件夹用于存放使用的权重文件,包括n、s两种型号,在v8目录下存放了yolov8n.yaml、yolov8s.yaml配置文件。
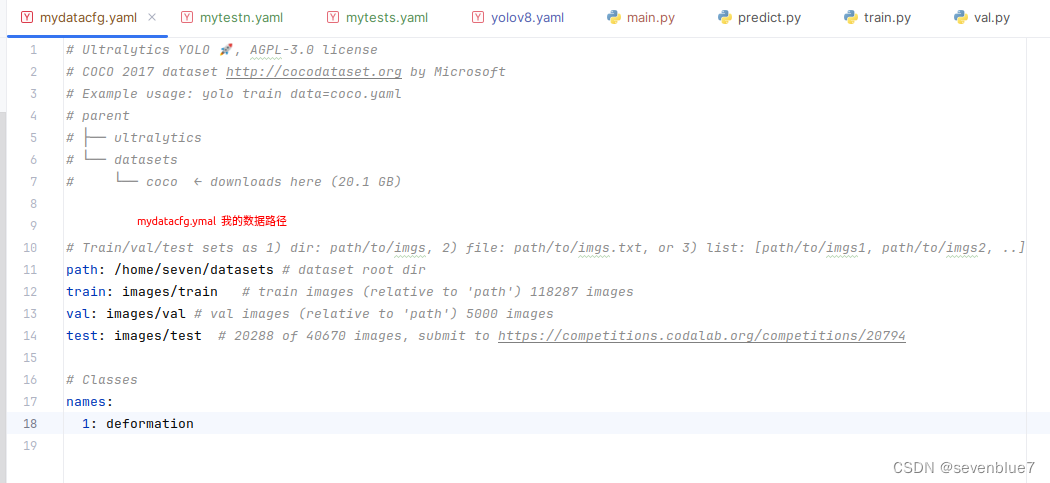
在datasets目录下,写了一个mydatacfg.yaml文件,里面是图片数据路径以及名称,这就是我自己的数据集的描述文件

一训练就出问题,百度了一通,A说改这个,B说改那个,改来改去还是一样的报错,现在看到这个报错就想吐

关于这个问题,看了github上的回答和其他博主的问题,感觉还是我数据集标签的问题,我猜测是标签的问题,具体是不是还要实验一下。不过有的博主说可能是pytorch版本的问题
yolov8自定义数据训练报错排查(CUDA error: an illegal memory access was encountered)-CSDN博客
在环境配置上面花了很多时间,其实根本不用这么费劲,在youtube上学习了怎么在Googlecolabtorary上训练模型,我的天,真的是后悔怎么没有早点发现这个平台,省了一堆力气,但是后面又发现了一个问题,就是我关了电脑:再次运行的时候,保存训练结果文件的文件夹:runs\detect\train就没了,又得重新训练,免费版最多运行12小时。网上也有很多踩坑分享,遇到了再继续学习。
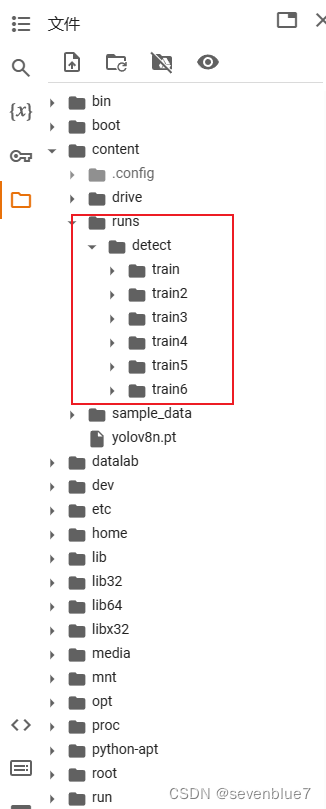

 上面的这一张图片这是知乎上这个博主的经验: 苦逼学生党的Google Colab使用心得 - 知乎 (zhihu.com)
上面的这一张图片这是知乎上这个博主的经验: 苦逼学生党的Google Colab使用心得 - 知乎 (zhihu.com)
官方对于google colabtorary的介绍:Google Colab
最初是在B站上看到个印度youtuber讲的,就看了前面部分,没有看后面,真的是非常后悔,白白浪费我一周时间。好不容易做好配置,结果不能用,现在也没改好,不过我大致有一个猜测,感觉是我的label 标签的问题,其实今天在googlecol上训练模型也报错来着,在github上找到了问题的解决方法。这个产品就是非常方便,代码运行完了还会有弹出的框提示。

针对colab最多支持运行12小时的问题:
1、没有花钱办不到的事情,购买colab pro版的。但是我的任务没有那么大,用不着(一个穷学生不太想花钱)
2、加checkpoints(这个还不知道怎么操作的,后面如果要训练更大的检测模型,再继续学习)
在googlecol上的报错:
1、Transport endpoint is not connected 这个应该是网络问题,重新装载谷歌硬盘。
ps:云端笔记本中的路径表达式的根路径都是/content/drive

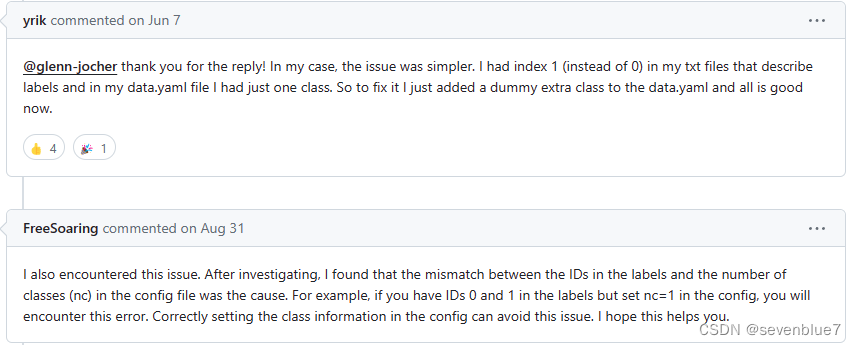
2、IndexError: index 1 is out of bounds for dimension 1 with size 1
这个应该是我lable文件的问题,因为我需要检测的目标只有一类,在txt文本文件中,第一列我开始都给的1,后面改为了0,正常运行了,也有的说可以改nc值,如下:
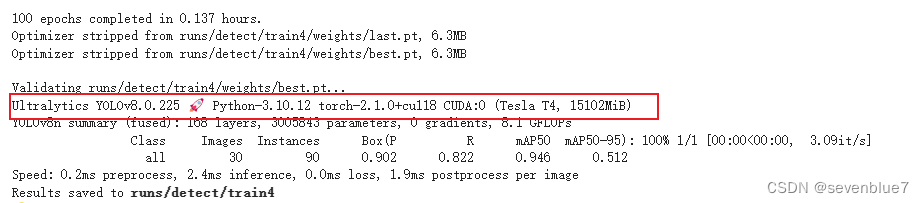
3、 Stopping training early as no improvement observed in last 50 epochs.
![]()
Best results observed at epoch 6, best model saved as best.pt. To update EarlyStopping(patience=50) pass a new patience value, i.e. `patience=300` or use `patience=0` to disable EarlyStopping
早停,通过检测验证集上的性能是否有提升,来决定是否继续训练或者丢弃之前的模型并重新从头开始训练。当模型训练得到一个比较高的准确率后,一般继续训练直至模型完全收敛或者出现过拟合。但是,如果训练不慎中止,模型可能会进入一个局部最优点,最终导致欠拟合甚至泛化能力差,早停就是避免这种情况的一种方法。
把patience值改为了 300,但是感觉这个patience值应该不能给的这么随意吧。以下是chatgpt的回答:
在训练神经网络时,
patience值通常用于控制早停(early stopping)策略,即在验证集上监测性能,如果性能在连续的若干次迭代中没有提升,就提前停止训练,以避免过拟合。
patience的值表示在验证集上性能没有提升的连续轮数。如果patience设置得过大,模型可能会在性能达到最佳时继续进行训练,从而浪费时间和计算资源。过大的patience可能导致模型在过拟合之前浪费过多的训练时间。另一方面,
patience设置得过小可能导致模型在验证性能稍微下降时就提前停止,从而可能错过在稍后迭代中性能进一步提升的机会。通常建议根据具体问题和数据集的特点来调整
patience的值。一种常见的做法是观察模型在验证集上的学习曲线,了解性能何时趋于稳定或开始下降。根据这些观察,选择一个合适的patience值。如果模型的性能曲线波动较大,可以适当增加patience,以防止提前停止。总体而言,
patience的选择需要在训练过程中进行调试,并结合实际情况来做出
import locale
def getpreferredencoding(do_setlocale = True):
return "UTF-8"
locale.getpreferredencoding = getpreferredencoding
!yolo task=detect mode=train model=/content/runs/detect/train7/weights/best.pt data=/content/drive/MyDrive/datasets/mydata.yaml batch=60 epochs=100 imgsz=640 patience=300参考
一些比较详细的关于google colab的教程
Google Colab 快速上手 - 知乎 (zhihu.com)
Colab运行报错:“Transport endpoint is not connected“_colab无法连接到代码执行程序_能小胖的博客-CSDN博客
苦逼学生党的Google Colab使用心得 - 知乎 (zhihu.com)
用Colab训练机器学习的经验以及踩坑的那些事_https://colab.research.google.com/notebooks/intro.-CSDN博客Colab使用教程(超级详细版)及Colab Pro/Pro+评测 - 知乎 (zhihu.com)
















 311
311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









