








 超级会员免费看
超级会员免费看


一、文章主要内容总结
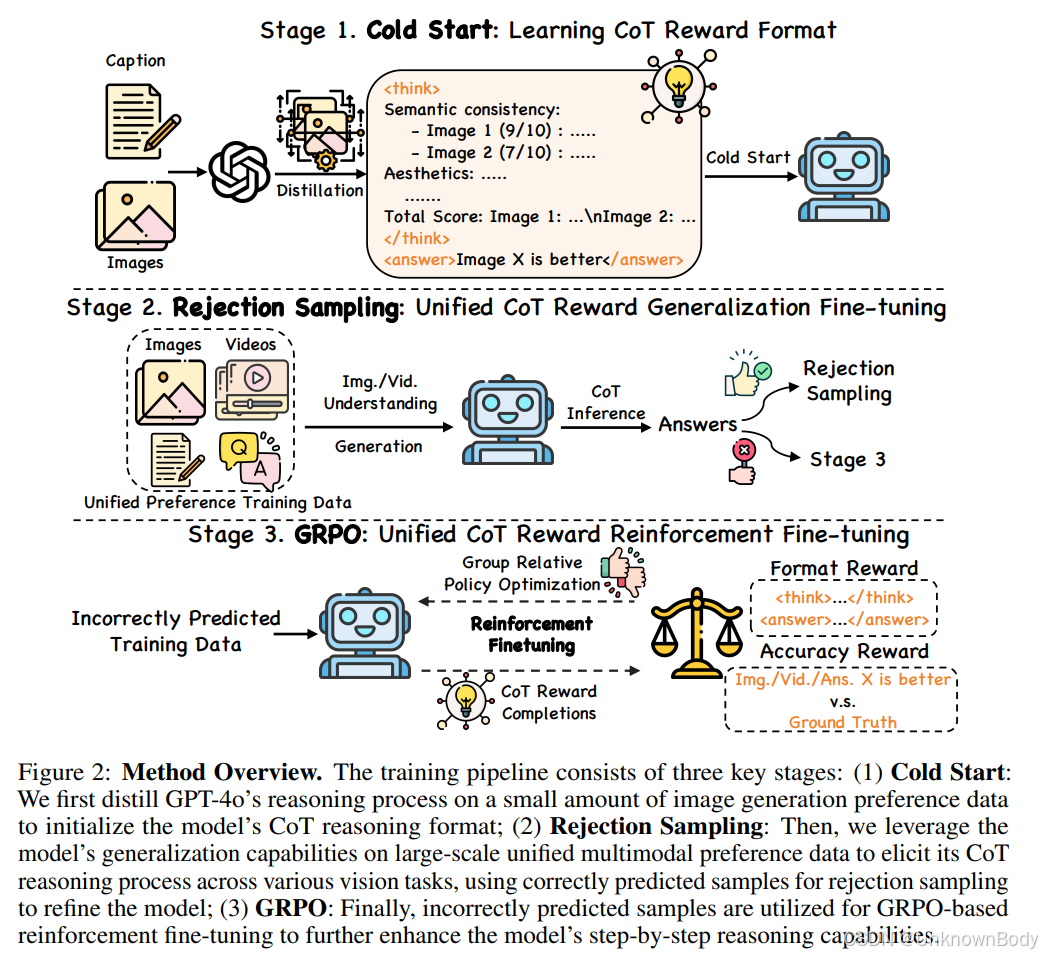
本文提出了首个基于统一多模态思维链(CoT)的奖励模型UNIFIEDREWARD-THINK,旨在通过显式长链推理提升多模态奖励模型的可靠性和鲁棒性。核心方法分为三个训练阶段:
- 冷启动阶段:使用少量图像生成偏好数据蒸馏GPT-4o的推理过程,使模型学习CoT推理的格式和结构。
- 拒绝采样阶段:利用大规模统一多模态偏好数据激发模型在各类视觉任务中的推理能力,保留正确推理样本以强化准确模式。
- 组相对策略优化(GRPO)阶段:对错误预测样本进行基于GRPO的强化微调,推动模型探索多样化推理路径,优化推理准确性。
实验表明,引入长CoT推理显著提升了奖励信号的准确性,且模型在掌握CoT后即使无需显式推理痕迹,也能通过隐式推理超越现有基线。
二、文章创新点
- 首个统一多模态CoT奖励模型:实现了视觉理解与生成任务的多维度、分步长链推理,突破了传统奖励模型仅提

 订阅专栏 解锁全文
订阅专栏 解锁全文



















 295
295

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











