







如何选择机器学习算法、系统
1 - Deciding What to Try Next 在模型遇到问题时该怎么办
当你用regularized linear regression 实现了housing prices predict问题之后,发现你的模型在测试新数据时出现非常大的误差。
这时可能的措施如下:
- Get more training examples
- Try smaller sets of features
- Try getting additional features
- Try adding polynomial features (x21,x22,x1x2,etc)
- Try decreasing λ
- Try increasing λ
但是往往你不知道到底该选择哪一种方法,而通常逐个尝试这些方法可能会浪费大量的时间。
Machine learning diagnostic:
Diagnostic:
一种能够知道你的学习算法是否有效,并且知道如何更好的改进你的算法的测试方法。
Diagnostic 需要一定的时间去实现,但是这绝对不会是在浪费时间!
2 - Evaluating a Hypothesis 评价你的模型
将数据集划分成训练集(70%)和测试集(30%),用训练集去训练模型,用测试集去评价模型的效果。
step 1: 学习出参数 θ (最小化训练集的误差J(θ))
step 2: 计算测试集的误差
3 - Model Selection and training/validation/test Sets
为了避免 underfitting 和overfitting 的问题,引入 cross validation set,即交叉验证数据集。将数据集按6:2:2的比例分成training set、cross validation set 和 testing set三部分。
error计算公式如下:

模型选择方法:
- 对候选的每个模型,在 training set 上 =求使得 training error最小的θ参数值
- 代入参数θ,在 cross validation set 上计算 J(cv)
- 将cv set error 最小的一个模型 作为 hypothesis
4 - Diagnosing Bias vs. Variance (模型的维度dimension对error的影响)
4.1 什么是Bias和Variance
Bias:hypothesis的平均估计结果所能够逼近学习目标的程度
Variance:面对同样规模的不同数据集时,算法的估计结果发生变动的程度。
从图像上给一个直观的印象,什么是 bias 和 variance:
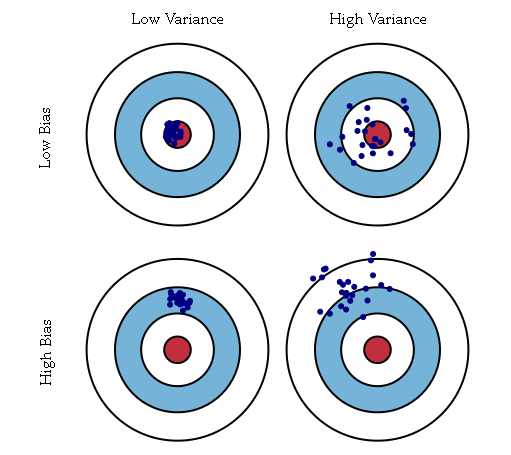
4.2 bias 和 variance 的diagnose
dimension对拟合效果的影响:
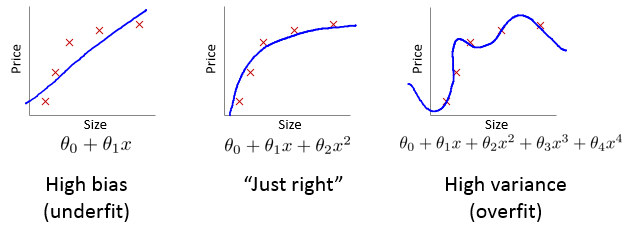
- high bias:估计均值与实际相差较大。训练集的误差和交叉验证集的误差J(θ)都比较大。
- high variance:估计均值与训练集非常接近,但是在遇到新的数据时,误差会变大比较大。训练集的误差小,交叉验证集合的误差较大。
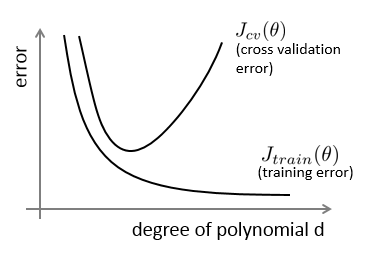
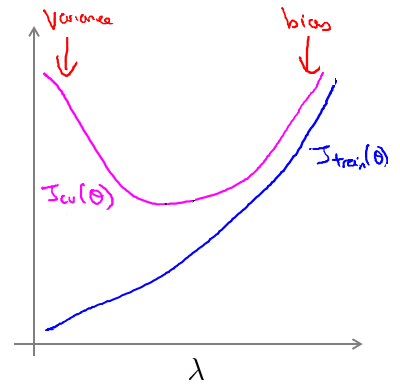
5 - Regularization and Bias/Variance 规则化 中的bias/variance(λ与error的关系)
λ 对拟合效果的影响:
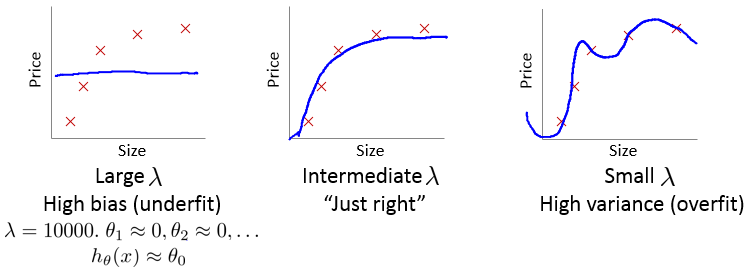
计算公式:
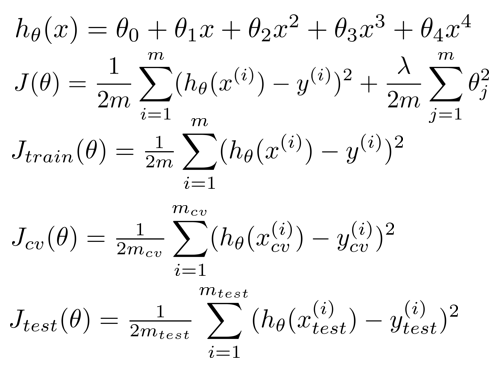
λ的选择方法:
- 从0,0.01起,每次往上 x2 ,到10.24总共可以试12次。
- 用这12个 λ 计算出对应的J(θ)和Jcv(θ)
- 选择令 J(θ) 最小的θ作为参数,然后取出另Jcv(θ)最小的一组定为最终的λ。
如图为 λ 对误差的影响:
6 - Learning Curves 学习曲线(数据个数m与error之间的关系)
- Underfit:增加数据没有任何益处
- overffit:增加数据对提高performance有帮助















 4250
4250

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









