







Deciding What to Try Next
当用算法实现预测功能但是效果不是很好时的解决办法如下:

Evaluating a Hypothesis
线性回归计算J(
θ
)的公式

逻辑回归分类时计算J(
θ
)的公式,以及error计算公式

Model Selection and Train_Validation_Test Sets
将所有数据按%60,%20,%20分为training set , cross validation set , testing set三类,以及三种误差。


traning set用于训练
cross validation set用于选择模型
testing set用于评估

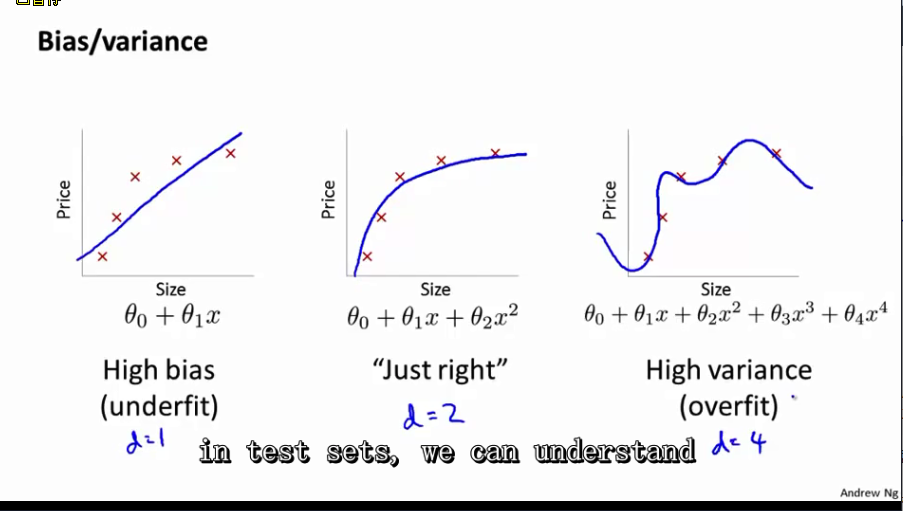
Diagnosing Bias vs. Variance
- Bias Error: bias error是指模型预测值与真实值差异的平均值。假如有m个样本,1每次随机去n个(n << m),用n个样本训练出一个模型。然后对(x,y)进行预测得到一个预测值y(1);重复1操作,然后对(x,y)进行预测得到y(2).Error due to Bias = (y(1) – y + y(2) – y, 然后求平均)。
- Variance Error: Variance Error是指每次预测的方差,反应模型预测的波动情况。
- 区别:Bias反映的是模型在样本上的输出与真实值之间的误差,即模型本身的精准度,Variance反映的是模型每一次输出结果与模型输出期望之间的误差,即模型的稳定性。

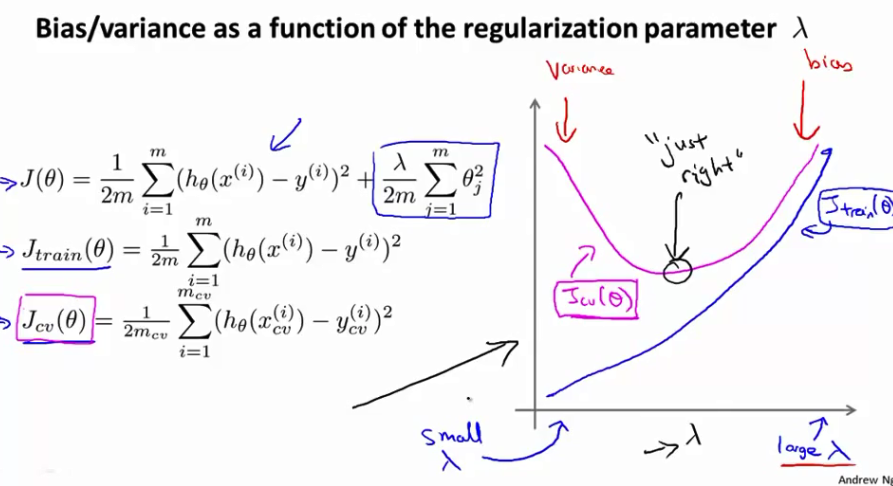
Regularization and Bias_Variance

在选取
λ
,依次测试多个
λ
值,选取使得
J(θ)
最小的
λ
。

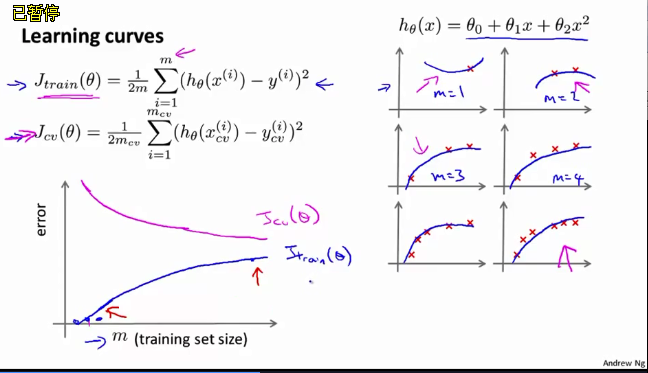
Learning Curves
理想情况下的学习曲线应该是随着m的增加,
Jtrain(θ)
and
Jcv(θ)
都会随之减少,并处于相对低的一个值。
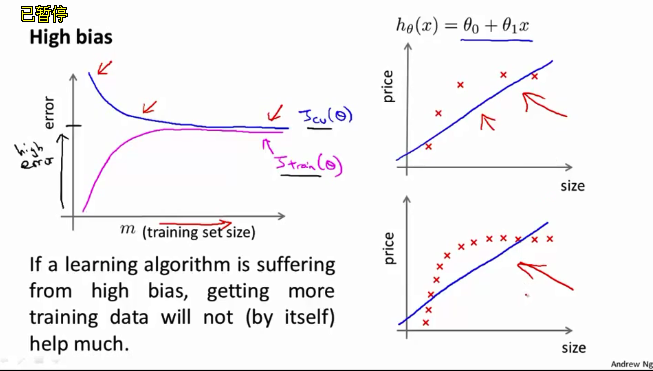
high bias情况下,表示underfit,此时
Jtrain(θ)
and
Jcv(θ)
都会随之减少,但二者的值都会比较大。
high variance,表示overfit,二者之间会有较大的gap

Deciding What to Do Next Revisited
各种解决办法适用的情况。

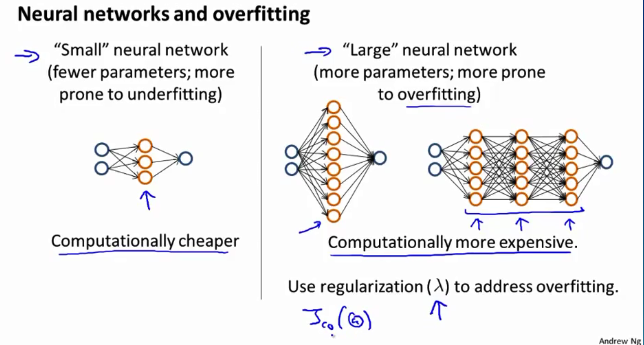
一般来说 使用一个大型的神经网络并使用正则化来修正过拟合问题通常比使用一个小型的神经网络效果更好。















 4380
4380

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









