







1 - Problem Formulation 推荐系统
电影推荐:
- nu= 用户数量
- nm= 电影数量
- r(i,j)=1 用户 j 对电影 i 进行了评价
- y(i,j)= 用户 j 对电影 i 的评分(仅当 r(i,j)=1 时才存在)
2 - Content Based Recommendations 基于内容推荐
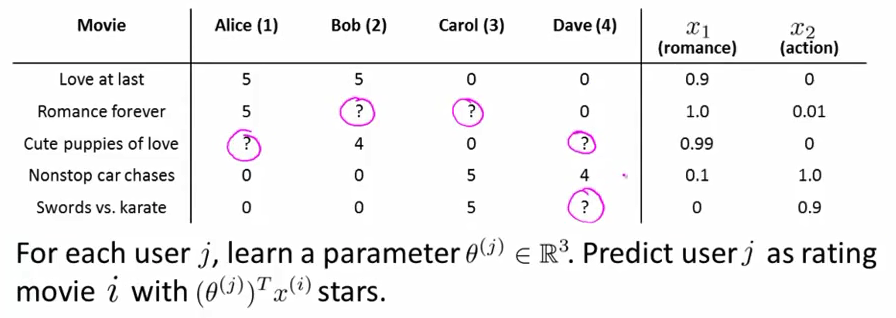
2.1 Problem formulation:
- r(i,j) 用户 j 对电影 i 进行了评价
- y(i,j) 用户 j 对电影 i 的评分(仅当 r(i,j)=1 时才存在)
- θ(j) 用户 j 的参数向量
- x(i) 电影 i 的特征向量
- m(j) 用户 j 评了分的电影数量
已知电影特征 x(i) ,现在需要学习出每个用户的喜好特征 θ(j) ,用于估计用户对没看过电影的评分: y(i,j)=(θ(j))T(x(i))
2.2 优化目标:

2.3 优化算法:

2.4 算法总结
- 已知条件:
- 每个电影的属性参数
X
,其中
X(i,:) 表示第 i 个电影的属性,此时假设共有 100 个不同的属性特征,即X(i,:) 为长度100的向量。 - 用户
j
的评分数据
Y(:,j) (只含评了分的电影,未评分的排除在外)
- 每个电影的属性参数
X
,其中
求解目标:根据用户 j 对部分电影的评分,结合这些电影的属性特征X,推断出用户
j 对各类型电影的喜爱程度(即得出参数 Theta(j,:) ),进而估计用户对未观看电影的喜爱程度(即通过 y=X∗Theta 估计评分)。算法总结:
- 本质上是 linear regression:已知所有电影的各种属性特征,通过用户的现有评分数据推断用户对新电影的评分。
- 各个用户之间互相独立:估算用户对电影的评分只使用了当前用户的数据,并没有结合其他用户的评分数据。
实现代码: (注意循环嵌套顺序 j→k→m )
第 j 个用户对第 k 种类型的电影的喜爱程度(对所有电影进行遍历):
Theta_grad(j,k) = (X* Theta(j,:)' - Y(:,j))' * X(:,k)
第 j 个用户对各类电影的喜爱程度(对电影所有特性进行遍历):
Theta_grad(j,:) = (X* Theta(j,:)' - Y(:,j))' * X(:,:)
所有用户的偏好参数(对所有用户进行遍历):
Theta_grad = (X * Theta' - Y)' * X
最后考虑到有些电影没有评分:
Theta_grad = ((X * Theta' - Y).*R)' * X
3 - Collaborative Filtering 协同过滤
3.1 算法思想
与基于内容推荐不同,我们可能实现不知道电影的特征,而只知道用户的个人喜好特征,那么:

3.2 算法实现
与基于内容推荐类似,下面分析算法的理解思路。
已知条件:
- 用户 j 对各种类型电影的喜爱程度,其中 Theta(j,:) 表示用户 j 对各种类型的电影的喜爱程度
- 电影
i
的评分数据
Y(i,:) (只含评了分的用户的数据,未评分的排除在外)
算法目标: 根据 电影 i 的现有评分数据 , 结合所有用户对各类型电影的喜爱程度
Theta ,估计电影 i 的属性特征(即得出参数X(i.:) )算法总结:
- 本质上是 linear regression,已知所有用户对各类型电影的喜爱程度,通过电影的现有评分数据得出电影的属性参数。
- 各个电影之间相互独立,在计算电影的属性参数时并没有考虑其他电影的分类信息
实现代码:
第 i 个电影属于第 k 种类型的程度:(对所有用户进行遍历)
X_grad(i,k) = (X(i,:)*Theta' - Y(i,:)) * Theta(:,k)
第 i 个电影在各类型属性的参数特征:*(对所有电影分类进行遍历)
X_grad(i,:) = (X(i,:)*Theta' - Y(i,:)) * Theta
所有电影的属性特征:(对所有电影进行遍历)
X_grad = (X*Theta' - Y) * Theta
考虑有的用户对某些电影没有评分:
X_grad = R.*(X*Theta' - Y) * Theta
4 - Collaborative Filtering Algorithm 协同过滤算法
优化目标:

算法步骤:

5 - Vectorization Low Rank Matrix Factorization 矩阵低秩分解的向量化实现
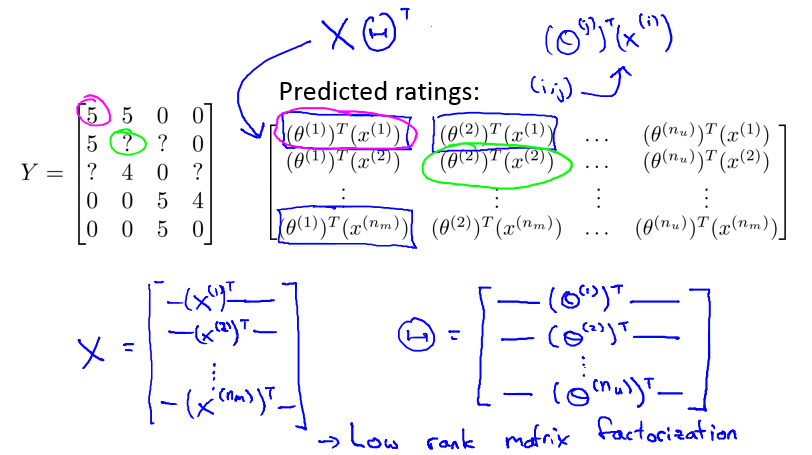
寻找最相似的电影:
small∥x(i)−x(j)∥→
i 与 j 最相似
6 - Implementational Detail Mean Normalization
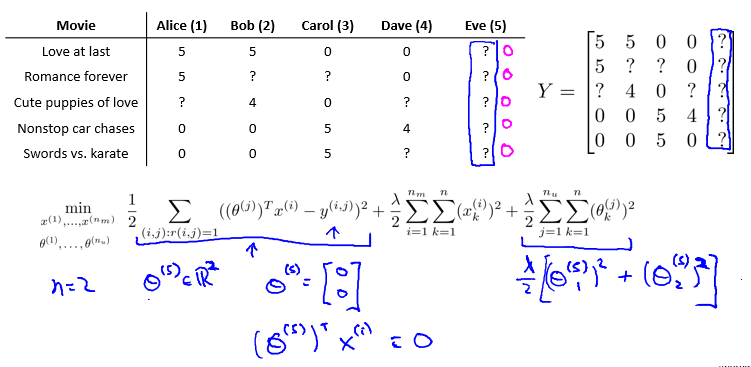
如何处理那些没有对任何电影进行评分的用户:
如果用之前的方法计算,会得出 θ=0 ,进而估计出来的评分都为0
Mean Normalzization:
















 245
245

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









