





文章链接:文章链接
总结:
使用两种方式生成视频

就主题的整体理解而言,被试在两种类型的可视化中都能够大多数正确分类视频。然而,从表4和表5中可以看出,无论是骨骼可视化还是GAN生成的视频都无法传达ASL手语使用者完全理解手语句子所需的重要信息
摘要
为了推动手语识别、翻译和生成领域的进展,一个阻碍因素是缺乏大规模的标注数据集。为此,我们介绍了How2Sign,一个多模态和多视角的连续美国手语(ASL)数据集,包括超过80小时的手语视频并附带语音、英文转录和深度等相关模态。其中,我们在全景摄影棚中进一步录制了三小时的子集,以进行详细的3D姿势估计。为了评估How2Sign在实际应用中的潜力,我们与ASL手语使用者进行了一项研究,并展示了使用我们数据集生成的合成视频的可理解性。该研究进一步揭示了计算机视觉在这一领域中需要解决的挑战。
2.2 手语数据集
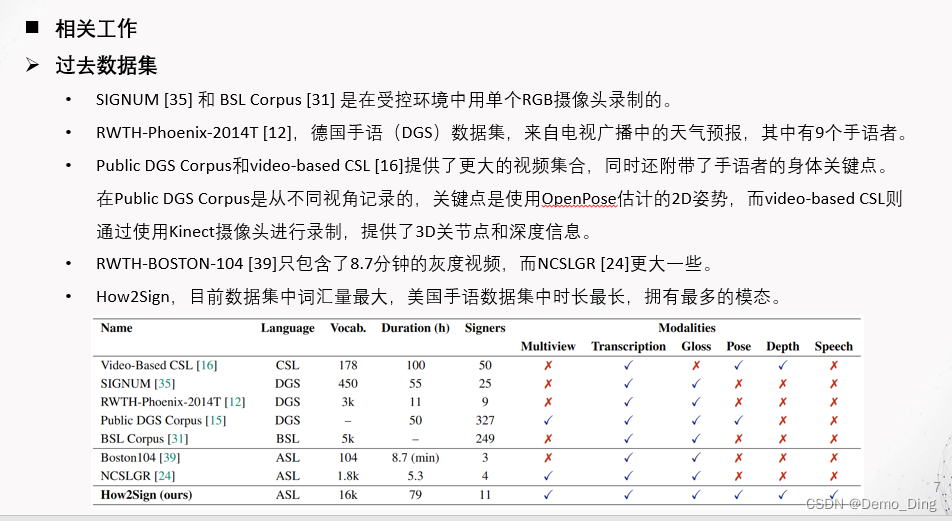
阻碍手语处理研究进展的最重要因素之一是缺乏大规模的注释数据集[6]。许多现有的手语数据集只包含孤立的手势[10, 4, 18, 21, 23, 34]。这样的数据在某些情况下可能很重要(例如创建字典或作为学习手语的资源),但大多数实际应用场景中的手语处理涉及到具有完整句子的自然对话(即连续手语)。多年来,已经收集了许多用于语言研究目的的连续手语数据集。SIGNUM [35] 和 BSL Corpus [31] 是在受控环境中用单个RGB摄像头录制的。最近在神经机器翻译[8]和制作[30, 28]方面的研究中,采用了RWTH-Phoenix-2014T [12],这是一个包含德国手语(DGS)数据集,专门用于从电视广播中的天气预报中提取的数据,其中有9个手语者。Public DGS Corpus [15] 和video-based CSL(中国手语)[16]提供了更大的视频集合,同时还附带了手语者的身体关键点。在Public DGS Corpus的情况下,这些是使用OpenPose [9]估计的2D姿势,从不同视角记录的,而基于视频的CSL则通过使用Kinect摄像头进行录制,提供了3D关节点和深度信息。如果我们关注美国手语(ASL),RWTH-BOSTON-104 [39]只包含了8.7分钟的灰度视频,而NCSLGR [24]更大一些,但与How2Sign相比,规模要小一个数量级。就注释而言,除了基于视频的CSL,所有数据集都提供了手语注释,即手语的基于文本的转录,可以作为翻译任务的代理。表1列出了按词汇量大小排序的公开连续手语数据集的概述。缺乏大规模数据集的一个重要因素是连续手语数据的收集和注释是一项费时费力的任务。它需要语言专家与一个本土使用者,例如聋人一起工作。RWTH-Phoenix-2014T [12]是为数不多的公开可用数据集之一,并已被用于训练深度神经网络。最近的注释重新对齐还允许研究手语翻译。然而,它们的视频仅涵盖了来自天气广播的11小时数据,并且局限于一个领域。总之,当前公开可用的数据集受到以下一个或多个限制的约束:(i)有限的词汇量大小,(ii)视频或总时长短,以及(iii)有限的领域。How2Sign数据集提供了比现有数据集更大的词汇量,并且它在连续手语设置下为更广泛的话语领域提供了语音内容。它也是第一个包含语音的手语数据集,得益于与现有的How2数据集[27]的对齐。
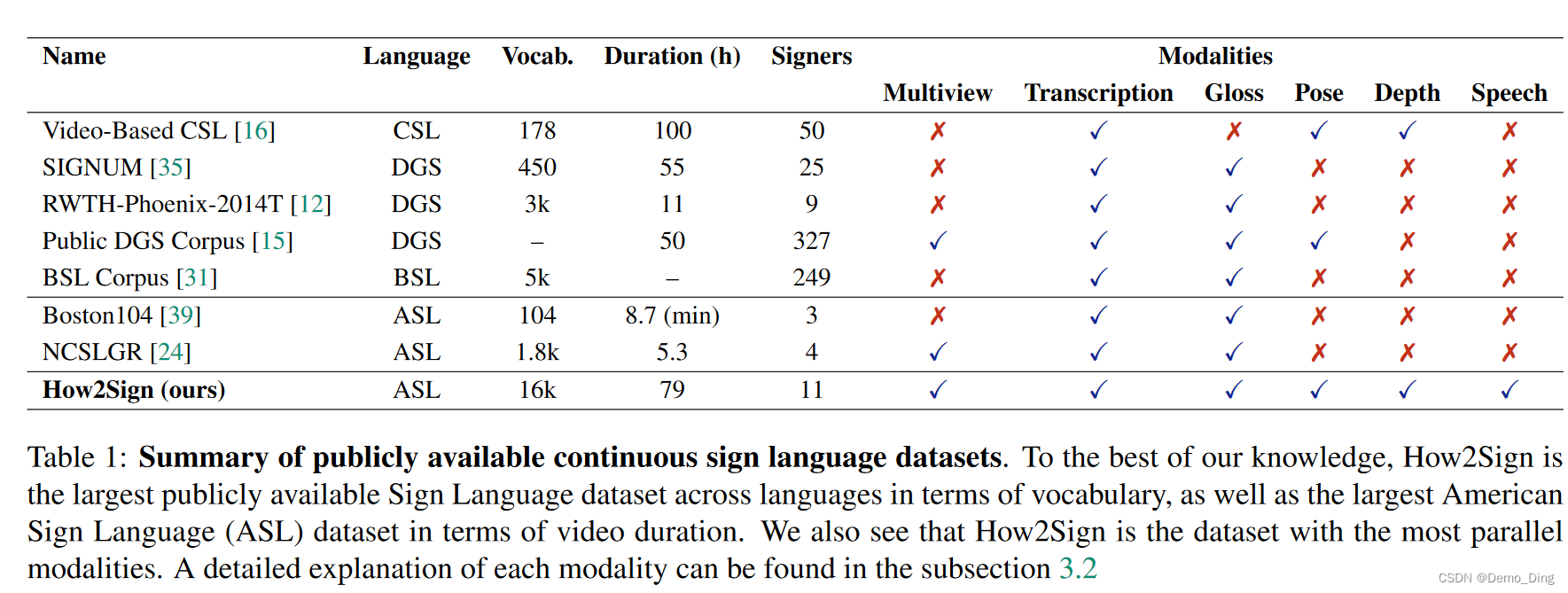
表1:公开连续手语数据集的概述。据我们所知,在所有语言数据集中,How2Sign是词汇量最大的公开手语数据集,也是根据视频时长而言最大的美国手语(ASL)数据集。我们还可以看到,How2Sign是具有最多平行模态的数据集。有关每种模态的详细说明可以在3.2小节中找到。
3. The How2Sign dataset
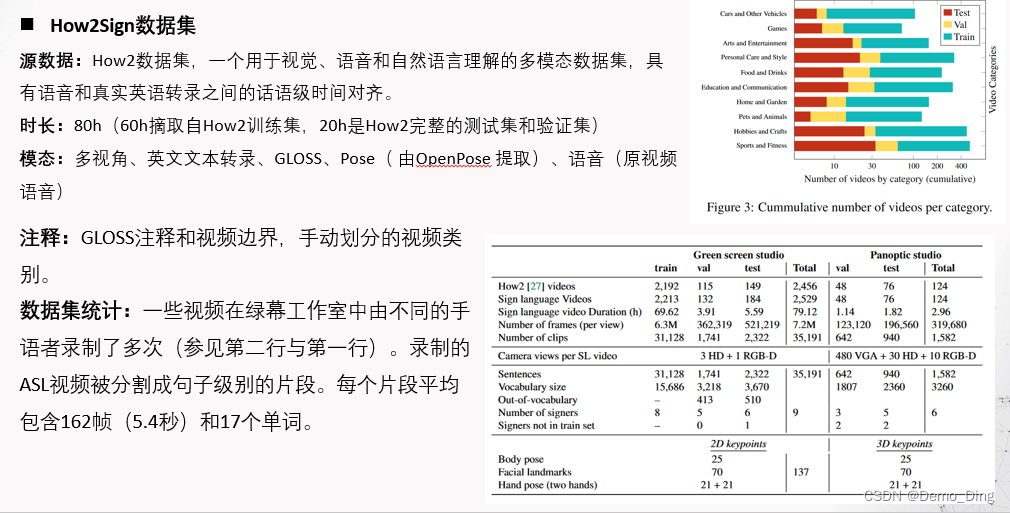
How2Sign数据集由一组包含讲解视频及其相应的美国手语(ASL)翻译视频和注释的语音和转录平行语料库组成。总共收集了80小时的多视角美国手语视频,以及手语注释[22]和粗略的视频分类。
源语言。翻译为ASL的讲解视频来自现有的How2数据集[27],这是一个公开可用的多模态数据集,用于视觉、语音和自然语言理解,具有语音和真实英语转录之间的话语级时间对齐。根据How2300h数据集的相同拆分方式,我们从训练集中选择了一个60小时的子集,并记录了完整的验证集和测试集。
3.1 手语视频录制
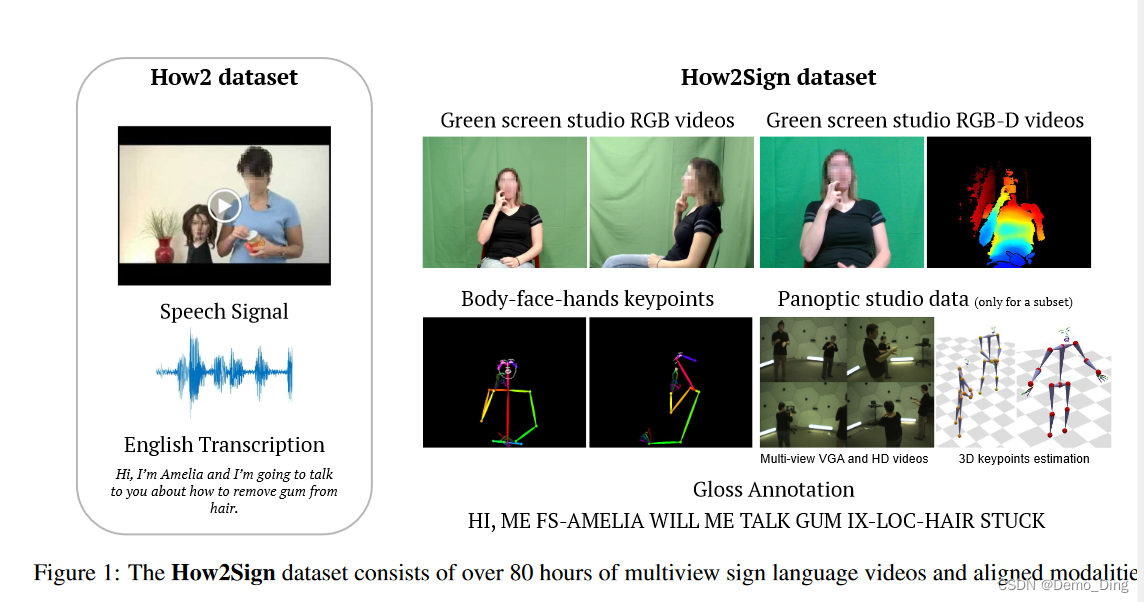
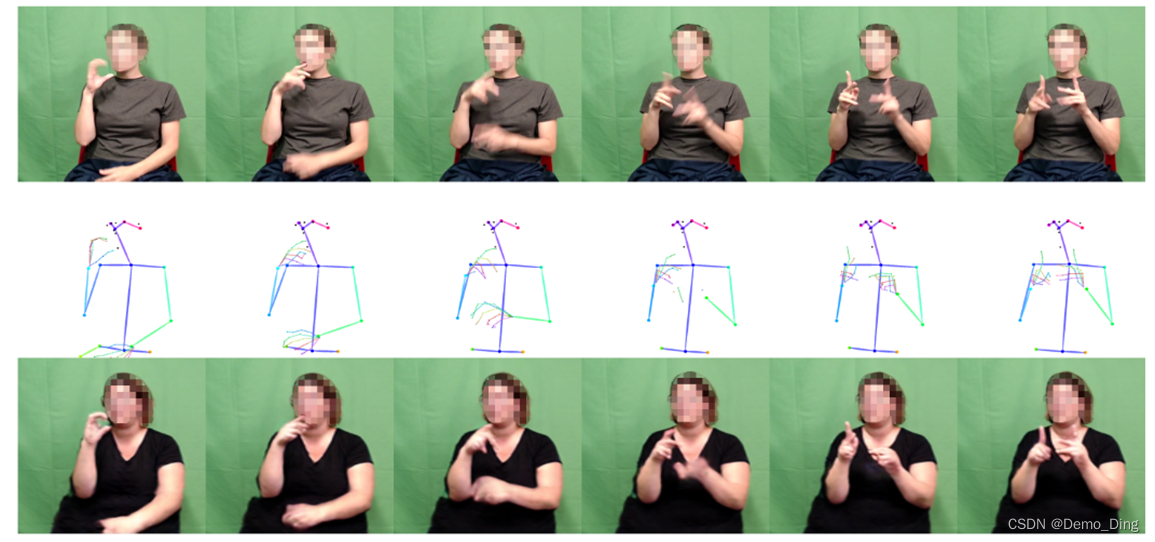
手语者.How2Sign数据集的手语视频中共有11位参与者,我们称之为手语者。其中5位手语者自认为是听觉正常的,4位为聋人,2位为听力有障碍。听觉正常的手语者要么是专业ASL口译员(4位),要么是精通ASL。录制流程。手语者首先会在字幕中观看带有转录的视频,以了解整体内容,从而能够进行更丰富的翻译。然后,在手语者观看带有字幕的视频时,以稍微较慢(0.75倍速)的速度录制ASL翻译视频。每小时录制的视频所需的准备、录制和视频回顾平均约为3小时。所有录制都在受监督的环境中进行,分别在Green Screen工作室和Panoptic工作室两个不同的位置进行。我们在绿幕工作室录制了完整的80小时数据集。然后,我们从验证集和测试集中选择了一个小的视频子集(约3小时),并在Panoptic工作室进行了再次录制。录制完成后,我们对所有手语视频进行裁剪,并将其分割为以句子为级别的片段,每个片段都附带有相应的英文转录,以及第3.2节中介绍的模态。 Green Screen工作室。Green Screen工作室配备有一个深度摄像头和一个高清(HD)摄像头,分别以参与者的正面和侧面视图放置。这三个摄像头以1280x720分辨率,以30帧/秒的速度录制视频。图1的顶部一行显示了在该工作室中录制的数据样本。 Panoptic工作室。Panoptic工作室[17]是一个系统,配备有480个VGA摄像头,30个
高清摄像头和10个RGB-D传感器,所有摄像头都同步工作。所有摄像头安装在一个球面穹顶的表面上,为弱感知过程(如姿势检测)提供冗余,并具有抗遮挡能力。除了多视角的VGA和高清视频外,录制系统还可以进一步估计口译员的高质量3D关键点,这也包括在How2Sign数据集中。图1右下方显示了在该工作室中录制的数据样本。
3.2. 数据集模态
本节详细介绍了表1中列出的各种模态。除了已经存在于How2数据集[27]中的英文翻译和语音模态外,所有其他模态要么是收集的,要么是自动提取的。据我们所知,How2Sign是目前公开可用的跨语言手语数据集中词汇量最大的,而且在视频时长方面比任何其他ASL数据集大一个数量级。我们可以看到,How2Sign也是具有最多平行模态的数据集,可以进行多模态学习。
多视角。所有80小时的手语视频都是从多个角度录制的。这使得手势可以从多个视角可见,减少了遮挡和歧义,尤其是在手部。具体而言,Green Screen工作室中录制的手语视频包含两个不同的视角,而Panoptic工作室的录制则包括超过500个摄像机的录制,可以对3D关键点进行高质量估计[17]。
转录。英文翻译模态来自How2原始视频的字幕轨道。转录以文本形式由讲解视频的上传者提供,它与视频的语音轨道松散同步。由于字幕不一定与语音完全对齐,转录在句子级别上进行了时间对齐,作为How2数据集的一部分[27]。
GLOSS是在语言学中使用的,用于使用口语单词转录手势。它通常以大写字母书写,并指示每个手势的个别部分的含义,包括考虑到面部和身体语法的注释。图1右下方显示了GLOSS注释的示例。需要注意的是,GLOSS并不是真正的翻译,而是提供了表达手势在口语中的含义的适当语言形态素。GLOSS不包含特殊的手形、手的运动/方向,也不能让读者确定手势是如何制作的,或者在给定语境中的确切含义。它们也不指示面部表情的语法用法(例如,抬起眉毛用于是/否问题)。GLOSS是最接近手语的文本形式,已被多种方法用作手语处理的中间表示[12, 30, 28, 40, 19]。
姿势信息。对所有录制的手语视频,例如身体、手和面部关键点,都以完整分辨率(1280 x 720像素)提取了人体姿势信息。对于Green Screen工作室的数据,使用OpenPose [9]自动提取了2D姿势信息。总共,每个姿势包含25个身体关键点、70个面部关键点和每只手21个关键点。我们提供了Green Screen工作室数据的正面和侧面视图的姿势信息。图1左侧底部显示了提取出的姿势信息的样本。对于Panoptic工作室的数据,我们提供了由Panoptic工作室内部软件[17]估计的高质量3D姿势信息,可用于多个3D视觉任务的真实值。深度数据。对于Green Screen工作室的数据,还使用深度传感器(Creative BlasterX Senz3D)从正面视点录制了手语视频。该传感器具有嵌入的高精度面部和手势识别算法,并且能够聚焦于手部和面部,这是手语中最重要的人体部位。
语音。语音轨道来自How2数据集[27]中的讲解视频。
3.3. 收集的注释
除了视频录制和自动提取的姿势信息外,我们还针对手语视频收集了一些手动注释。
GLOSS和句子边界。
我们通过聘请ASL语言学家收集GLOSS注释。这些注释使用ELAN [13]进行收集,ELAN是一种用于音频和视频录制的注释软件,专门用于手语注释。在ELAN中,信息以层的形式表示,这些层与视频文件进行时间对齐,给出了每个句子的开始和结束边界,从而产生了我们所称的句子边界。平均每90秒视频需要花费约一小时进行GLOSS注释。
视频类别。
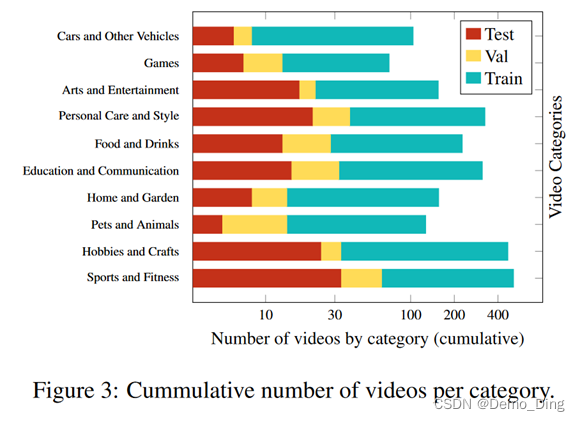
虽然How2数据集使用潜在狄利克雷分配[5]自动提取了所有视频的“主题”,但我们发现自动注释通常非常嘈杂,没有很好地描述所选视频。为了更好地对视频进行分类,我们从教学网站Wikihow [6]手动选择了10个类别,并手动将每个How2Sign视频分类到一个类别中。视频在这十个类别中的分布情况可以在图3中看到。
3.4. 数据集统计
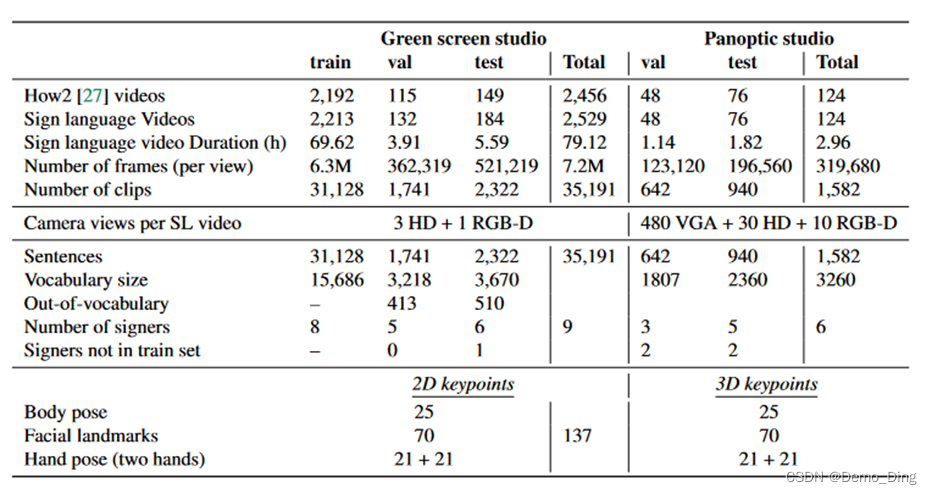
在表2中,我们展示了How2Sign数据集的详细统计信息。共使用了来自How2 [27]的2,456个视频来录制手语视频。其中一些视频在Green screen工作室中由不同的手语者录制了多次-训练集中的21个视频,验证集中的17个视频和测试集中的35个视频。所有录制的视频都被分割成句子级别的片段。每个片段平均有162帧(5.4秒)和17个单词。数据集的三个划分的所有片段的帧数(右侧)和单词数(左侧)的分布可以在图2中看到。收集的语料库涵盖了超过35,000个句子,英语词汇量超过16,000个词。其中约20%的内容是拼写手语。这些视频由分布在不同划分上的11名不同手语者录制。测试集包含了26个重复的视频,由一个训练集中不存在的手语者录制;可以使用这26个视频的子集来衡量不同手语者之间的泛化能力。总共有9个手语者参与了Green Screen工作室的录制,6个手语者参与了Panoptic工作室的录制。表2的底部部分是自动提取的人体姿势注释信息。
3.5. 隐私、偏见和道德考虑
在本节中,我们讨论一些元数据,这些元数据对于理解在我们的数据上训练的系统的偏见和泛化能力非常重要。
隐私:由于面部表情对于生成和/或翻译手语来说是一个关键组成部分,无法避免包含手语者面部的录制。为此,所有的研究步骤都遵循卡内基梅隆大学的机构审查委员会批准的程序,包括第一和第二作者进行的社会与行为研究培训,以及由参与者签署的同意书,同意他们的数据可以公开用于研究目的。重要的是要注意,这会对收集的语言数据的真实性产生风险,因为手语者可能会比平时更加注意自己的表达。
听力状况和语言变体:大多数参与者将美国手语和接触手语(混合手语英语 - PSE)视为录制过程中主要使用的语言。值得注意的是,听障人士很可能将美国手语视为录制过程中主要使用的语言。相比之下,听觉正常的人很可能将混合手语和美国手语混合使用作为录制过程中的主要语言使用。关于混合手语和美国手语的更多信息可以在[26]中找到。
地理位置:所有参与者在美国出生和成长,并在学校时期学习美国手语作为他们的第一语言或第二语言。
手语者的多样性:我们的数据集由具有不同身体比例的手语者录制。其中六位自认为是男性,五位自认为是女性。数据集在6个月的65天内收集,参与者使用了各种服装和配饰。
数据偏见:我们的数据在种族/族裔、肤色、背景景观、光照条件和摄像机质量方面没有大的多样性。
4. 评估How2Sign在手语任务中的潜力
由于神经机器翻译和计算机视觉的最新进展,未来几年内,手语用户与非手语用户之间的沟通障碍可能会减少。 最近的研究正在通过自动从口语语言生成详细的人体姿势关键点来进行手语产生[30, 33, 41, 40, 29]和翻译[19],即使用关键点作为输入生成文本。虽然关键点可以携带详细的人体姿势信息,并且可以作为减少使用实际视频帧时引入的计算瓶颈的替代方法,但目前还没有研究证明它们是否确实对手语用户理解手语有用。 在本节中,我们展示了一项研究,试图了解使用How2Sign的关键点作为手语表示的自动生成手语视频对手语用户的理解程度。我们在四名美国手语演讲者身上进行了这项研究,并记录了他们对生成视频的理解程度,包括类别、美式英语翻译以及关于视频可理解程度的最终主观评级。
4.1. 合成手语视频
我们尝试了两种生成手语视频的方法:
1)骨骼可视化和2)生成对抗网络生成(GAN生成)视频。
骨骼可视化:给定一组估计的关键点,可以将它们可视化为连接建模关节的线框骨架(见图4中间行)。
GAN生成的视频:另一种选择是进一步使用生成模型根据预测的关键点合成视频。为了生成给定一组关键点的手语者的动画视频,我们使用了称为Everybody Dance Now(EDN)[11]的运动转移和合成方法。该模型基于Pix2PixHD [36],但通过使用学习的时间连贯性模型进一步增强了视频和动作合成之间的视频和动作合成之间的时序连贯性,该模型能够预测两个连续帧,并使用独立的高分辨率人脸生成模块。值得注意的是,该方法单独对面部特征进行建模,这在我们的情况下非常重要,因为它们是理解手语的关键特征之一。EDN模型在How2Sign数据集的子集上进行了训练,该子集包含两个参与者的视频。具体而言,使用从第一个手语者的视频中提取的关键点来学习生成第二个手语者逼真视频的模型。使用了训练集的28小时进行了训练。
4.1.1 GAN生成的手语视频的定量评估。
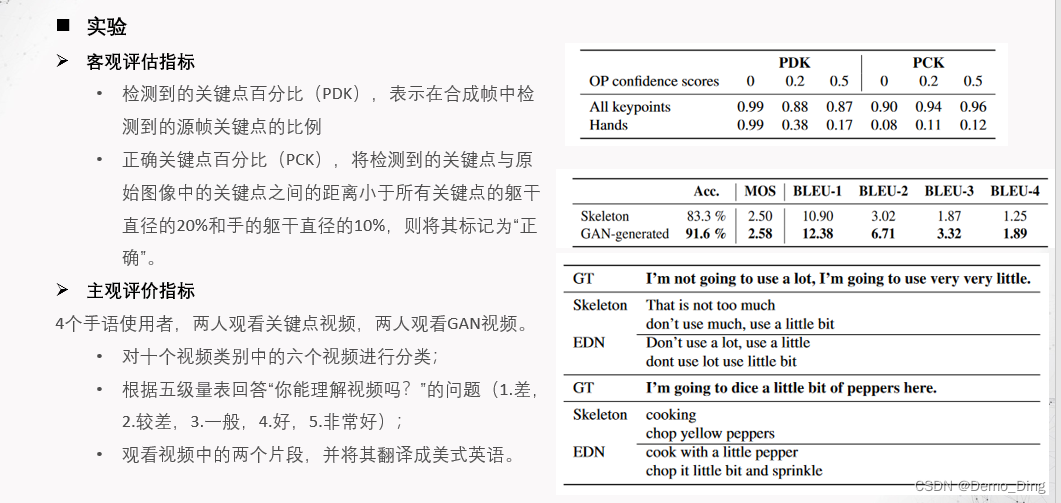
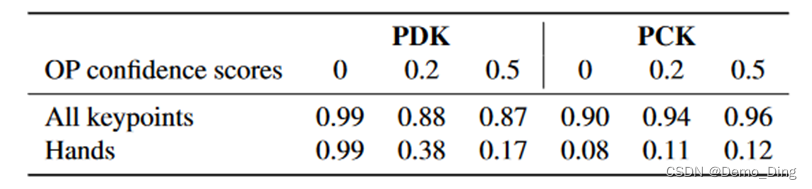
一种近似但自动的测量 生成视频视觉质量的方法是 比较可以在源视频和生成视频中可靠检测到的关键点。我们只关注How2Sign视频中可见的125个上身关键点,舍弃了腿部的关键点。我们使用两个指标:a)检测到的关键点百分比(PDK),表示在合成帧中检测到的源帧关键点的比例;b)正确关键点百分比(PCK)[38],如果在所有关键点中,检测到的关键点与原始图像中的关键点之间的距离小于所有关键点的躯干直径的20%和手的躯干直径的10%,则将其标记为“正确”。在表3中,我们展示了不同最小置信度阈值的OpenPose(OP关键点检测器)的这些指标。我们报告了所有关键点的结果,以及仅限于手关键点的评估结果。我们可以看到,尽管关键点的重复性通常很高,但该模型无法可靠地预测手部的关键点。这一限制在手语处理中尤为重要。
4.2. ASL手语使用者能理解生成的手语视频吗?
我们通过向四名ASL手语使用者展示3分钟长的视频来评估骨骼可视化和GAN生成的视频的理解程度。其中两名观看了骨骼可视化视频,另外两名观看了GAN生成的视频。在评估过程中,每个被试被要求:a)对十个视频类别中的六个视频进行分类(有关数据集类别的更多信息,请参见第3.2小节);b)根据五级量表回答“你能理解视频吗?”的问题(1.差,2.较差,3.一般,4.好,5.非常好);c)观看之前看过的视频中的两个片段,并将其翻译成美式英语。表4呈现了所有被试的平均结果。我们报告了分类任务的准确率,五级量表问题答案的平均意见分数(MOS)以及美式英语翻译的BLEU [25]分数。表5展示了定性结果。结果显示,相对于骨骼可视化视频,被试更倾向于生成的视频,因为前者在所有指标上得分更高。就主题的整体理解而言,被试在两种类型的可视化中都能够大多数正确分类视频。然而,从表4和表5中可以看出,无论是骨骼可视化还是GAN生成的视频都无法传达ASL手语使用者完全理解手语句子所需的重要信息。我们推测,当前的人体姿势估计方法(如[9])在估计手部的快速运动方面仍不够成熟。我们观察到,由于手语的特性和手语者手部的快速运动,OpenPose在这些情况下缺乏精确性,这可能导致可视化结果不完整,影响对手语的某些重要部分的理解。计算机视觉如何能做得更好?我们的结果表明,EDN模型作为一种开箱即用的方法对于手语视频生成来说还不够。具体而言,我们展示了该模型在生成手部和面部细节方面存在困难,而这在手语理解中起着核心作用。我们认为人体姿势估计在这方面起着重要作用,并且需要对模糊图像(尤其是手部)以及快速运动更加稳健,以适应手语研究。我们还提出,值得探索更加关注手部细节(特别是手指的运动)以及全身综合中清晰面部表情的生成模型。


365210a234d1b824fb2313b8b117d.png
5. 结论
本文介绍了How2Sign数据集,这是一个大规模的多模态和多视角的美国手语数据集。How2Sign包括80多小时的手语视频及其相应的语音信号、英文转录和注释,对于手语识别、翻译和产生等手语理解任务以及更广泛的多模态和计算机视觉任务(如3D人体姿势估计)具有潜力。How2Sign扩展了现有的多模态数据集How2 [27],
增加了新的手语模态,从而使其能够与视觉、语音和语言社区的研究相连接。除此之外,我们还进行了一项研究,将从我们数据集的自动提取的注释生成的手语视频展示给ASL手语使用者。据我们所知,这是第一项研究,了解基于关键点的合成视频(一种常用的手语产生和翻译表示)能被手语使用者理解的程度。我们的研究表明,当前的视频合成方法在一定程度上允许进行理解,即视频类别的分类,但缺乏细节的逼真程度,以实现对完整手语句子的精细理解。

















 120
120

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









