






 智谱AI基于GLM-130B千亿基座模型推出了ChatGLM,该模型已开源中英双语版本ChatGLM-6B,支持在消费级显卡上推理。ChatGLM采用独特的架构和多目标函数的预训练方法,旨在实现人类意图对齐,提供高质量的对话体验。
智谱AI基于GLM-130B千亿基座模型推出了ChatGLM,该模型已开源中英双语版本ChatGLM-6B,支持在消费级显卡上推理。ChatGLM采用独特的架构和多目标函数的预训练方法,旨在实现人类意图对齐,提供高质量的对话体验。
点击“开发者技术前线”,选择“星标”
让一部分开发者看到未

转载自:机器之心
我们问了 ChatGLM 几个关键问题,它给的回答似乎很不错。
ChatGPT 的发布,搅动了整个 AI 领域,各大科技公司、创业公司以及高校团队都在跟进。近段时间,机器之心报道了多家创业公司、高校团队的研究成果。
昨日,又一国产 AI 对话大模型重磅登场:由清华技术成果转化的公司智谱 AI 基于 GLM-130B 千亿基座模型的 ChatGLM 现已开启邀请制内测。
值得一提的是,此次智谱 AI 也开源了中英双语对话模型 ChatGLM-6B,支持在单张消费级显卡上进行推理使用。

内测申请网址:chatglm.cn
据了解,ChatGLM 当前版本模型的能力提升主要来源于独特的千亿基座模型 GLM-130B。它是不同于 BERT、GPT-3 以及 T5 的架构,是一个包含多目标函数的自回归预训练模型。
2022 年 8 月,清华大学联合智谱 AI 向研究界和工业界开放了拥有 1300 亿参数的中英双语稠密模型 GLM-130B,该模型有一些独特的优势:
双语:同时支持中文和英文;
高精度(英文):在公开的英文自然语言榜单 LAMBADA、MMLU 和 Big-bench-lite 上优于 GPT-3 175B(API: davinci,基座模型)、OPT-175B 和 BLOOM-176B;
高精度(中文):在 7 个零样本 CLUE 数据集和 5 个零样本 FewCLUE 数据集上明显优于 ERNIE TITAN 3.0 260B 和 YUAN 1.0-245B;
快速推理:首个实现 INT4 量化的千亿模型,支持用一台 4 卡 3090 或 8 卡 2080Ti 服务器进行快速且基本无损推理;
可复现性:所有结果(超过 30 个任务)均可通过我们的开源代码和模型参数复现;
跨平台:支持在国产的海光 DCU、华为昇腾 910 和申威处理器及美国的英伟达芯片上进行训练与推理。
如今, 参考 ChatGPT 的设计思路,ChatGLM 在千亿基座模型 GLM-130B 中注入了代码预训练,通过有监督微调(Supervised Fine-Tuning)等技术实现人类意图对齐。
机器之心获得了内测邀请码,这里简单和 ChatGLM 进行了对话,效果如下:


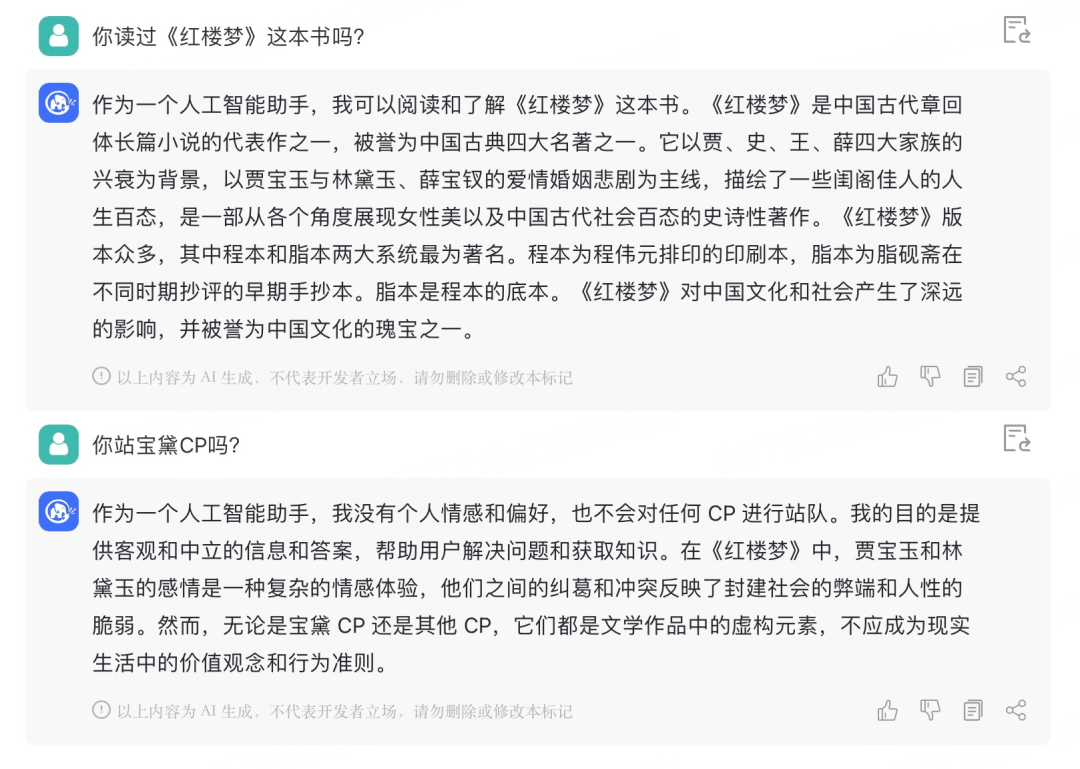
它能够理解「站 CP」的实际涵义:
给 ChatGLM 一个数学问题试试:

自从学会了二元一次方程,像这种基础的「鸡兔同笼」问题就再也难不倒它了:

开源 ChatGLM-6B
ChatGLM-6B 是一个开源的、支持中英双语问答的对话语言模型,并针对中文进行了优化。该模型基于 General Language Model (GLM) 架构,具有 62 亿参数。结合模型量化技术,用户可以在消费级的显卡上进行本地部署(INT4 量化级别下最低只需 6GB 显存)。ChatGLM-6B 使用了和 ChatGLM 相同的技术,针对中文问答和对话进行了优化。经过约 1T 标识符的中英双语训练,辅以监督微调、反馈自助、人类反馈强化学习等技术的加持,62 亿参数的 ChatGLM-6B 虽然规模不及千亿模型,但大大降低了推理成本,提升了效率,并且已经能生成相当符合人类偏好的回答。
模型开源地址:https://github.com/THUDM/ChatGLM-6B
具体来说,ChatGLM-6B 具备以下特点:
充分的中英双语预训练:ChatGLM-6B 在 1:1 比例的中英语料上训练了 1T 的 token 量,兼具双语能力。
优化的模型架构和大小:吸取 GLM-130B 训练经验,修正了二维 RoPE 位置编码实现,使用传统 FFN 结构。6B(62 亿)的参数大小,也使得研究者和个人开发者自己微调和部署 ChatGLM-6B 成为可能。
较低的部署门槛:FP16 半精度下,ChatGLM-6B 需要至少 13 GB 的显存进行推理,结合模型量化技术,这一需求可以进一步降低到 10GB(INT8) 和 6GB(INT4),使得 ChatGLM-6B 可以部署在消费级显卡上。
更长的序列长度:相比 GLM-10B(序列长度 1024),ChatGLM-6B 序列长度达 2048,支持更长对话和应用。
人类意图对齐训练:使用了监督微调(Supervised Fine-Tuning)、反馈自助(Feedback Bootstrap)、人类反馈强化学习(Reinforcement Learning from Human Feedback)等方式,使模型初具理解人类指令意图的能力。输出格式为 markdown,方便展示。
不过由于 ChatGLM-6B 模型的容量较小,不可避免的存在一些局限和不足,包括:
相对较弱的模型记忆和语言能力。在面对许多事实性知识任务时,ChatGLM-6B 可能会生成不正确的信息,也不太擅长逻辑类问题(如数学、编程)的解答。
可能会产生有害说明或有偏见的内容:ChatGLM-6B 只是一个初步与人类意图对齐的语言模型,可能会生成有害、有偏见的内容。
较弱的多轮对话能力:ChatGLM-6B 的上下文理解能力还不够充分,在面对长答案生成和多轮对话的场景时,可能会出现上下文丢失和理解错误的情况。
GLM 团队表示,ChatGLM 距离国际顶尖大模型研究和产品还有一定差距,未来将持续研发并开源更新版本的 ChatGLM 和相关模型。GLM 团队也欢迎大家下载 ChatGLM-6B,基于它进行研究和(非商用)应用开发。
— 完 —
点这里👇关注我,记得收藏订阅哦~历史推荐
原腾讯副总裁,Google资深研究员吴军:ChatGPT不算新技术革命,带不来什么新机会
好文点个在看吧

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









