






内容整理自网易云课堂:U-Net语义分割实战
性能指标
分为IoU,Dice 系数等

在介绍性能指标之前,首先要了解混淆矩阵的概念:
混淆矩阵

在混淆矩阵中,prediction代表预测值,相当于测试集的结果(不一定是正确的)
Actual代表真实标签(相当于金标准ground truth)
有两个指标分别为Precision(精确率,查准率)
和 Recall(召回率,查全率)
其中:
Precision代表预测结果的准确性
Recall代表预测结果的全面性
比如有10名被试,5名患者5名正常,预测结果为6名患者4名正常.
则 查准率为 Precision = 5/6 = 0.83 (找出了6名患者,其中有5名是真正的患者)
查全率为 Recall = 5/5 = 1 (一共有5名真实患者,全部被找出来了)
从上面的例子可以看出,查准率主要看预测结果的准确度.
而查全率主要看实际结果被正确找出的比例.
借用一个例子,在上网搜索文献时,搜到10条结果,其中有5条是相关文献,另外5条是无关文献.
这样,查准率 = 5 / 10 = 50%
后来发现整个网上只有这5条相关文献,
则查全率 = 5 / 5 = 100%
虽然查到的10条文献中只有5条是有用的,查准率很低,可是我们把所有的相关文献都找了出来,查全率很高.
这也从另一方面说明了这两种指标要搭配使用,不能只依赖于其中一种.
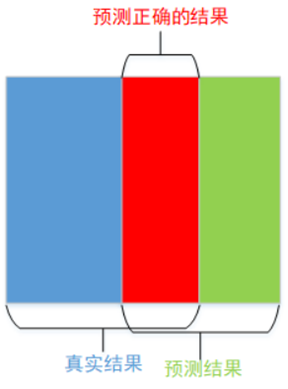
1.IoU

IoU(Intersection over Union)是一个用于评估分割性能的指标,计算方法为:
IoU = 重叠部分 / 两部分的集合
其中两部分指 真实标签和实际分割结果
一般来说IoU大于0.5就可以说结果令人满意了.
举例说明:

2.戴斯系数(Dice Coefficient)
作用:用于评估分割结果与真实标签之间的相似性(越大越好)

















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









