







 文章讨论了在GPU计算中bankconflict的问题,即当同一线程束的不同线程访问共享内存不同地址时导致的访问冲突。通过代码示例展示了bankconflict的发生与避免方法,如memorypadding。此外,还提供了一个使用reduce思想进行一维数组求和的CUDA实验,比较了GPU和CPU的计算性能。
文章讨论了在GPU计算中bankconflict的问题,即当同一线程束的不同线程访问共享内存不同地址时导致的访问冲突。通过代码示例展示了bankconflict的发生与避免方法,如memorypadding。此外,还提供了一个使用reduce思想进行一维数组求和的CUDA实验,比较了GPU和CPU的计算性能。
Part3
一、bank conflict
驻留在GPU 芯片上的内存有寄存器和共享内存两种。共享内存的访存速度仅次于寄存器,而且是最快的能够让线程块中线程进行沟通的地方。为了提高多个线程同时访问共享内存的效率,共享内存被划分为32个逻辑块(banks)。第一个bank为0~3字节,第二个bank为4~7字节,以此类推至127字节。
下图为shared memory及banks划分示意图。(左侧代表shared memory可以被划分成16KB、32KB或者48KB,剩余为L1 cache)
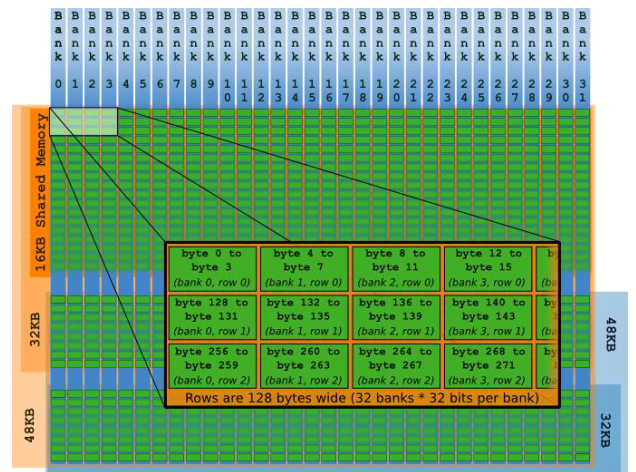
由于每个周期内每个bank只能响应一个地址,当同一个warp(线程束)中的不同线程访问同一个bank中的不同地址时就会发生bank conflict。(也就是一个周期内无法完成对shared memory的访问)
注意:我们强调了是同一个warp中的不同线程访问同一个bank的不同地址,如果访问的是同一个bank的相同地址(其他线程未访问该bank的其他地址),则不会发生bank conflict(因为这会触发多播机制)。当同一个warp中的所有线程访问同一个bank的同一个地址时,也不会发生bank conflict(因为这会出发广播机制)。
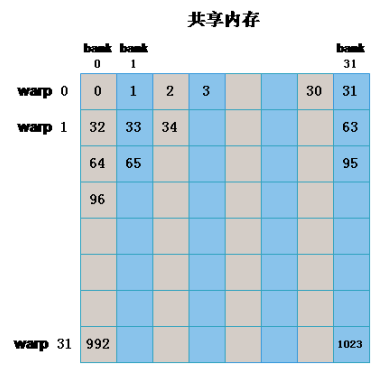
如下代码未发生bank conflict:
同一个warp中的线程索引为((0, 0), (0, 1), (0, 2), (0, 3),...,(0, 31))
// no bank conflict
int x_id = blockDim.x * blockIdx.x + threadIdx.x;
int y_id = blockDim.y * blockIdx.y + threadIdx.y;
int index = y_id * col + x_id; //此处col为matrix的列数
//BLOCK_SIZE = 32 __shared__ 声明sData位于sharedmemory
__shared__ float sData[BLOCK_SIZE][BLOCK_SIZE]
//此处row为matrix的行数
if(x_id < col && y_id < row){
sData[threadIdx.y][threadIdx.x] = matrix[index]; //matrix为全局内存中的一个矩阵
__syncthreads();
matrixTest[index] = sData[threadIdx.y][threadIdx.x];
}
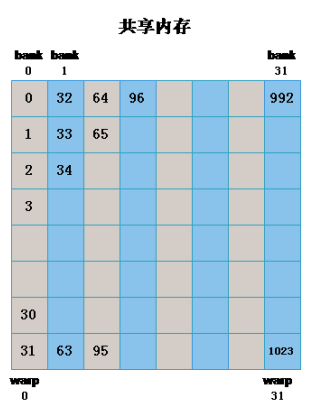
如下代码发生了bank conflict
// bank conflict
int x_id = blockDim.x * blockIdx.x + threadIdx.x;
int y_id = blockDim.y * blockIdx.y + threadIdx.y;
int index = y_id * col + x_id; //此处col为matrix的列数
//BLOCK_SIZE = 32 __shared__ 声明sData位于sharedmemory
__shared__ float sData[BLOCK_SIZE][BLOCK_SIZE]
//此处row为matrix的行数
if(x_id < col && y_id < row){
sData[threadIdx.x][threadIdx.y] = matrix[index]; //matrix为全局内存中的一个矩阵
__syncthreads();
matrixTest[index] = sData[threadIdx.x][threadIdx.y];
}
下图展示一种避免bank conflict的方式(memory padding):
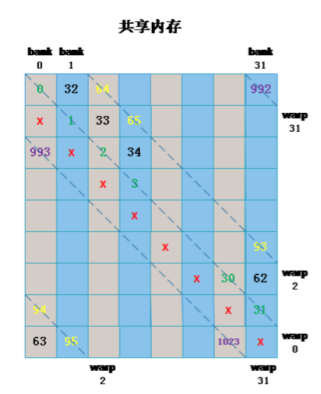
// bank conflict
int x_id = blockDim.x * blockIdx.x + threadIdx.x;
int y_id = blockDim.y * blockIdx.y + threadIdx.y;
int index = y_id * col + x_id; //此处col为matrix的列数
//BLOCK_SIZE = 32 __shared__ 声明sData位于sharedmemory
__shared__ float sData[BLOCK_SIZE][BLOCK_SIZE+1] //增加定义的数组的第二个维度避免conflict
//此处row为matrix的行数
if(x_id < col && y_id < row){
sData[threadIdx.x][threadIdx.y] = matrix[index]; //matrix为全局内存中的一个矩阵
__syncthreads();
matrixTest[index] = sData[threadIdx.x][threadIdx.y];
}二、实验
利用reduce思想对一个较大的一维数组进行求和
#include<stdio.h>
#include<stdint.h>
#include<time.h> //for time()
#include<stdlib.h> //for srand()/rand()
#include<sys/time.h> //for gettimeofday()/struct timeval
#include"error.cuh"
#define N 10000000
#define BLOCK_SIZE 256
#define BLOCKS 32
__managed__ int source[N]; //input data
__managed__ int final_result[1] = {0}; //scalar output
__global__ void _sum_gpu(int *input, int count, int *output)
{
__shared__ int sum_per_block[BLOCK_SIZE];
int temp=0;
for(int idx=threadIdx.x+blockDim.x*blockIdx.x;idx<count;idx+=blockDim.x*gridDim.x){
temp += input[idx];
}
sum_per_block[threadIdx.x] = temp;
__syncthreads();
//sum stare for shared memory per block
for(int length=BLOCK_SIZE / 2;length>0;length /= 2){
int stage_sum=0;
if(threadIdx.x < length){
stage_sum = sum_per_block[threadIdx.x] + sum_per_block[threadIdx.x+length];
}
__syncthreads();
if(threadIdx.x < length){
sum_per_block[threadIdx.x] = stage_sum;
}
__syncthreads();
}
if(blockDim.x * blockIdx.x < count){
if(threadIdx.x==0){atomicAdd(output, sum_per_block[0]);}
}
}
int _sum_cpu(int *ptr, int count)
{
int sum = 0;
for (int i = 0; i < count; i++)
{
sum += ptr[i];
}
return sum;
}
void _init(int *ptr, int count)
{
uint32_t seed = (uint32_t)time(NULL); //make huan happy
srand(seed); //reseeding the random generator
//filling the buffer with random data
for (int i = 0; i < count; i++) ptr[i] = rand();
}
double get_time()
{
struct timeval tv;
gettimeofday(&tv, NULL);
return ((double)tv.tv_usec * 0.000001 + tv.tv_sec);
}
int main()
{
//**********************************
fprintf(stderr, "filling the buffer with %d elements...\n", N);
_init(source, N);
//**********************************
//Now we are going to kick start your kernel.
cudaDeviceSynchronize(); //steady! ready! go!
fprintf(stderr, "Running on GPU...\n");
double t0 = get_time();
_sum_gpu<<<BLOCKS, BLOCK_SIZE>>>(source, N, final_result);
CHECK(cudaGetLastError()); //checking for launch failures
CHECK(cudaDeviceSynchronize()); //checking for run-time failurs
double t1 = get_time();
int A = final_result[0];
fprintf(stderr, "GPU sum: %u\n", A);
//**********************************
//Now we are going to exercise your CPU...
fprintf(stderr, "Running on CPU...\n");
double t2 = get_time();
int B = _sum_cpu(source, N);
double t3 = get_time();
fprintf(stderr, "CPU sum: %u\n", B);
//******The last judgement**********
if (A == B)
{
fprintf(stderr, "Test Passed!\n");
}
else
{
fprintf(stderr, "Test failed!\n");
exit(-1);
}
//****and some timing details*******
fprintf(stderr, "GPU time %.3f ms\n", (t1 - t0) * 1000.0);
fprintf(stderr, "CPU time %.3f ms\n", (t3 - t2) * 1000.0);
return 0;
}















 362
362

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









