







引用
https://www.imooc.com/article/details/id/40903
20230925
Python sklearn.svm.SVC() 使用方法
在本文中,我们将介绍Python中sklearn库的svm.SVC()函数。该函数是用于实现支持向量机(Support Vector Machine, SVM)的方法之一。
目录
简介
支持向量机(Support Vector Machines,SVM)是一个强大的机器学习模型,可用于解决分类、回归或异常检测等问题。它通过在高维空间中找到超平面来最大化类别之间的边界。Python的scikit-learn库提供了一个名为sklearn.svm.SVC()的函数,使得可以方便地应用和实现SVM。
以下是关于SVM的一个直观的图片:
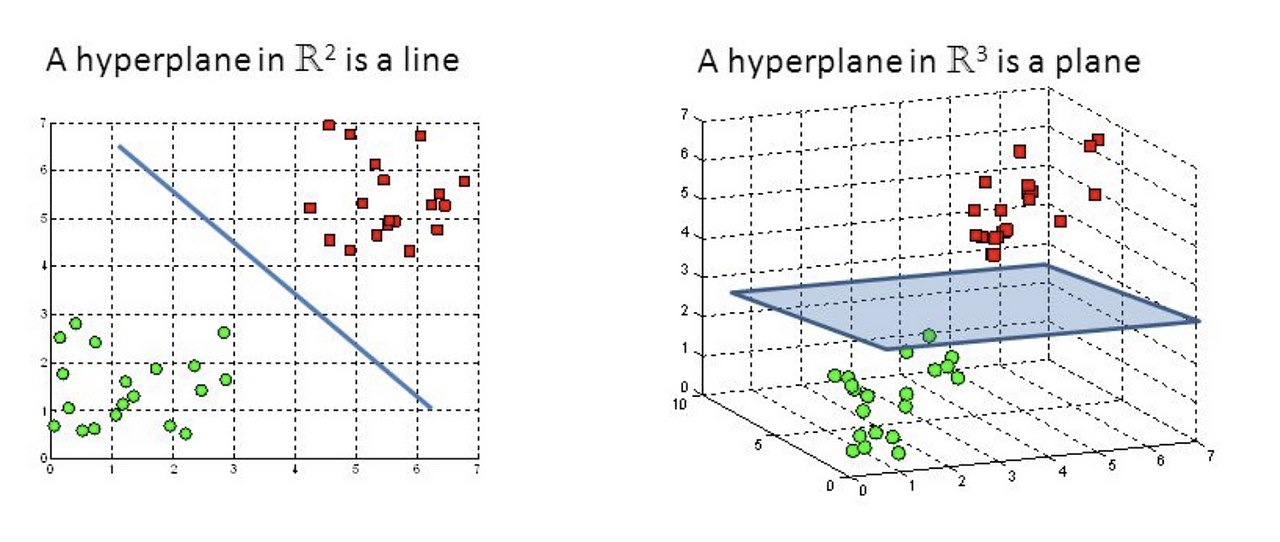
来源:Medium
参数详解
sklearn.svm.SVC()函数有许多可配置的参数,这些参数可以帮助优化模型的性能。下面是一些最重要的参数:
- C:误差项的惩罚参数。C越大,对错误分类的惩罚越大,边界就会更窄。
- kernel:指定SVM内部使用的核函数类型。选项包括 ‘linear’(线性),‘poly’(多项式),‘rbf’(径向基),‘sigmoid’,‘precomputed’ 或一个可调用对象。
- degree:如果选择了’poly’核,这将决定多项式的程度。
- gamma:‘rbf’、‘poly’ 和 ‘sigmoid’的核系数。如果γ设为’auto’,那么将使用1/n_features。
如何使用 svm.SVC()
首先,需要安装sklearn库。如果没有安装,可以通过以下命令进行安装:
pip install scikit-learn
然后,导入必要的库,并创建SVC实例:
from sklearn import svm
clf = svm.SVC()
接着,使用fit()方法来训练模型:
clf.fit(X_train, y_train)
其中X_train是特征数据,y_train是标签数据。
最后,可以使用predict()方法进行预测:
predictions = clf.predict(X_test)
其中X_test是测试集的特征数据。
例子:使用svm.SVC()进行分类
在此部分,我们将展示如何使用svm.SVC()对鸢尾花数据集进行分类。首先,导入所需的库和数据集:
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn import svm
from sklearn.metrics import accuracy_score
# 加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data
y = iris.target
然后,将数据划分为训练集和测试集:
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
创建SVM分类器实例,并用训练集数据进行训练:
clf = svm.SVC(kernel='linear', C=1.0)
clf.fit(X_train, y_train)
最后,用测试集进行预测,并计算准确度:
y_pred = clf.predict(X_test)
print('Accuracy: ', accuracy_score(y_test, y_pred))
性能优化与调参
虽然默认的参数可以提供一个基础模型,但往往需要进行一些调整以获得最佳性能。以下是一些可能的方法:
-
网格搜索(Grid Search):这是一种常见的参数调整技术,它会生成一个参数值网格,并对每个组合进行尝试。在sklearn中可以使用
GridSearchCV()函数。 -
交叉验证(Cross Validation):在训练过程中使用交叉验证可以帮助了解模型的稳健性,并防止过拟合。
总结
在本文中,我们介绍了如何使用Python sklearn库中的svm.SVC()函数。我们通过一些基本的示例进行了演示,并讨论了如何调整参数以优化模型的性能。SVM是一个强大的机器学学习工具,但要正确地使用它需要对其工作原理有深入的理解。
参考资料:


















 705
705

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言












{kind=link}