









最近准备学习自然语言处理相关的知识,主要参考《统计自然语言处理·宗成庆》和《Natural Language Processing with Python》,推荐大家阅读。第一篇主要介绍的是NLP的基础知识和概念介绍,其实也是我关于NLP的读书笔记吧,希望对大家有所帮助。
一. 概念介绍
自然语言处理
自然语言处理(Natural Language Processing,简称NLP)技术的产生可追溯到20世纪50年代,它是一门集语言学、数学(代数、概率)、计算机科学和认知科学等于一体的综合性交叉学科。如何让计算机正确、有效地理解和处理人类语言,即“理解人所说的话”是当今具有巨大挑战性的理论和技术问题。近年来应用包括文字识别、语音合成、网络信息监控、不良信息过滤预警、图像识别、情感计算、理解技术、问答系统。
中文信息处理
其中中文信息处理又是NLP重要的一个分支,目前国际上颇具影响力的技术评测,包括机器翻译评测、信息抽取评测、句法分析评测都与汉语密切相关。中文信息处理既有NLP共性的问题,如生词识别、歧义消解等,又有中文本身的问题,如汉语自动分词、词性定义规范问题等。
书籍介绍
《统计自然语言处理》详细介绍了国内学者在汉语语料库和词汇知识构建、自动分词(包括分词方法和命名实体识别)与词性标注、句法分析及口语信息处理等最新研究成果,还包括国际计算语言大会(ACL,刚在北京召开)最佳论文的部分。
本书第1至9章介绍统计自然语言处理的理论,包括预备知识、形式语言与自动机、语料库与词汇知识库、语言模型、隐马尔可夫模型、汉语自动分词与词性标注、句法分析和语义消歧;第10至15章主要介绍统计自然语言处理的应用,包括机器翻译、语音翻译、文本分类、信息检索与问答系统、自动文摘与信息抽取、口语信息处理与人机对话。
关于“理解”
关于“理解”的标准总会想到英国数学家图灵(Turing)在1950年提出的评测标准:如果一个计算机系统的表现(act)、反应(react)和相互作用(interact)都和有意识的个体一样,那么,这个计算机系统就应该被认为是有意识的。
在自然语言处理领域中,人们常用图灵实验来判断计算机系统是否“理解”了某种自然语言的具体准则,如:通过问答系统(question-answering)系统测试计算机系统是否能够正确地回答输入文本中的有关问题;通过文摘生成(summarizing)系统测试计算机系统是否有能力自动生成文本摘要;通过机器翻译(machine translation,MT)系统测试计算机系统是否具有把一种语言翻译成另一种语言的能力等。
二. 自然语言处理研究内容和基本方法
研究内容
自然语言处理研究内容十分广泛,大致如下研究方向:
机器翻译(machine translation):实现一种语言到另一种语言的自动翻译。
自动文摘(automatic summarizing或automatic abstracting):将原文档的主要内容和含义自动归纳、提炼出来,形成摘要或缩写。
信息检索(information retrieval):又称情报检索,就是利用计算机系统从海量文档中找到符合用户需求的相关文档。面向多语言的IR叫跨语言信息检索。
文档分类(document categorization):又称文本分类或信息分类,利用计算机系统对大量的文档按照一定的分类标准(如主题或内容划分)实现自动分类。
问答系统(question-answering system):通过计算机系统对人提出的问题的理解,利用自动推理等手段,在有关知识资源中自动求解答案并作出相应的回应。问答技术有时与语音技术额多模态输入、输出技术,以及人工交互技术等相结合,构成人机对话系统(human-computer dialogue system)。
文字编辑和自动校对(automatic proofreading):对文字拼写、用词,甚至语法、文档格式等进行自动检查、校对和编排。
信息过滤(information filtering):通过计算机系统自动识别和过滤那些满足特定条件的文档信息。主要用于信息安全和防护等。
语言教学(language teaching):借助计算机辅助教学工具,进行语言教学、操练和辅导等。
文字识别(optical character recognition,OCR):通过计算机系统对印刷体或手写体等文字进行自动识别,将其转换成计算机可以处理的电子文本。相对而言,文字识别主要内容属于字符(汉字)图像识别问题,但对于高性能文字识别系统,相关语言理解技术不可或缺。
语音识别(speech recognition):将输入计算机的语音信号识别转换成书面语表示。语音识别也称自动语音识别(automatic speech recognition,ASR)。
文语转换(text-to-speech conversion):将书面文本自动转换成对应的语音表征,又称语音合成(speech synthesis)。
说话人识别/认证/验证(speaker recognition identification verification):对一说话人的言语样本做声学分析,依次判断(确定或验证)说话人的身份。
实际上,我们所能想到的涉及人类语言的任何研究几乎都隐含着计算语言学的问题,这里不再一一列举。
面临困难
自然语言处理涉及形态学、语法学、语义学和语用学等几个层面的问题,其最终应用目标包括机器翻译、信息检索、问答系统等广泛应用领域。其需要面临的关键问题就是——歧义消解(disambiguation)问题和未知语言现象问题。
自然语言中大量存在着歧义现象,无论是词法层次、语法层次,无论哪类语言单位,歧义始终困扰着人们。
eg1 Put the block in the box on the table.
其中"on the table"即可修饰box,也可以限定block。于是可以得到两种不同的句法结构:
a.Put the block [in the box on the table].
b.Put [the block in the box] on the table.
在这个句子中再增加一个介词短语"in the kitchen"可以得到5中可能的分析结构,实际上,这种歧义结构分析的结果数量随着介词短语数目的增加呈指数上升的。
eg2 关于鲁迅的著作.
可以理解为"关于[鲁迅/的/著作]",也可以理解为"[关于/鲁迅]的著作"。汉语中存在很多歧义,我们说“今天中午吃食堂”绝不意味着把食堂吃下去;我们夸奖一个人说“这个人真牛”并不是说这个人是真正的牛。
eg3 知识图谱中也需要解决的歧义现象.
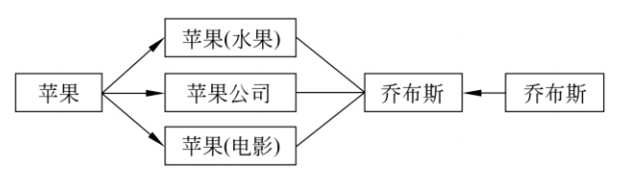
因此自然语言处理系统必须具有较好的未知语言现象的处理能力,对各种可能输入形式的容错能力(系统的鲁棒性)。当然还有很多其他问题,比如如何处理不同语言的差异、如何提取文本特征、资源匮乏、覆盖率低、知识表示困难等。
基本方法
岁月不饶人,将近三十年光阴匆匆地流逝,当年我还是风华正茂的青年人,而今,已经变成了白发苍苍的老人了,我为这个事业坎坷地奋斗了大半生时间,其间甘苦难以言表。三十年来,不论是处于顺境还是逆境,我对于IMAG和GETA始终怀着难分难解的深厚感情,这种感情当然主要是对于我们共同的自然语言处理事业的感情。——冯志伟
还是推荐大家阅读这本很经典的NLP书籍,希望文章对大家有所帮助,至少有个简单的了解~后面可能还会写几篇自己感兴趣的书籍读后感。看到上面这段话,挺感动的,希望自己也能够坚持心中的理想,十年如一日的坚持写博客和教书生涯吧!^_^
(By:Eastmount 2016-08-04 晚上8点 http://blog.csdn.net/eastmount/)



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











