










前面 "Python爬虫之Selenium+Phantomjs+CasperJS" 介绍了很多Selenium基于自动测试的Python爬虫程序,主要利用它的xpath语句,通过分析网页DOM树结构进行爬取内容,同时可以结合Phantomjs模拟浏览器进行鼠标或键盘操作。但是,更为广泛使用的Python爬虫框架是——Scrapy爬虫。这篇文章是一篇基础文章,主要内容包括:
1.Scrapy爬取贵州农产品的详细步骤;
2.Scrapy如何将数据存储至Json或CSV文件中;
3.Scrapy实现三种翻页方法爬取农产品数据。
下面提供前面的一些相关文章:
官方 Scrapy : http://scrapy.org/
官方英文文档: http://doc.scrapy.org/en/latest/index.html
官方中文文档: https://scrapy-chs.readthedocs.org/zh_CN/0.24/index.html
入门安装知识: [Python爬虫] scrapy爬虫系列 <一>.安装及入门介绍
BeautifulSoup:[python爬虫] BeautifulSoup爬取+CSV存储贵州农产品数据
在做数据分析时,通常会遇到预测商品价格的情况,而在预测价格之前需要爬取海量的商品价格信息,比如淘宝、京东商品等,这里作者采用Scrapy技术爬取贵州农产品数据集。
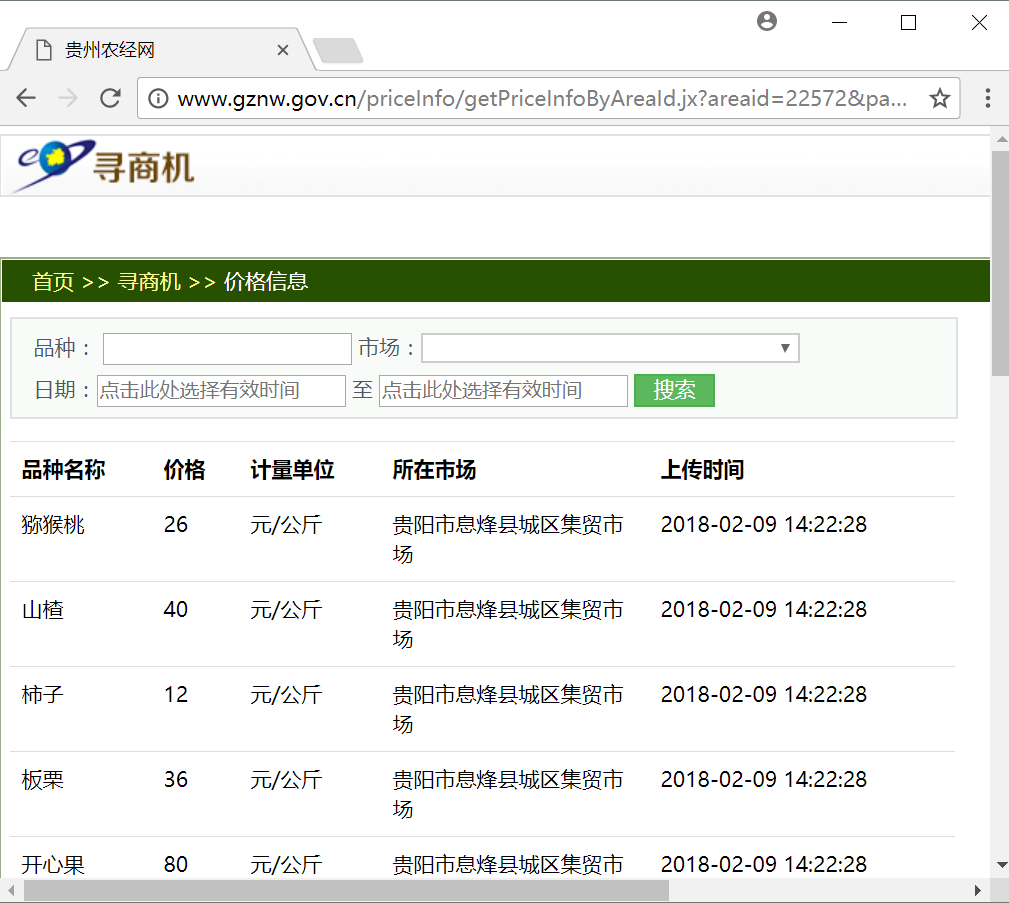
输入 "http://www.gznw.gov.cn/priceInfo/getPriceInfoByAreaId.jx?areaid=22572&page=1" 网址,打开贵州农经网,可以查看贵州各个地区农产品每天价格的波动情况,如下图所示,主要包括五个字段:品种名称、价格、计量单位、所在市场、上传时间。
Scrapy框架自定义爬虫主要步骤如下:
- 在CMD命令行模型下创建爬虫工程,即创建GZProject工程爬取贵州农经网。
- 在items.py文件中定义我们要抓取的数据栏目,对应商品名称、价格、计量单位等五个字段。
- 通过浏览器审查元素功能分析所需爬取内容的DOM结构并定位HTML节点。
- 创建Spiders爬虫文件,定位并爬取所需内容。
- 分析网页翻页方法,并发送多页面跳转爬取请求,不断执行Spiders爬虫直到结束。
- 设置pipelines.py文件,将爬取的数据集存储至本地Json文件或CSV文件中。
- 设置settings.py文件,设置爬虫的执行优先级。
下面是完整的实现过程,重点知识是如何实现翻页爬取及多页面爬取,希望对您有帮助。
一. 创建工程
在Windows环境下,我们调用“Ctrl+R”快捷键打开运行对话框,然后输出“cmd”命令打开命令行模式,然后调用“cd”命令去到某个目录下,再调用“scrapy startproject GZProject”命令创建爬取贵州农经网产品信息的爬虫工程。
创建Scrapy爬虫
scrapy startproject GZProject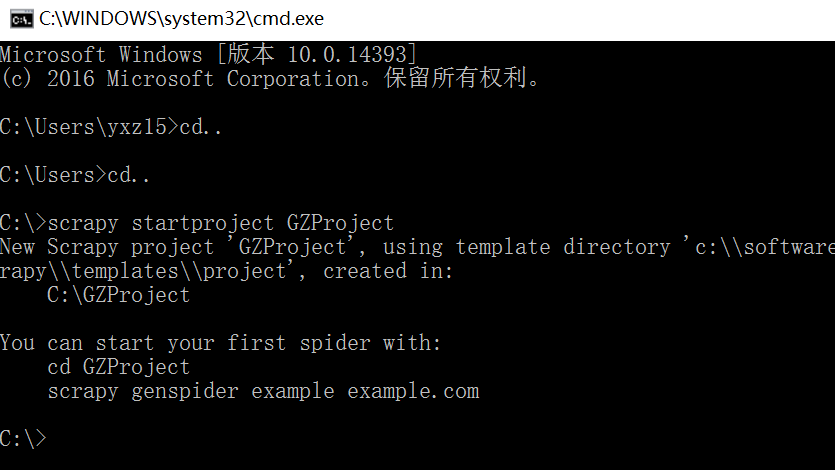
在本地C盘根目录创建的GZProject工程目录如下图所示,包括常见的文件,如items.py、middlewares.py、pipelines.py、settings.py以及文件夹spiders等。

二. 设置items文件
接在我们需要在items.py文件中定义需要爬取的字段,这里主要是五个字段,调用scrapy.item子类的 Field()函数创建字段,代码如下所示。
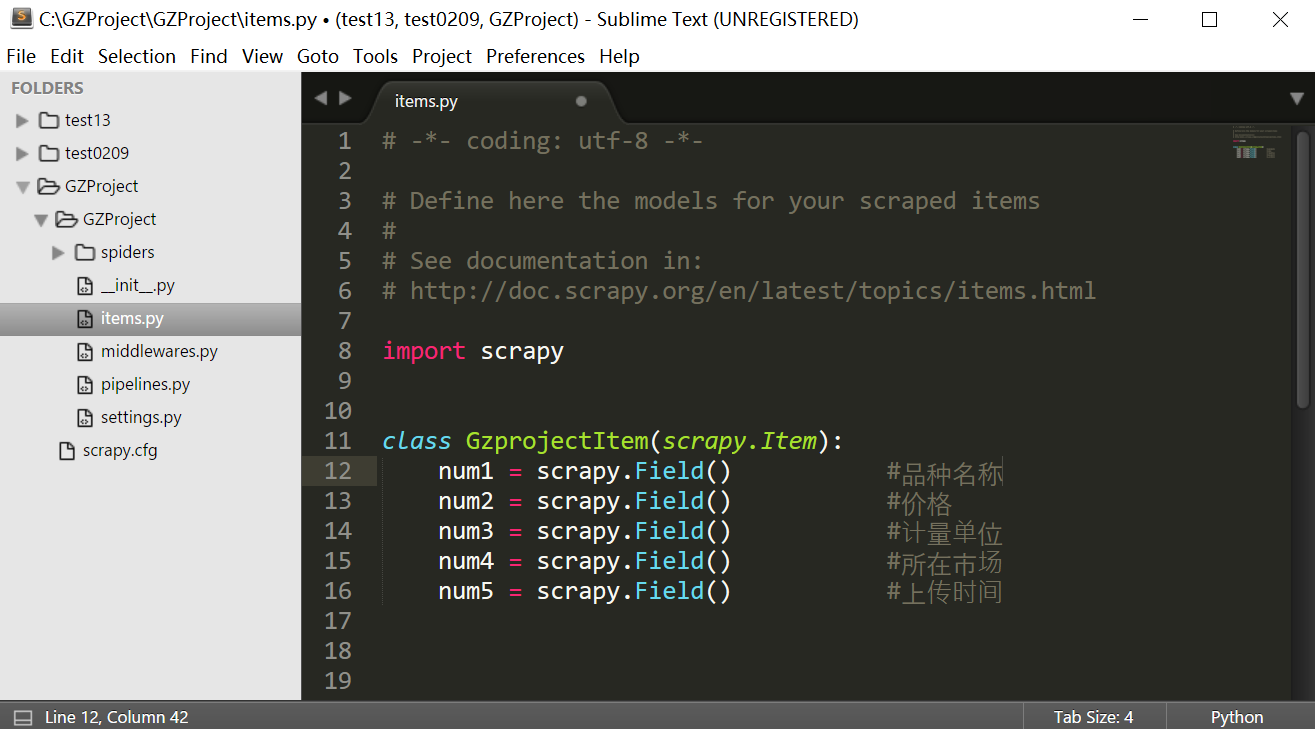
items.py文件的代码如下:
# -*- coding: utf-8 -*-
# Define here the models for your scraped items
#
# See documentation in:
# http://doc.scrapy.org/en/latest/topics/items.html
import scrapy
class GzprojectItem(scrapy.Item):
num1 = scrapy.Field() #品种名称
num2 = scrapy.Field() #价格
num3 = scrapy.Field() #计量单位
num4 = scrapy.Field() #所在市场
num5 = scrapy.Field() #上传时间接下来就是核心内容,通过分析网页DOM结构并编写对应Spiders爬虫代码。
三. 浏览器审查元素
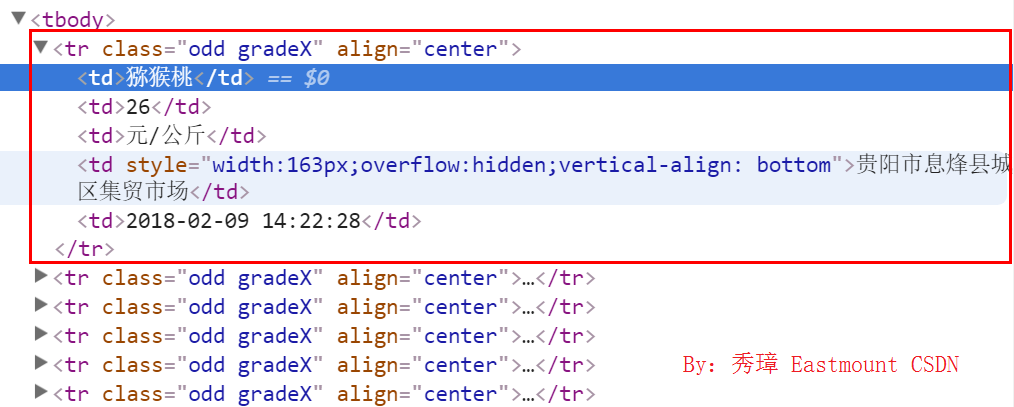
打开任意浏览器,然后调用“审查元素”或“检查”功能(该功能在不同浏览器中称呼不同,但功能都是相似的)查看所需爬取内容的HTML源代码,比如Chrome浏览器定位方法如图13.21所示。选中需要爬取元素,然后右键鼠标,点击“检查”按钮,可以看到元素对应的HTML源代码,比如图中的右边部分。
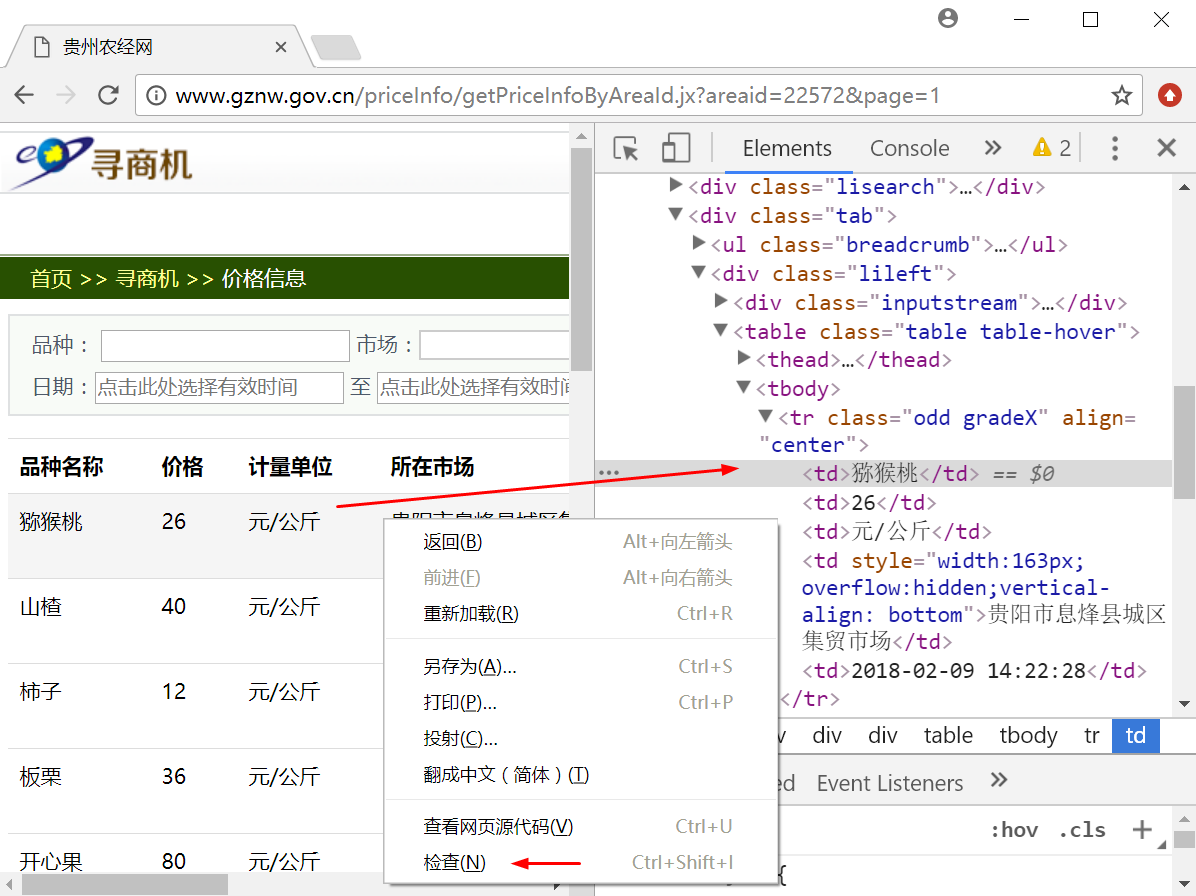
通过审查元素功能,我们可以发现每行数据都位于<tr>节点下,其class属性为“odd gradeX”,如图13.22所示,接着调用scrapy框架的xpath、css等功能进行爬取。
四. 创建Spiders爬虫并执行
然后在spiders文件夹下创建一个Python文件,主要用于实现Spider爬虫代码,创建GZSpider.py文件,工程目录如下图所示。
增加代码如下所示,在GZSpider类中定义了爬虫名(name)为“gznw”,同时代码中allowed_domains表示所爬取网址的跟地址,start_urls表示开始爬取的网页地址,然后调用parse()函数进行爬取,这里首先爬取该网友的标题,通过response.xpath('//title')函数实现。代码如图所示:
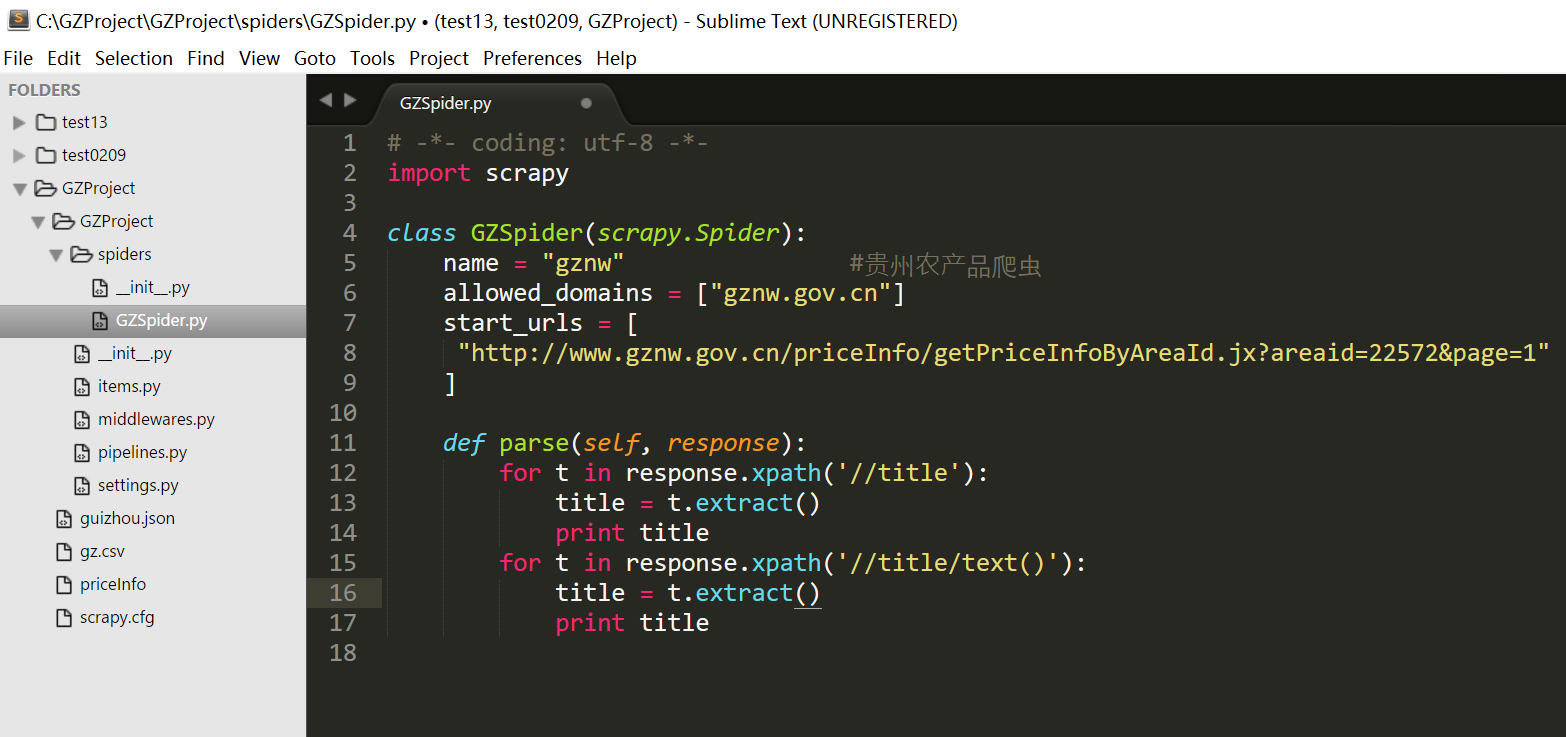
GZSpider.py
# -*- coding: utf-8 -*-
import scrapy
class GZSpider(scrapy.Spider):
name = "gznw" #贵州农产品爬虫
allowed_domains = ["gznw.gov.cn"]
start_urls = [
"http://www.gznw.gov.cn/priceInfo/getPriceInfoByAreaId.jx?areaid=22572&page=1"
]
def parse(self, response):
for t in response.xpath('//title'):
title = t.extract()
print title
for t in response.xpath('//title/text()'):
title = t.extract()
print title
接下来进入C盘工程目录,执行下列命令启动Spider爬虫。
cd GZProject
scrapy crawl gznw"scrapy crawl gznw"启动Spider爬虫,爬取贵州农经网商品,运行如图所示。程序开始运行,自动使用start_urls构造Request并发送请求,然后调用parse()函数对其进行解析,在这个解析过程中可能会通过链接再次生成Request,如此不断循环,直到返回的文本中再也没有匹配的链接,或调度器中的Request对象用尽,程序才停止。
输出结果如下所示,包括爬取的标题HTML源码“<title>贵州农经网</title>”和标题内容“贵州农经网”,如图所示。

接下来我们需要爬取商品信息,调用response.xpath('//tr[@class="odd gradeX"]')方法定位到class属性为“odd gradeX”的tr节点,并分别获取五个td节点,对应五个字段内容。完整代码如下所示:
GZSpider.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
from scrapy.selector import Selector
from GZProject.items import *
class GZSpider(scrapy.Spider):
name = "gznw" #贵州农产品爬虫
allowed_domains = ["gznw.gov.cn"]
start_urls = [
"http://www.gznw.gov.cn/priceInfo/getPriceInfoByAreaId.jx?areaid=22572&page=1"
]
def parse(self, response):
print '----------------Start------------------'
print response.url
for sel in response.xpath('//tr[@class="odd gradeX"]'):
item = GzprojectItem()
num1 = sel.xpath('td[1]/text()').extract()[0]
num2 = sel.xpath('td[2]/text()').extract()[0]
num3 = sel.xpath('td[3]/text()').extract()[0]
num4 = sel.xpath('td[4]/text()').extract()[0]
num5 = sel.xpath('td[5]/text()').extract()[0]
print num1,num2,num3,num4,num5
item['num1'] = num1
item['num2'] = num2
item['num3'] = num3
item['num4'] = num4
item['num5'] = num5
yield item
print '\n'输出内容如下所示,同时调用“item = GzprojectItem()”代码声明了栏目item,再调用“item['num1'] = num1”代码将爬取的数据存储至栏目中。
----------------Start------------------
http://www.gznw.gov.cn/priceInfo/getPriceInfoByAreaId.jx?areaid=22572&page=1
猕猴桃 26 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:28
山楂 40 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:28
柿子 12 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:28
板栗 36 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:28
开心果 80 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:28
草莓 50 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:28
核桃 36 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:28
菜籽油 20 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:28
龙眼 20 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:28
车厘子 100 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:28对应输出内容如图所示。
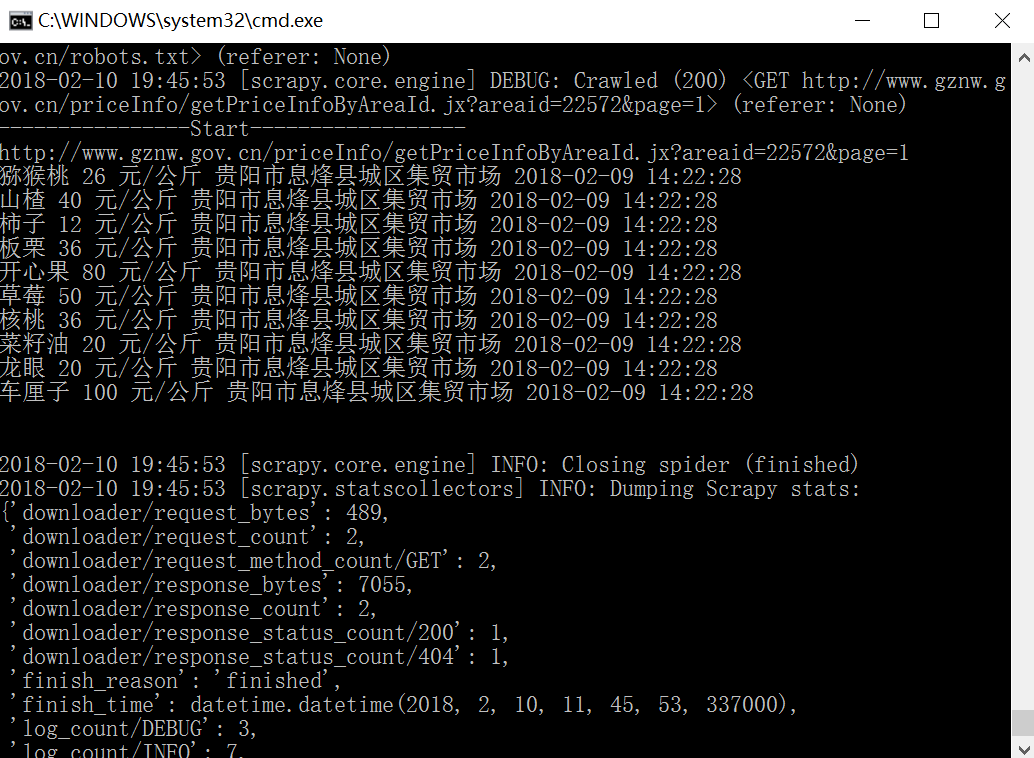
讲到这里,我们已经将贵州农经网第一页的商品信息爬取了,那其他页面的信息,不同日期的商品信息如何爬取呢?Scrapy又怎么实现跳转翻页爬虫呢?
五. 实现翻页功能及多页面爬取
接下来我们讲解Scrapy爬虫的三种翻页方法供大家学习。当然还有更多方法,比如利用Rule类定义网页超链接的规则进行爬取,请读者下来研究,这里主要提供三种简单的翻页思想。
贵州农经网的超链接可以通过URL字段“page=页码”实现翻页,比如第二页的超链接为“http://www.gznw.gov.cn/priceInfo/getPriceInfoByAreaId.jx?areaid=22572&page=2”,我们访问该超链接就可以获取第二页的商品信息,如下图所示,访问其他网页的原理一样。
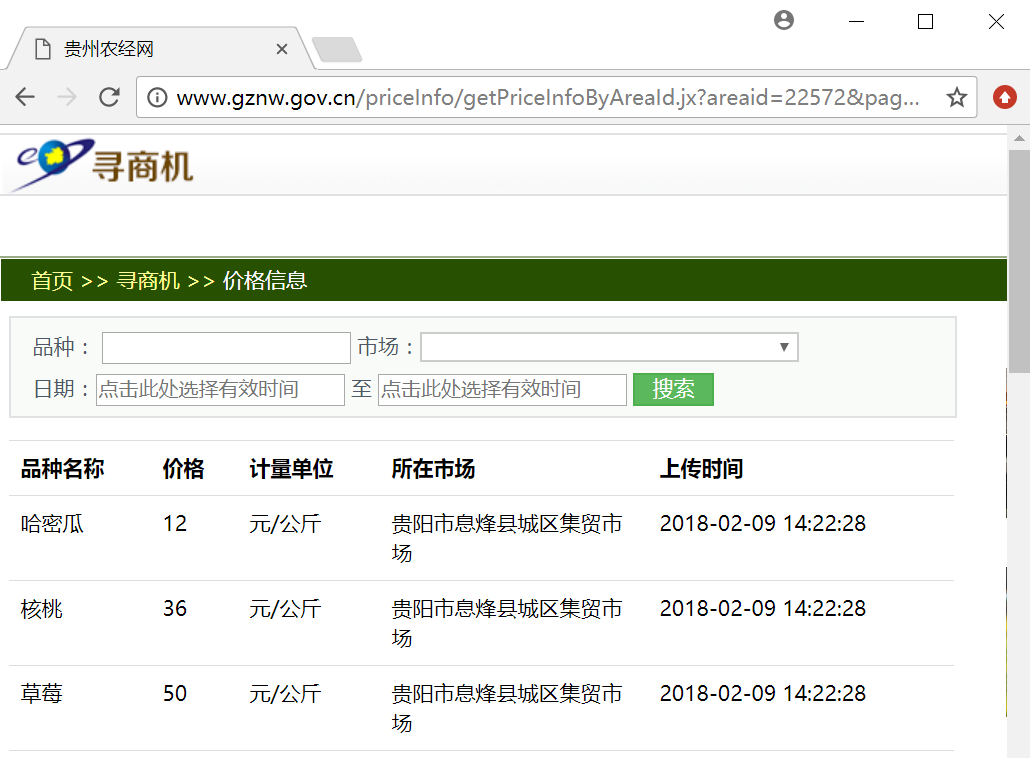
方法一:定义URLs超链接列表单分别爬取
Scrapy框架是支持并行爬取的,其爬取速度非常快,如果读者想爬取多个网页,可以将网页URL依次列在start_urls中。

# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
from scrapy.selector import Selector
from GZProject.items import *
class GZSpider(scrapy.Spider):
name = "gznw" #贵州农产品爬虫
allowed_domains = ["gznw.gov.cn"]
start_urls = [
"http://www.gznw.gov.cn/priceInfo/getPriceInfoByAreaId.jx?areaid=22572&page=1",
"http://www.gznw.gov.cn/priceInfo/getPriceInfoByAreaId.jx?areaid=22572&page=2",
"http://www.gznw.gov.cn/priceInfo/getPriceInfoByAreaId.jx?areaid=22572&page=3"
]
def parse(self, response):
print '----------------Start------------------'
print response.url
for sel in response.xpath('//tr[@class="odd gradeX"]'):
item = GzprojectItem()
num1 = sel.xpath('td[1]/text()').extract()[0]
num2 = sel.xpath('td[2]/text()').extract()[0]
num3 = sel.xpath('td[3]/text()').extract()[0]
num4 = sel.xpath('td[4]/text()').extract()[0]
num5 = sel.xpath('td[5]/text()').extract()[0]
print num1,num2,num3,num4,num5
print '\n'输出如下图所示,可以看到采用Scrapy爬取了三页商品内容。
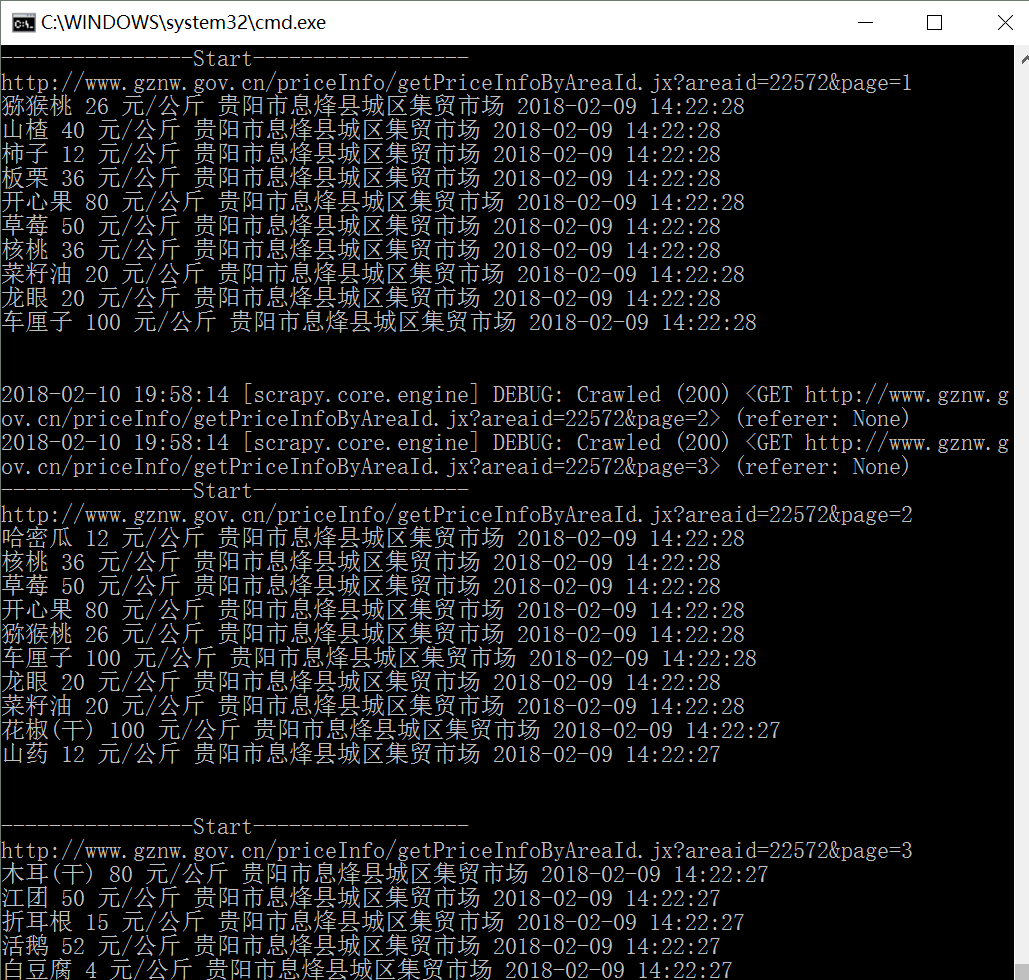
方法二:拼接不同网页URL并发送请求爬取
假设我们的URL很多,如果采用方法一显然是不可行的,那么怎么处理呢?这里我们提出了第二种方法,通过拼接不同网页的URL,循环发送请求进行爬取。拼接方法如下:
next_url="http://www.gznw.gov.cn/priceInfo/getPriceInfoByAreaId.jx?areaid=22572&page="+str(i)在parse()函数中定义一个while循环,通过“yield Request(next_url)”代码发送新的爬取请求,并循环调用parse()函数进行爬取。完整代码如下所示:
GZSpider.py
# -*- coding: utf-8 -*-
import scrapy
from scrapy import Request
from scrapy.selector import Selector
from GZProject.items import *
class GZSpider(scrapy.Spider):
name = "gznw" #贵州农产品爬虫
allowed_domains = ["gznw.gov.cn"]
start_urls = [
"http://www.gznw.gov.cn/priceInfo/getPriceInfoByAreaId.jx?areaid=22572&page=1"
]
def parse(self, response):
print '----------------Start------------------'
print response.url
for sel in response.xpath('//tr[@class="odd gradeX"]'):
item = GzprojectItem()
num1 = sel.xpath('td[1]/text()').extract()[0]
num2 = sel.xpath('td[2]/text()').extract()[0]
num3 = sel.xpath('td[3]/text()').extract()[0]
num4 = sel.xpath('td[4]/text()').extract()[0]
num5 = sel.xpath('td[5]/text()').extract()[0]
print num1,num2,num3,num4,num5
item['num1'] = num1
item['num2'] = num2
item['num3'] = num3
item['num4'] = num4
item['num5'] = num5
yield item
print '\n'
#循环换页爬取
i = 2
while i<=10:
next_url = "http://www.gznw.gov.cn/priceInfo/getPriceInfoByAreaId.jx?areaid=22572&page="+str(i)
i = i + 1
yield Request(next_url)输出部分结果如下所示:
----------------Start------------------
http://www.gznw.gov.cn/priceInfo/getPriceInfoByAreaId.jx?areaid=22572&page=8
豇豆 12 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:25
红薯 12 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:25
老南瓜 15 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:25
菠菜 12 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:25
平菇/冻菌 20 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:25
贡梨 26 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:25
油菜苔 23 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:25
韭菜 15 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:25
绿豆(干) 12 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:25
丝瓜 12 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:25
----------------Start------------------
http://www.gznw.gov.cn/priceInfo/getPriceInfoByAreaId.jx?areaid=22572&page=10
黄瓜 15 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:25
花生油 40 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:25
鹌鹑蛋 20 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:25
血橙 15 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:24
羊肉 240 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:24
莲花白 6 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:24
小葱 12 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:24
绿豆 25 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:24
面粉(标准一级) 6 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:24
脐橙 15 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:24
----------------Start------------------
http://www.gznw.gov.cn/priceInfo/getPriceInfoByAreaId.jx?areaid=22572&page=6
羔蟹 50 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:26
草鱼 50 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:26
青蛇果 36 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:26
红蛇果 32 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:26
芒果 26 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:26
猪肉(肥瘦) 32 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:26
都匀毛尖 1,000 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:26
鲤鱼 60 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:26
鲢鱼 60 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:26
鳝鱼 60 元/公斤 贵阳市息烽县城区集贸市场 2018-02-09 14:22:26方法三:获取下一页超链接请求爬取内容
下面讲解另一种方法,获取下一页的超链接并发送请求进行爬取。通过审查元素,我们可以看到“下一页”对应的HTML源代码如下图所示。
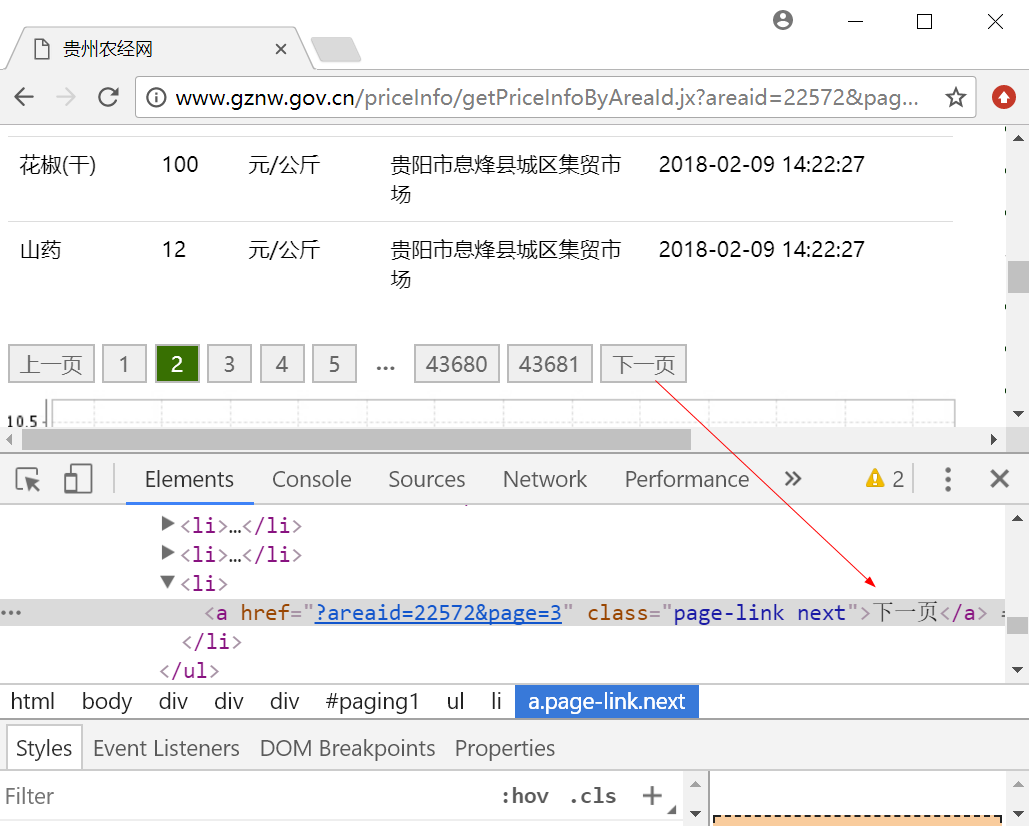
这里我们通过代码获取class为“page-link next”的超链接(<a>),如果存在“下一页”超链接,则进行跳转爬取,如果“下一页”超链接为空,则停止爬取。核心代码如下:
next_url = response.xpath('//a[@class="page-link next"]/@href').extract()
if next_url is not None:
next_url = 'http://www.gznw.gov.cn/priceInfo/getPriceInfoByAreaId.jx' + next_url[0]
yield Request(next_url, callback=self.parse)爬取的结果为"?areaid=22572&page=3",再对获取的超链接进行拼接,得到的URL为"http://www.gznw.gov.cn/priceInfo/getPriceInfoByAreaId.jx?areaid=22572&page=3",再调用Request()函数发送请求,爬取内容。但由于贵州农经网有4万多个页面,建议大家设置爬取网页的数量,代码如下:
i = 0
next_url = response.xpath('//a[@class="page=link next"]/@href').extract()
if next_(url is not None) and i<20:
i = i + 1
next_url = 'http://www.gznw.gov.cn/priceInfo/getPriceInfoByAreaId.jx' + next_url[0]
yield Request(next_url, callback=self.parse)接下来告诉大家如何将爬取的数据存储至本地。
六. 设置pipelines文件保存数据至本地
pipeLine文件是用来对Spider返回的Item列表进行保存操作,可以写入到文件或者数据库中。pipeLine只有一个需要实现的方法:process_item,比如将我们的Item保存到JSON格式文件中,完整代码如下:
pipelines.py
# -*- coding: utf-8 -*-
# Define your item pipelines here
#
# Don't forget to add your pipeline to the ITEM_PIPELINES setting
# See: http://doc.scrapy.org/en/latest/topics/item-pipeline.html
import codecs
import json
class GzprojectPipeline(object):
def __init__(self):
self.file = codecs.open('guizhou.json', 'w', encoding='utf-8')
def process_item(self, item, spider):
line = json.dumps(dict(item), ensure_ascii=False) + "\n"
self.file.write(line)
return item
def spider_closed(self, spider):
self.file.close()
调用codecs.open('guizhou.json', 'w', encoding='utf-8')函数将数据存储至“guizhou.json”文件中,最后设置settings.py文件的优先级。
七. 设置settings文件
在该文件中设置如下代码,将贵州农经网爬虫的优先级设置为1,优先级范围从1到1000,越小优先级越高;“GZProject.pipelines.GzprojectPipeline”表示要设置的通道。
settings.py
ITEM_PIPELINES = {
'GZProject.pipelines.GzprojectPipeline': 1
}最后输入代码“scrapy crawl gznw”执行爬虫,输出部分结果如下所示。
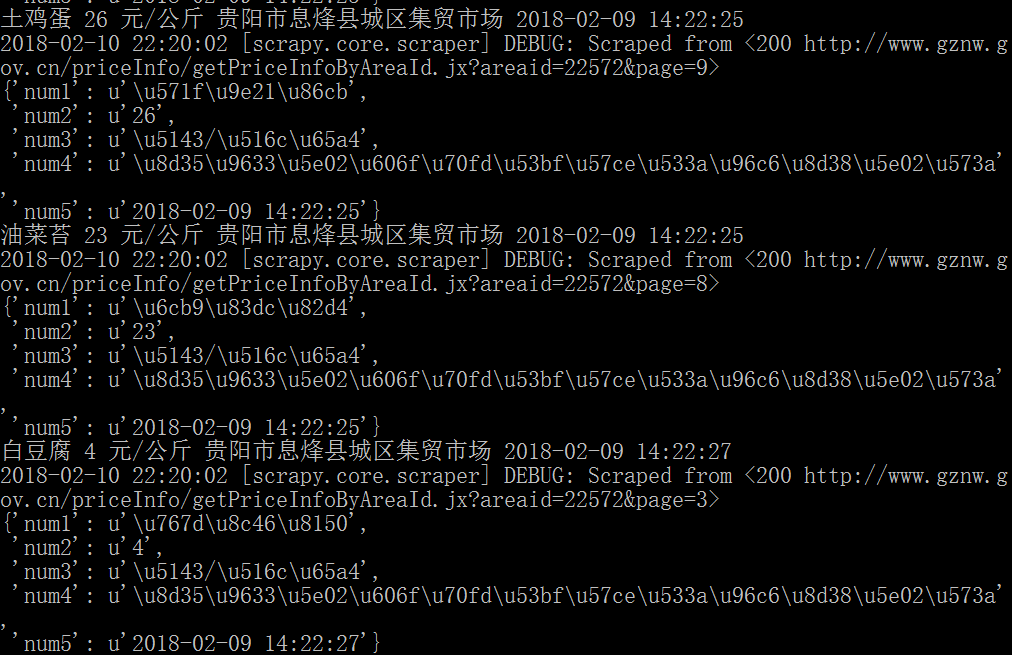
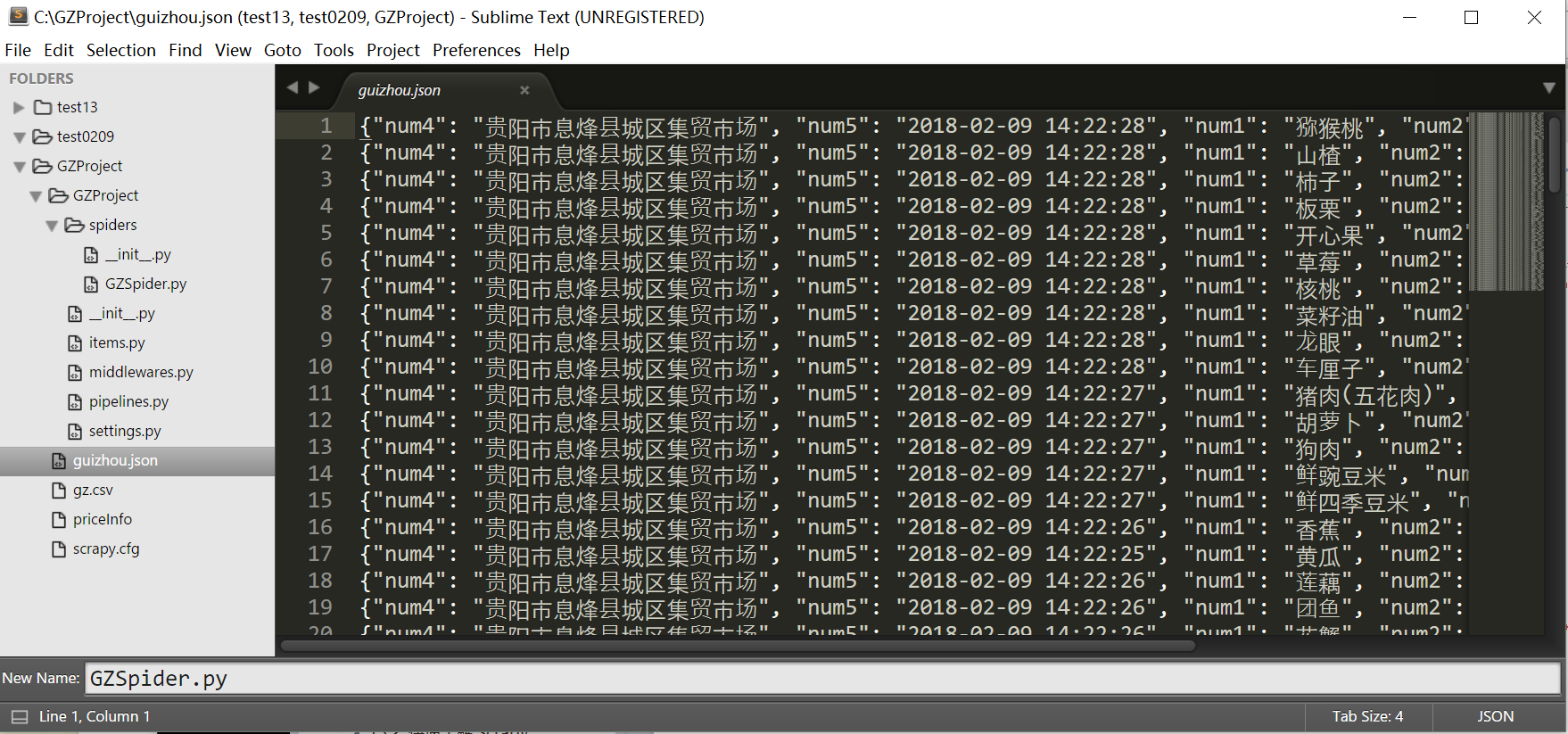
同时,在本地创建的“guizhou.json”文件中保存数据如下所示,采用键值对形式显示。
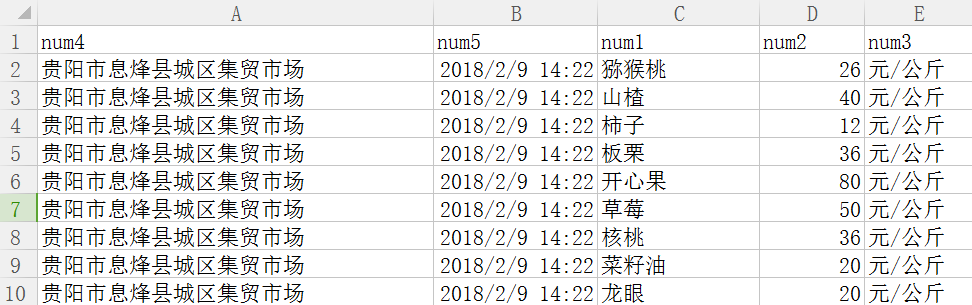
如果读者想存储为CSV文件,则执行“scrapy crawl gznw -o gz.csv”,输出截图如下所示:
写到这里,一个完整的Scrapy爬取贵州农经网的农产品数据已经讲完了,后面我也将继续学习Rule类以及其不同页面的爬取,甚至包括存储至数据库中。更多的爬虫知识希望读者下来结合实际需求和项目进行深入学习,并爬取所需的数据集。
















 5万+
5万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











