







【强化学习】Stable-Baselines3学习笔记
Stable-Baselines3是什么

- Stable Baselines3(简称SB3)是一套基于PyTorch实现的强化学习算法的可靠工具集
- 旨在为研究社区和工业界提供易于复制、优化和构建新项目的强化学习算法实现
- 官方文档链接:Stable-Baselines3 Docs - Reliable Reinforcement Learning Implementations
Stable-Baselines的一些特点:

Q:RL Baselines3 Zoo、SB3 Contrib和SBX (SB3 + Jax)与Stable Baselines3的关系是什么?
A:
- RL Baselines3 Zoo:RL Baselines3 Zoo是一个基于Stable Baselines3的训练框架,提供了训练、评估、调优超参数、绘图及视频录制的脚本。它的目标是提供一个简单的接口来训练和使用RL代理,同时为每个环境和算法提供调优的超参数
- SB3 Contrib:SB3 Contrib是一个包含社区贡献的强化学习算法的仓库,提供了一些实验性的算法和功能。这使得主库SB3能够保持稳定和紧凑,同时通过SB3 Contrib提供最新的算法
- SBX (SB3 + Jax):Stable Baselines Jax (SBX)是Stable Baselines3在Jax上的概念验证版本,提供了一些最新的强化学习算法, 它与SB3相比提供了较少的功能,但在某些情况下可以提供更高的性能,速度可能快达20倍。 SBX遵循SB3的API,因此与RL Zoo兼容
这三个项目都是Stable Baselines3生态系统的一部分,它们共同提供了一个全面的工具集,用于强化学习的研究和开发。SB3提供了核心的强化学习算法实现,而RL Baselines3 Zoo提供了一个训练和评估这些算法的框架。SB3 Contrib则作为实验性功能的扩展库,SBX则探索了使用Jax来加速这些算法的可能性
安装
- Stable-Baselines3 requires python 3.9+ and PyTorch >= 2.3
- Windows的要求:Python 3.8或以上

- 安装命令:
#该命令将会安装 Stable Baselines3以及一些依赖项 如Tensorboard, OpenCV or ale-py
pip install stable-baselines3[extra]
#该命令仅安装 Stable Baselines3 的核心包
pip install stable-baselines3
Example
- 官方示例代码:
import gymnasium as gym
from stable_baselines3 import A2C
env = gym.make("CartPole-v1", render_mode="rgb_array")
model = A2C("MlpPolicy", env, verbose=1)
model.learn(total_timesteps=10_000)
vec_env = model.get_env()
obs = vec_env.reset()
for i in range(1000):
action, _state = model.predict(obs, deterministic=True)
obs, reward, done, info = vec_env.step(action)
vec_env.render("human")
# VecEnv resets automatically
# if done:
# obs = vec_env.reset()
与直接使用gymnasium环境的不同之处
gymnasium.make之后,还需要创建vec_envvec_env = model.get_env()- 环境的reset使用vec_env.reset()
- VecEnv仅需在训练开始时reset,训练中无需手动reset,具体请看上述代码中最后的注释部分
Reinforcement Learning Tips and Tricks
- 强化学习与其他机器学习方法不同之处:训练的数据由智能体本身收集Reinforcement Learning differs from other machine learning methods in several ways. The data used to train the agent is collected through interactions with the environment by the agent itself(compared to supervised learning where you have a fixed dataset for instance).
- 这种依赖会导致恶性循环:如果代理收集到质量较差的数据(例如,没有奖励的轨迹),那么它就不会改进并继续积累错误的轨迹。This dependence can lead to vicious circle: if the agent collects poor quality data (e.g., trajectories with no rewards), then it will not improve and continue to amass bad trajectories.
VecEnv相关
- stable-baselines使用矢量化环境(VecEnv)
- VecEnv允许并行地在一个环境中的多个实例上运行,这样可以显著提高数据收集和训练的效率
- VecEnv支持批量操作(允许模型一次从多个环境实例中学习),可以一次性对所有环境实例执行相同的动作,然后同时获取所有实例的观测、奖励和完成状态
- 在VecEnv中,当一个环境实例完成(即done为True)时,它会自动重置
在stablebaselines中使用自定义环境
- 创建环境类并继承
gymnasium.Env,遵循gymnasium的接口,即包含__init__, reset, step, render等函数 - 检验环境是否遵循了SB3支持的gymnasium接口,需使用
from stable_baselines3.common.env_checker import check_env,检验环境代码如下
from stable_baselines3.common.env_checker import check_env
import gymnasium as gym
from Path.CustomEnvimport CustomEnv
env = CustomEnv(arg1, ...)
# It will check your custom environment and output additional warnings if needed
check_env(env)
碎碎念
-
安装命令
pip install stable-baselines3[extra] -
verbose用于控制训练过程中日志输出的详细程度,0: 不输出任何信息(静默模式);1: 输出基本信息,如每个时间步的奖励、 episode 长度等;2: 输出更详细的信息,包括训练过程中的损失值、策略更新等 -
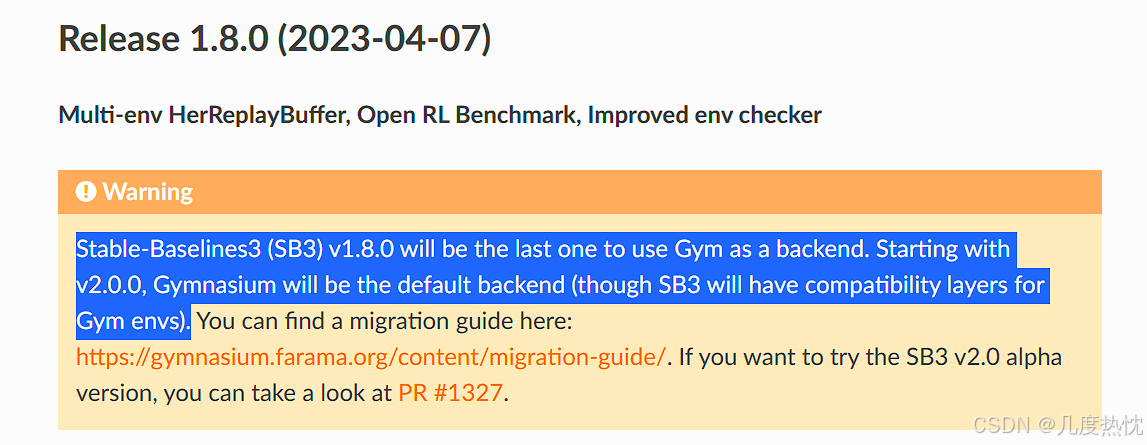
Stable-baselines3 v1.8.0是最后一个默认使用gym的版本,从v2.0.0开始默认以gymnasium作为环境接口
-
创建PPO模型
model = PPO('MlpPolicy', env, verbose=0) -
评估策略的函数为
evaluate_policy(model, env, 评估的回合数) -
训练函数
model.learn(total_timesteps=训练步数, progress_bar=是否显式进度条) -
保存模型
model.save(“保存路径”) -
加载模型
model = PPO.load(“模型路径”),加载模型后 如果继续训练需要为其指定环境model.set_env(env) -
Wrapper是一种用于修改或扩展环境行为的功能强大的工具。Wrapper 允许你在不直接修改环境代码的情况下,对环境的输入、输出或行为进行定制
-
使用Wrapper时,需在定义Wrapper类时继承gym.Wrapper,eg.
class XXXXWrapper(gym.Wrapper): -
gymnasium提供的一些内置wrapper:
TimeLimit:限制每个 episode 的最大步数;ClipAction:将动作裁剪到动作空间的范围内;NormalizeObservation:对观察值进行归一化 -
sb3也内置了一些Wrapper:
VecNormalize:会对state和reward进行Normalize观察值归一化:将观察值标准化为均值为 0、标准差为 1 的分布。
奖励归一化:将奖励标准化为均值为 0、标准差为 1 的分布。
自动更新统计量:在训练过程中动态更新观察值和奖励的均值和标准差 -
Monitor是一个用于记录训练过程中环境交互数据的工具。它可以帮助你收集每个 episode 的奖励、步数等信息,并将这些数据保存到文件中,以便后续分析和可视化from stable_baselines3.common.monitor import Monitor -
环境向量化(vectorization)
DummyVecEnv和SubprocVecEnv都是用于环境向量化的感觉,主要用于强化学习中对多个环境的并行化处理。它们的作用是将多个环境实例包装在一起,从而允许同时运行多个环境,提高训练效率;from stable_baselines3.common.vec_env import DummyVecEnv, SubprocVecEnv

-
DummyVecEnv:通过在同一个进程中运行多个环境实例来实现并行化,env = DummyVecEnv([MyWrapper] * N) -
SubprocVecEnv多进程环境向量化工具,它通过将每个环境实例分配到单独的子进程中来实现并行化env = SubprocVecEnv([MyWrapper] * N, start_method='fork') -
Callback类:用于在模型训练过程中插入自定义逻辑,监控训练过程,例如定期保存模型、评估模型性能、提前停止训练等 -
callback可以访问的变量如下

-
callback使用方法
model.learn(8000, callback=SimpleCallback()) -
make_vec_env也是一个wrapper,等价于下面的四行代码,对MyWrapper外面套一个monitor 然后再套一个DummyVecEnv

-
上述的monitor可以保存日志文件到monitor_dir中,使用
load_results可以加载日志文件,这里找的是models/*.monitor.csv,from stable_baselines3.common.results_plotter import load_results -
ts2xy的主要作用是将通过 Monitor 包装的环境生成的日志文件(通常是 .monitor.csv 文件)转换为两个数组:x 数组:表示时间步(timesteps),即训练过程中每个时间步的累计步数。
y 数组:表示奖励值(rewards),即每个时间步对应的奖励。 -
callback可以同时使用多个,传入一个列表即可

-
加载huggingface中他人训练好的模型 :
load_from_hub
#需要安装huggingface-sb3这个包
pip install huggingface-sb3
from huggingface_sb3 import load_from_hub
#加载其他训练好的模型
#https://huggingface.co/models?library=stable-baselines3
model = PPO.load(
load_from_hub('araffin/ppo-LunarLander-v2', 'ppo-LunarLander-v2.zip'),
custom_objects={
'learning_rate': 0.0,
'lr_schedule': lambda _: 0.0,
'clip_range': lambda _: 0.0,
},
print_system_info=True,
)
evaluate_policy(model, env, n_eval_episodes=10, deterministic=False)
该函数的参数如下:repo_id:Hugging Face Hub 上的仓库 ID,格式为 {organization}/{repo_name}。例如,sb3/demo-hf-CartPole-v1。
filename:仓库中模型文件的名称,通常是一个 .zip 文件。例如,ppo-CartPole-v1.zip
- 一般训练环境和测试环境需要分别make
env_train = make_vec_env(MyWrapper, n_envs=4)
env_test = Monitor(MyWrapper())
- optuna用于寻找最优超参数
study = optuna.create_study(sampler=TPESampler(),
study_name='PPO-LunarLander-v2',
direction='maximize')
- 自定义特征抽取层 需继承
stable_baselines3.common.torch_layers 的 BaseFeaturesExtractor,之后在创建模型时使用policy_kwargs指定
import torch
from stable_baselines3 import PPO
from stable_baselines3.common.torch_layers import BaseFeaturesExtractor
#自定义特征抽取层
class CustomCNN(BaseFeaturesExtractor):
def __init__(self, observation_space, hidden_dim):
super().__init__(observation_space, hidden_dim)
self.sequential = torch.nn.Sequential(
#[b, 4, 1, 1] -> [b, h, 1, 1]
torch.nn.Conv2d(in_channels=observation_space.shape[0],
out_channels=hidden_dim,
kernel_size=1,
stride=1,
padding=0),
torch.nn.ReLU(),
#[b, h, 1, 1] -> [b, h, 1, 1]
torch.nn.Conv2d(hidden_dim,
hidden_dim,
kernel_size=1,
stride=1,
padding=0),
torch.nn.ReLU(),
#[b, h, 1, 1] -> [b, h]
torch.nn.Flatten(),
#[b, h] -> [b, h]
torch.nn.Linear(hidden_dim, hidden_dim),
torch.nn.ReLU(),
)
def forward(self, state):
b = state.shape[0]
state = state.reshape(b, -1, 1, 1)
return self.sequential(state)
model = PPO('CnnPolicy',
env,
policy_kwargs={
'features_extractor_class': CustomCNN,
'features_extractor_kwargs': {
'hidden_dim': 8
},
},
verbose=0)
- 自定义策略网络需继承
torch.nn.Module - sb3 contrib提供了额外的算法
pip install sb3-contrib
#安装该包时 会自动覆盖安装gym
- sb3 contrib提供的算法
- Stable Baselines3 的 Soft Actor-Critic (SAC) 算法中,
gradient_steps参数用于控制每次采样后执行的梯度更新步数,它与train_freq参数配合使用,决定了模型训练的频率和强 - 在 Stable Baselines3 中,VecEnv 的
env_method是一个用于调用向量化环境中每个实例的方法的工具。它允许用户在多个并行环境中执行相同的方法调用,并获取返回结果 - 在 Stable Baselines3 中,
learning_starts是一个重要的参数,用于控制算法在开始学习之前需要收集的初始经验步数。它的主要作用是为算法提供一个“预热”阶段,确保在开始训练之前有足够的数据来稳定优化过程


















 2761
2761

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











