







作者 | 王轶群
责编 | 唐小引
出品丨AI 科技大本营(ID:rgznai100)
很多时候,大模型并不是很听话,业务中的一些故障总是难以被看见,我们需要一双慧眼。
大模型的输入输出充满了不确定性,缺乏可解释性,存在“黑盒”问题。如何进一步观测大模型内部、减少大模型幻觉,对其工作原理进行白盒化处理?可观测性技术与 AI 大模型的紧密结合,就可一定程度解决这个问题。
在 CSDN 与 Boolan 联合主办的 SDCon 2024 全球软件研发技术大会上,我们特设可观测性专题,邀请到来自阿里、小红书、基调听云、Tetrate 的可观测性领域的技术专家,展开分享了对于可观测性技术的深入实践与经验。

LLM 应用可观测系统的重要性毋庸置疑
“大语言模型缺乏可解释性,用户难以判断其回答的内容是否真实、来源是否可靠,模型的资源消耗也很有可能失控,我们需要密切地对它进行持续关注。”阿里云可观测性领域资深专家蔡健表示,这就是可观测性技术在 LLM 领域的用武之地。
蔡健在 SDCon 2024 的现场,带来了《LLM应用可观测解决方案探索与实践》,分享了面向LLM应用技术栈的可观测能力解决方案。

在生成式 AI 创新浪潮下,国内大模型经历了百模大战、降价潮,国内大模型与国外差距越来越少,企业内部数据 AI 需求催生大模型私有化部署,AI 应用生态日渐繁荣,同时催生出丰富的 AI 应用场景。其应用范式包括以 ChatBot、Copilot、Agent 为形态代表的对话应用、RAG 应用、Agent 应用。
在这一背景下,LLM 应用可观测性技术的需求日益凸显。蔡健引用统计数据说明了虽然 2023 年是构建 LLM 应用程序原型的一年,但实际上投入生产的应用程序相对较少的事实——只有大约 10% 的公司将超过 25% 的 LLM 应用程序投入生产;超过 75% 的公司根本没有将任何LLM应用程序投入生产。
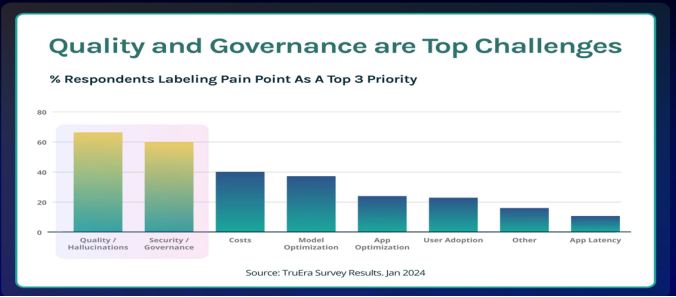
投入生产的比例较低,意味着从构建原型到生产面临着实际的挑战,这也是为什么 LLM 需要可观测性解决方案的原因。蔡健归纳出的原因包括大模型依赖的不确定性、LLM App架构链路长、LLM APP 部署技术栈复杂。
“LLM 是复杂的统计模型,容易出现不可预测的行为。如果没有适当的监控,它们可能会损害业务指标、合规性、品牌声誉和客户信任。”他表示。
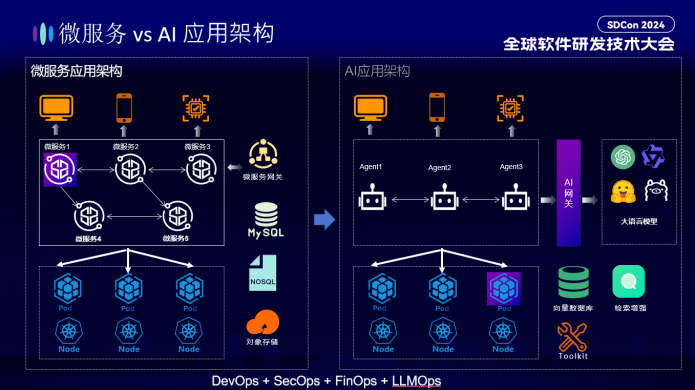
“从架构角度,当需要可扩展性、弹性和解耦时,我们可以实现微服务架构。应用程序的不同组件被解耦并作为独立的服务运行,例如 UI、提示工程系统、RAG 系统、LLM 调用等,每个服务都可以根据需求独立扩展。”他对比了微服务和AI应用架构:“微服务架构侧重于系统架构的灵活性与韧性建设,LLM应用则致力于模型效率与效果的极致追求。两者的可观测能力诉求从关注焦点、数据复杂度、技术挑战、评估指标上存在差异。”
其中,LLM 应用可观测关注点在于性能体验下模型可用性、数据质量、资源效率及成本和领域特点。
基于这样的行业观察,蔡健介绍了阿里云 LLM 应用可观测方案: “以会话串联用户交互问答过程,以Trace承载应用全链路交互节点,通过定义领域化的操作语义,进行标准化存储以及可视化展示关键内容,给开发者提供问题排查的能力。”
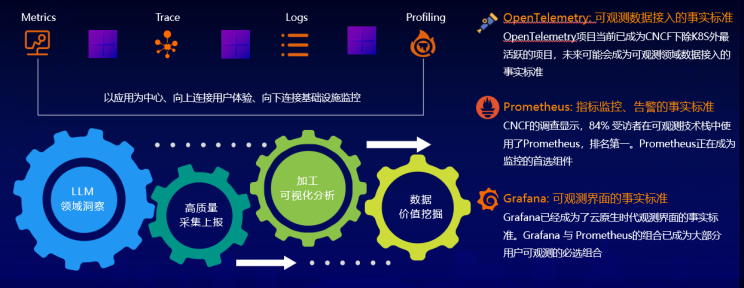
他介绍道,阿里云 ARMS 可观测提供自研探针(JavaAgent、Python、GO、eBPF 等),覆盖 RUM、APM、链路追踪、容器监控以及基础设施监控等,全面拥抱 OpenTelemetry、Prometheus、Grafana 开源标准,为客户提供高可靠、高性能、功能丰富、开箱即用的端到端全栈可观测能力。针对 LLM 应用的可观测解决方案的实现思路,基于 ARMS 可观测平台基础能力,聚焦 LLM 领域洞察,通过高质量的采集加工 LLM 应用产生的 Logs、Metrics、Trace 以及 Profiling 数据进行加工以及提供可视化的分析能力,通过进一步挖掘加工、关联分析上述数据可以最大化释放数据价值。
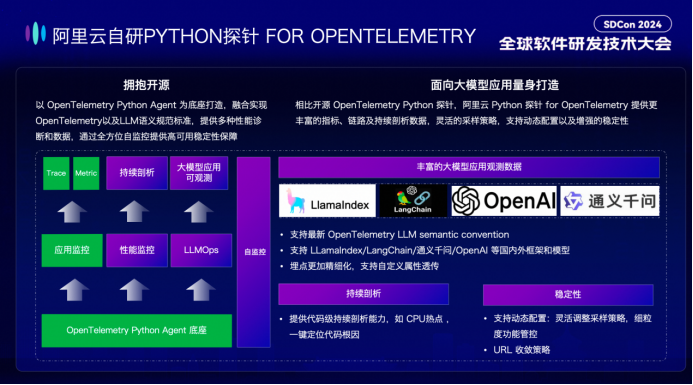
当前LLM应用的主流开发语言为 Python,阿里云推出自研 Python Agent 以便更高质量的采集数据。相比开源实现,阿里云 Python 探针提供更丰富的指标、链路及持续剖析数据,灵活的采样策略,细粒度管控,支持动态配置,提供多种性能诊断和数据,通过全方位自监控提供高可用稳定性保障。同时面向大模型应用进行量身打造,支持最新 OpenTelemetry LLM semantic convention,支持 LLamaIndex / LangChain /通义千问/ OpenAI 等国内外框架和模型,实现埋点更加精细化,同时支持自定义属性透传能力,以满足多样化监测需求。
简单集成的场景可以单独使用 Aliyun Python SDK 仅仅上报调用链数据就可以享受到开箱即用的可观测大盘以及调用链分析和可视化能力。同时也支持集成了开源项目 OpenInference、Openllmetry SDK 的 LLM 应用将数据上报并托管到阿里云可观测服务端。针对多语言以及框架埋点等暂时无法覆盖到的场景,可以基于 OT SDK 参照标准的 LLM Trace 语义实现自定义埋点并上报。阿里云更加推荐使用 Aliyun Python Agent,基于自动化注入能力能够实现无侵入埋点,可以极大地降低LLM应用接入可观测的复杂性以及成本。
另外企业上云的一个痛点问题就是重度依赖云产品服务可用性,端到端链路追踪可以快速定位错慢请求异常节点,提升故障快恢效率,降低业务损失。可观测链路 OpenTelemetry 版与阿里云近10款云产品深度合作,完成了云产品内部链路插桩与数据上报。对于企业用户来说,只需在相应的云产品控制台一键启用链路追踪开关,就可以直接看到相应的调用链,简化了链路采集成本。这一方案,可针对 LLM 应用的 UI 端侧到网关到后端再到组件依赖,打通全链路追踪。
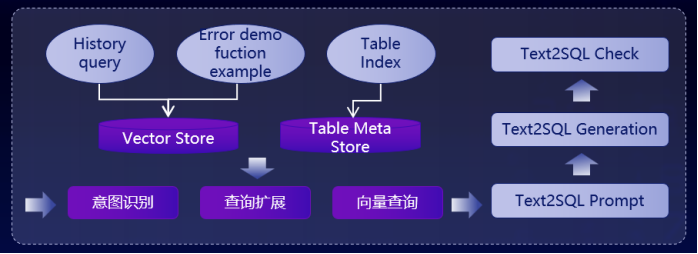
蔡健还分享了 SLS - Text2SQL 可观测案例,针对系统链路复杂排查问题慢、推理成本超出无法及时感知、RAG 上下文查询扩展表现、多轮反馈推理工具调用可观测需求等业务痛点,提供了端到端的全链路追踪进行 LLM Trace 可视化诊断、基于 token 消耗阈值告警以及模型标签对比分析、对问答质量进行评估关联上报快速获知优化效果、Agent 规划以及工具调用详细记录跟踪分析调优的解决方案。
在演讲的结尾,蔡健表示 LLM 应用可观测系统的重要性毋庸置疑,同时提出了四个方面对可观测性技术提出更高要求的挑战:
多模态:支持文本、图片、音频、视频等多模态应用全链路的可观测诉求;对于多元化数据存储以及可观测整体能力提出更高要求。
Agent 进化:Agent 协同、推理过程、记忆能力、连接集成等。
向量&语义化:结合向量语义检索以及语义分类能力,赋予可观测 Trace 更多内涵,方便快速理解、预警、分析排查定位问题,通过 Trace 回放对比输出效果提升调优效率。
安全合规:面临数据泄漏、客户隐私、提示词攻击、输出不合规等问题,可观测自身也需要在权限控制、按需脱敏存储、风险事件监控等方面持续投入。

可观测性要解决“未知的未知”问题
“我们发现,90% 以上的 AIOps 项目其实是未达预期的,其中一个核心的原因就是数据质量未达要求所致,大模型对数据语料的要求非常高,而在 AIOps 项目中缺了一个非常重要的数据质量环节。”基调听云 CTO 杨金全表示。
今年以来,许多 P0 级事故发生。数字化业务复杂性急剧增加、IT 稳定性受到严峻挑战的情况下,他认为,目前IT团队需要变革性的技术,打破数据孤岛,理清系统运行状态,实现更快的故障响应、更准的根因定位、更少的用户影响,确保系统稳定性,驱动数字化转型。
杨金全带来了《APM下一站:统一可观测性》的主题分享,他认为:“APM 应用性能监控可帮助开发者和运维人员诊断和优化系统的瓶颈,提升用户体验,并确保服务的稳定性和高可用性。”

APM(Application Performance Monitoring)是指应用性能监控,是一种系统级别的监控技术,用于实时检测并分析应用程序运行时的性能状况。目前行业内 APM 工具通常会提供可视化的仪表盘和详细的日志,使得问题排查变得更为直观和高效。“最重要的是,我们认为可观测性应该去为用户解决未知的未知问题。”杨金全强调。
他引用了一份来自全球市场的 14,013 名 IT 专业人员的调查结果显示,97%的 IT 从业者迫切需要由监控上升到可观测性,85%的受访者表示可观测性现在是其企业的战略重点。同时,行业内还存在厂商众多数据标准不统一;数据清洗工作量巨大,效果差;数据间关联性差;AI 平台输入输出质量不稳定等问题。
对此,杨金全进一步阐释了可观测性解决方案。他将监控、APM 与可观测性做了如下对比:
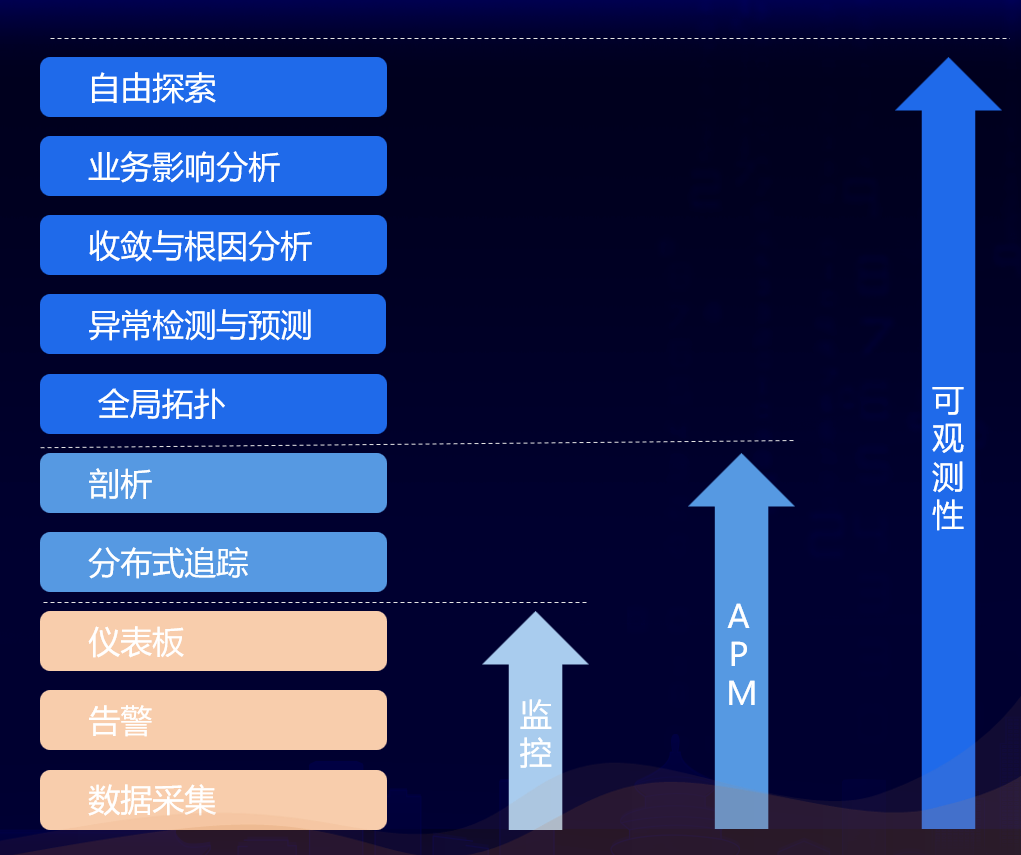
目前来说,建设可观测性平台有四种方法,包括 APM+可观测性、以 eBPF 技术构建、以日志链路构建、以网络流量构建,其中 APM+可观测性是业界公认效果最佳的方案,业界在 APM 构建过程中已经花了大概 10 年的时间。
杨金全进一步指出“以APM为核心是实现统一可观测性的最佳路径。”具体来说,APM 下一站,是以 Tracing 为核心,全景串联业务、操作、请求、网络、中间件、进程、代码、数据库、日志和资源,构建统一可观测性。他解释道:“要效果好,必须要依赖于的 Tracing 技术,也就是 APM 的核心技术。Tracing 可以作为一个中间件,来关联用户的操作及整个资源。”
统一可观测性落地方案上,杨金全介绍了基调听云大模型时代的统一可观测性平台全景。
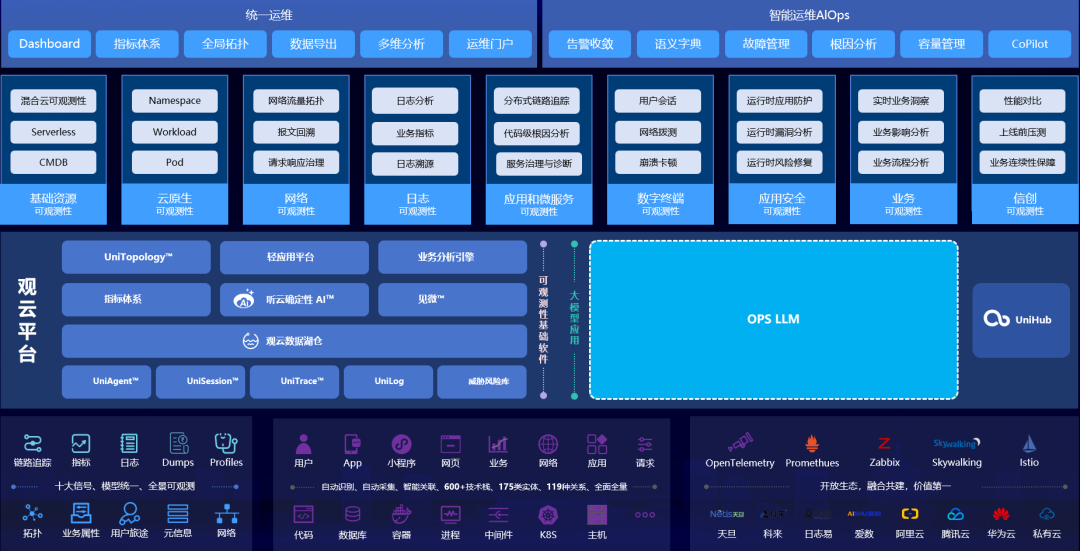
随后他介绍了统一可观测性平台需要落地的几个要素,包括数据治理、拓扑能力等。而其公司产品听云超模态 AI™ ,就包括了 UniAgent™、数据湖仓、多维探索、DEM、轻应用平台。
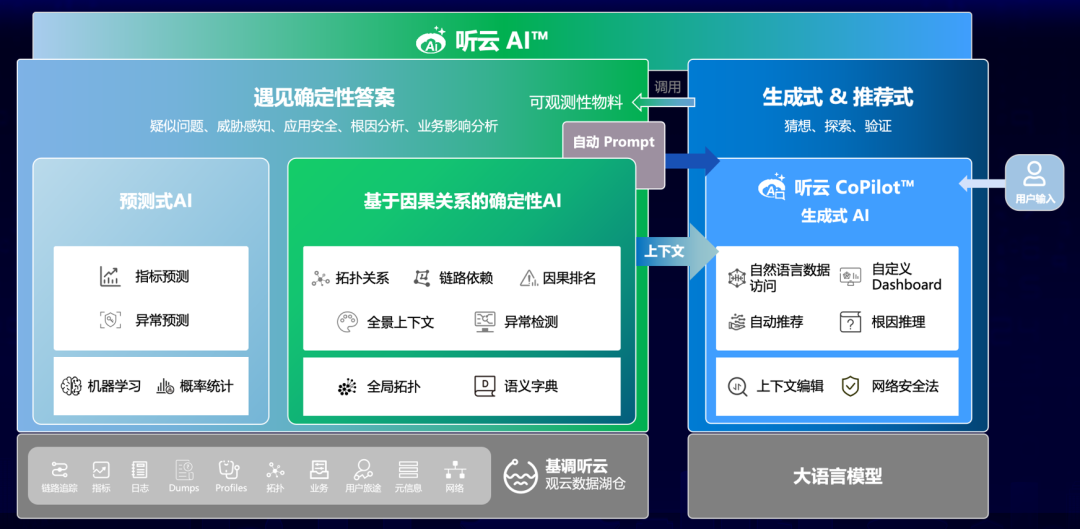
(基调听云超模态 AI™ 体系架构图)
杨金全展示了基调听云数据湖仓全景,分为采集、存储、计算、管理和应用层。

在存算分离上,采用三层池化的存算分离架构,包括算子 Native、冷热数据自动分级处理;采用交互式 OLAP:支持高性能分析,支持资源弹性伸缩。
构建了智能化数据生产线,包括全栈数据 AI4Data,实现数据治理全流程智能化;一键实时数据湖集成,实现一站式任务管理, AutoETL 自动作业,提升集成效率;智能运维,通过血缘分析,实现数据资产管理与数据安全。
在数智融合,其数据湖仓统一模型与元数据:打通数据和模型,支持数据+AI 灵活编排;融合镜像:通过 AI 平台与大数据平台统一融合镜像,支持统一资源调度。
在数据多维探索上,杨金全介绍了其产品见微™,旨在发现维度之间的差异并做深入分析,并分享了其所在的基调听云超模态 AI™ 之基于因果关系的确定性 AI 能力模型。
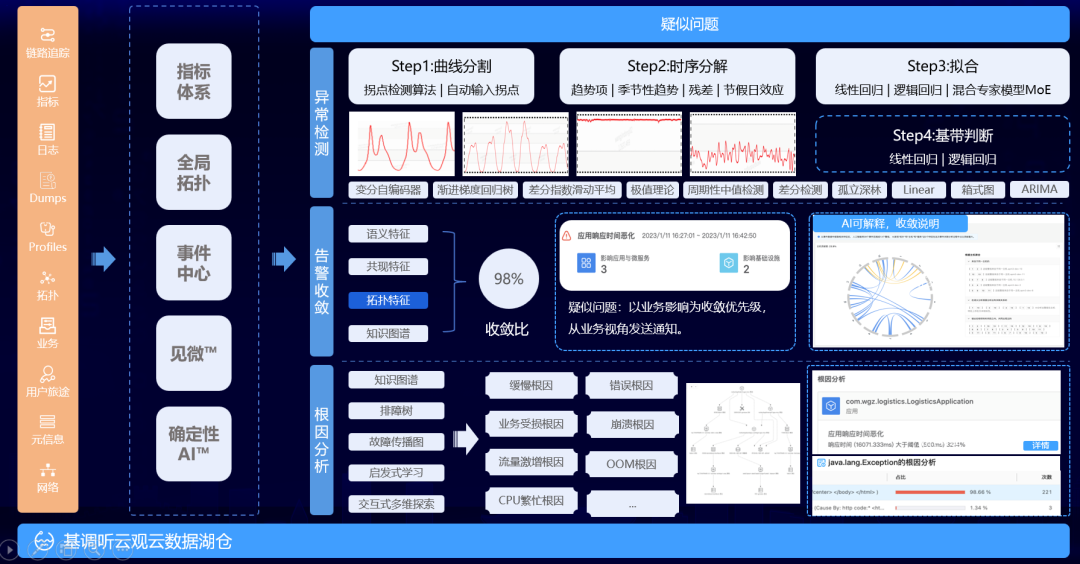
(基调听云超模态 AI™ 之基于因果关系的确定性 AI 能力模型)
基于因果关系的确定性 AI 能力模型,以其开放的可观测能力、轻应用平台,提供低代码的可观测性。据介绍,该模型内置几十款经典和全新的可观测性分析轻应用,其低代码开发框架,提供快速开发和上线新的可观测能力,内置多种前端图表和组件,自定义查询能力,开放 API 支持直接编写 NBQL 探索需求,提供安全的认证和访问控制,数据加密传输,保障数据安全和隐私性。
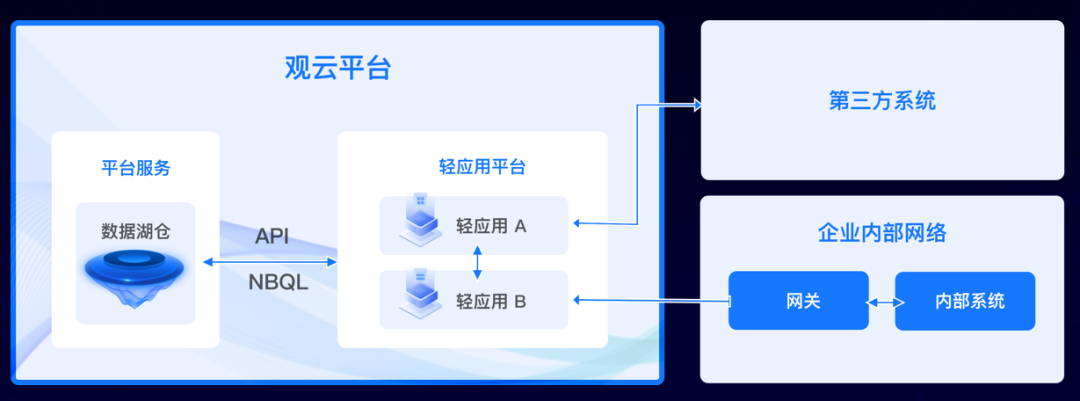
当前行业中 AIOps 解决方案虽然提供了基于机器学习和相关性的能力,但缺乏足够的上下文和解释,仅仅停留在预测层面。随着时间的推移,业务环境和依赖关系的变化,这些结论很快就变得过时。
对此,基调听云通过独特融合 UniAgent™、UniSession™(用户会话)、UniTopology™(全局拓扑)、Service flow™ 和 OneTrace™,助力人工智能引擎听云 AI™ 为用户的环境提供高度准确的确定性答案,应对最复杂的问题。这些答案具有即时性和可解释性,并在当今充满超动态依赖的环境中提供见解。
在基调听云确定性 AI 及大模型落地实践部分,杨金全进一步介绍了听云确定性 AI™ 的功能实现,功能包括通过实时横纵向拓扑理解业务系统依赖和调用关系;实时监测疑似问题并自动分析,理解潜在问题;实时捕获全栈数据,从数据中心到终端应用;实时记录并分析用户旅途与分布式链路追踪;深入到代码级,持续深入洞察代码级性能问题;基于全景上下文,提供应用性能问题的确切原因,并可解释;可对业务影响定量分析,并基于业务优先级收敛、抑制告警;自适应业务变化,自动更新全局拓扑,自主分析性能变化。其大模型应用场景包括自然语言访问数据、自然语言数据总结、分布式链路疑似问题推理。
在企业落地场景上,杨金全介绍其大模型可进行全景可观测、自动根因分析、业务影响分析、客户投诉处理、服务治理,以及应用安全及实时业务洞察:
全景可观测:全局拓扑™通过数据全链接、场景深融合,实现服务治理、业务流程治理、变更影响分析和全局根因诊断。
自动根因分析:融合了预测式 AI、确定性AI和生成式AI的听云AI™,实现全域数据异常检测、问题收敛和自动根因分析。
业务影响分析:通过对关键业务的优先级和影响程度进行评估,使IT运维能够精准对齐业务目标,实时聚焦并满足业务服务水平管理(SLA)。
客户投诉:以用户为中心,融合全域端到端可观测性数据的 UniSession™,像素级还原用户现场,实时疑似问题诊断,快速应对客户投诉。
服务治理:通过 Service Flow™ 实现调用依赖梳理,服务治理、问题诊断和定位瓶颈。
应用安全洞察:通过运行时漏洞感知,运行时风险识别,低成本、零摩擦、智能地实现 DevSecOps,从而以更低的风险更快的业务创新。
实时业务洞察:通过实时的业务可视化和数据驱动的决策支持,确保企业能够快速调整策略,优化运营效率,提高客户满意度,并保持竞争优势。

(应用安全洞察路径)

机遇与挑战并行,小红书云原生可观测实践
小红书可观测负责人王亚普带来了《小红书云原生可观测演进与 AIOps 实践》的主题分享。他介绍道,小红书可观测团队成立于 2022 年,隶属于小红书基础技术部,提供一站式可观测平台,包括监控、分析、查询、告警等基础能力,覆盖小红书所有可观测数据,包括 Metrics / Logging / Tracing / Profiling 四大支柱,服务于公司稳定性建设,提升故障发现、响应、定位效率。
王亚普老师分享了自己看到的小红书内部推动可观测性技术的痛点和挑战,包括监控工具分散且碎片化、使用成本高;数据规模大,系统稳定性差且性能瓶颈严重;缺少使用规范约束,用户大多照葫芦画瓢;存在技术负债,用户使用习惯难改变,造成技术架构演进难度增加。
机会与挑战并行。在优势与机会上,小红书具备以下几点优势,包括云原生接受和使用程度高、开展云原生可观测建设工作满足业界技术发展趋势的需求、 PaaS 垂直领域监控覆盖度高并已具备一定的优势基础,以及有机会实现一站式可观测平台目标,包括系统端、服务端、用户端。
针对小红书现状问题,王亚普老师详细介绍了小红书可观测技术架构的演进思路:
All-in-one 统一可观测平台用户心智,集成公司内部更多生态
避免造轮子:完成现有监控技术体系的深度整合和架构升级
稳定性:建设标准化、高可用、可伸缩、易运维的可观测技术底座
结合故障处理机制流程,提高问题发现、定位、解决的效率
在 Metrics 数据规模上,小红书内的时间序列近两年增长200%,最大时间序列基数超过2000万,给数据查询带来极大的难度。历史 Prometheus 架构,属于单副本,存在诸如稳定性差,存储不定期出现宕机、雪崩等故障等问题,其部署分散,黑屏且管理成本高,且资源成本高、使用体验差。
为此,小红书可观测团队构建了 Metrics 高可用主备架构,能够做到双采双写,并且每个集群副本的数据只有一份。在故障容忍层面,单节点故障不影响整体稳定性;同时采用 VMS 全家桶全面替换 Prometheus,资源占用可节约70%以上,同时推动下线 Thanos,做到资源节省;通过集中式采集管理、配置动态下发,降低运维成本;在弹性可伸缩上做到了服务注册/发现能力,几分钟内能够完成无损扩缩容;通过技术优化解决高密度数据查询性能问题。

(王亚普在 SDCon 2024 介绍小红书可观测团队构建的 Metrics 高可用主备架构)
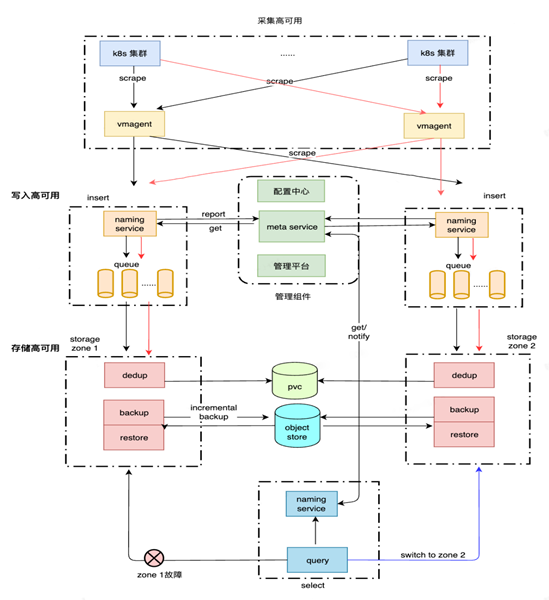
( Metrics 高可用整体架构图)
在 Metrics 写入与查询高可用上,做到了主备双活,即双采双写,同一时间窗口相同指标存储去重;负载均衡:禁用 reroute 机制,按实例名 Hash 将相同时间序列写入同一个存储节点,同时引入本地持久化队列应对存储节点故障情况;容灾切换:数据积压情况上报 meta service,超过积压阈值自动切换集群副本。
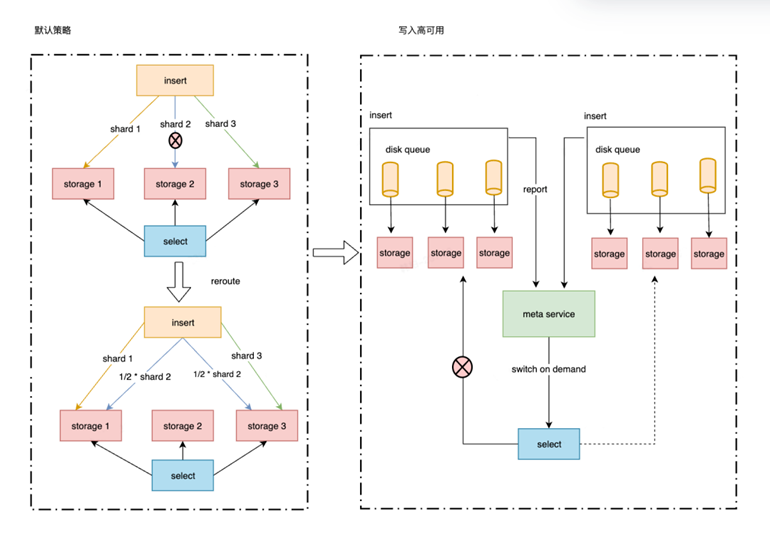
为了提高 Metrics 查询性能和容量,实现计算下推能力。将 sum、avg、max、min、count 等聚合操作下推至存储节点执行,只返回聚合后的数据,可以大幅度减少查询节点获取的数据量。avg 是比较特殊的聚合函数,例如 avg(rate(http_request{code=200}[1m])) ,需要将计算下推过程拆分为 avg = sum/count,在存储节点提前完成 avg 聚合操作会造成计算结果不准确。整体方案落地后有效地解决了查询性能和稳定性问题,在聚合查询场景性能提升10倍以上。
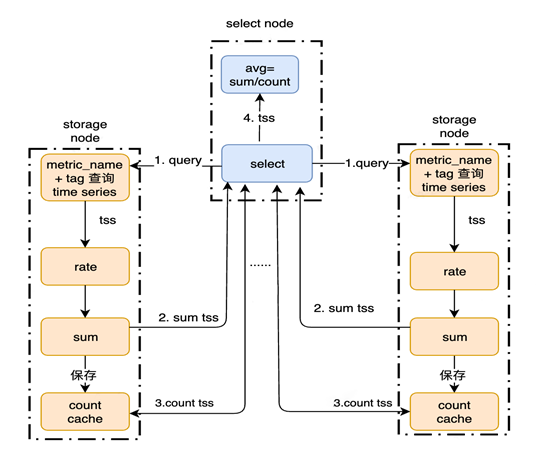
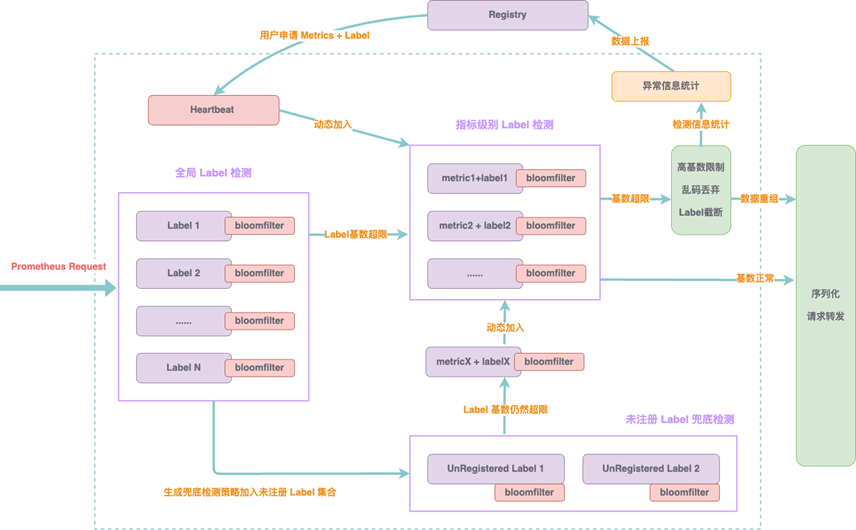
在 Metrics 高基数管理上,通过接入轻量级、可插拔组件,实现了低开销的高基数检测、乱码识别以及用户差异化阈值管理。
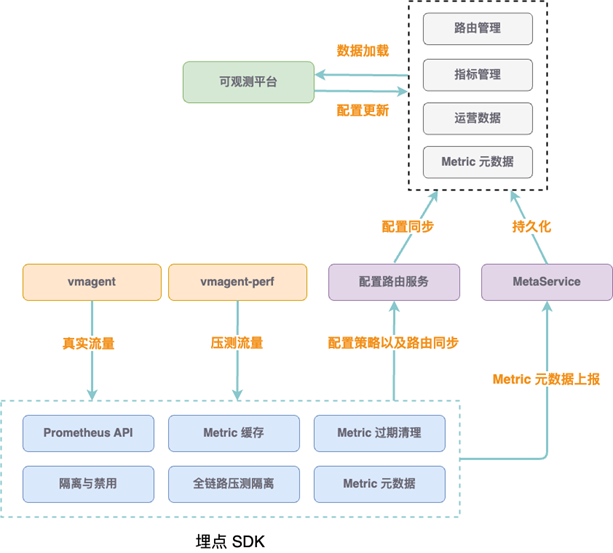
在 Metrics SDK 增强上,引入缓存机制避免用户每次获取 Meter 的性能开销、针对低频时间序列加入过期清理机制节省采集资源;支持全链路压测、业务指标类型拆分(工程+算法),实现指标隔离功能;通过禁用异常指标,实现应急止损;通过 Metric 元数据管理,在产品层做到精细化指标管理,实现产品提效。
Tracing 环节,包括方案选型、协议设计、拓扑分析与指标计算、聚合分析、流量放大预估几个方面。
在方案选型上,小红书可观测团队全盘考虑了业务接受度、研发成本与上线周期、接入成本、稳定性因素,认为字节码增强开发成本高,对业务是个黑盒, SDK 接入业务更容易接受,且 SDK 发版上线已经在内部有成熟的规范,得出了这样的结论:CAT 当前覆盖率和稳定性要好于其他未知的开源方案,如果可以在 CAT 基础上升级分布式链路,是接入和推广覆盖成本最低的一种方式。
Tracing-拓扑分析与指标计算上,小红书可观测采用近实时流式计算拓扑骨架,并使用 Clickhouse 进行存储:CK 存储拓扑节点的边关系,起始节点作为主键索引;使用 SummaryMergeTree 表引擎,用于聚合相同的边。
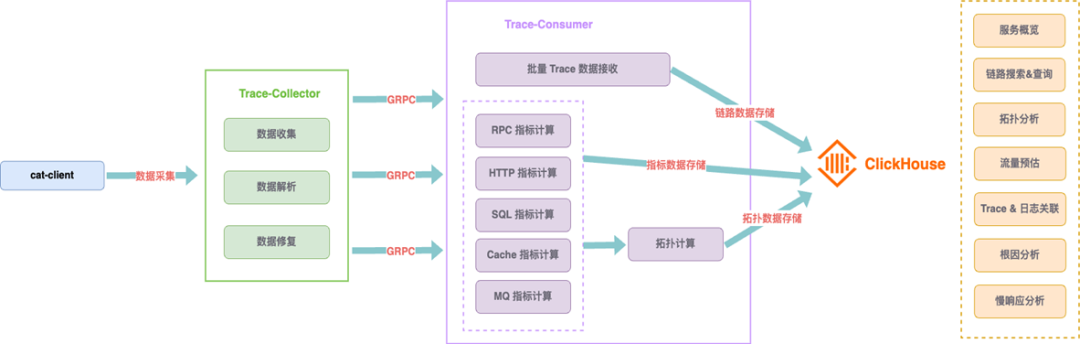
Tracing-聚合分析上,通过对一批样本数据进行聚合分析,可以得出一份慢响应分析报告,主要提供了几种类型的问题检测:慢请求、端到端耗时、重复调用、RPC未触达服务端,更直观地将问题呈现给用户。

Tracing-流量放大预估上,往往面临关系复杂、流量入口难以梳理的问题。王亚普介绍,小红书可观测团队以流量入口为基准设定预估 QPS,可以根据一段时间内 Trace 的真实流量给出所有下游 RPC 调用次数相对于流量入口的放大倍率,用于大促时容量预估非常有帮助。
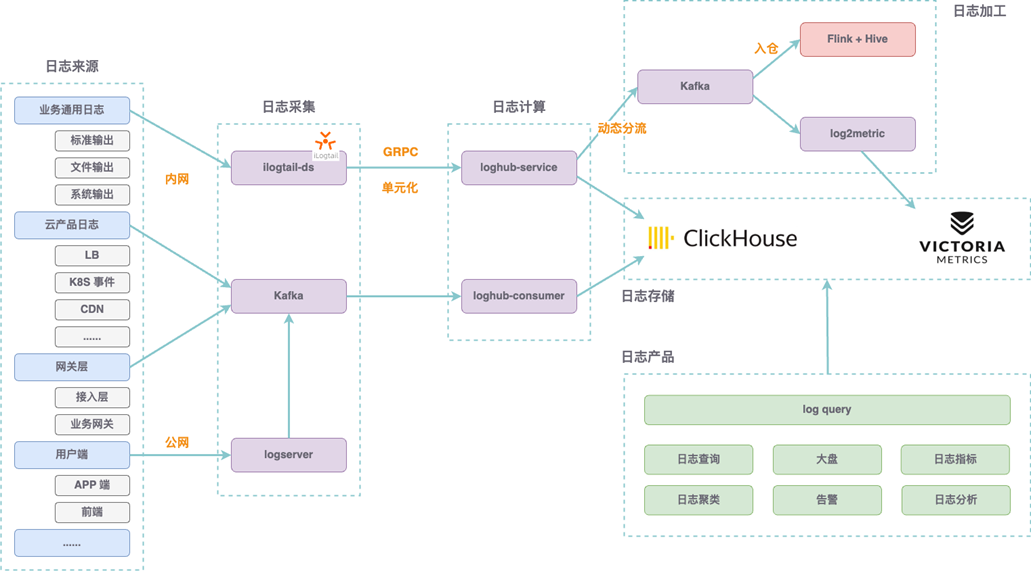
关于日志成本与性能,王亚普分析了其现状与痛点,包括:
成本费用:ELK 成本已经高达几百万/月;
资源开销大:因为资源受限,ES 高峰期大量日志已经出现常态化写入延迟;
存储周期短:压缩率低、索引膨胀,日志一般只存 3 天左右;
日志丢失严重:业务使用不规范造成 filebeat 面对大数据量存在性能瓶颈,无差别限流日志问题严重。
他分享了日志整体架构,图示如下:
Logging 存储设计上,小红书可观测团队按业务分区、不同产品线 TTL 差异化管理,采用云盘 SSD + 本地盘 HDD 实现冷热存储,采用分布式表汇聚多个集群日志数据。
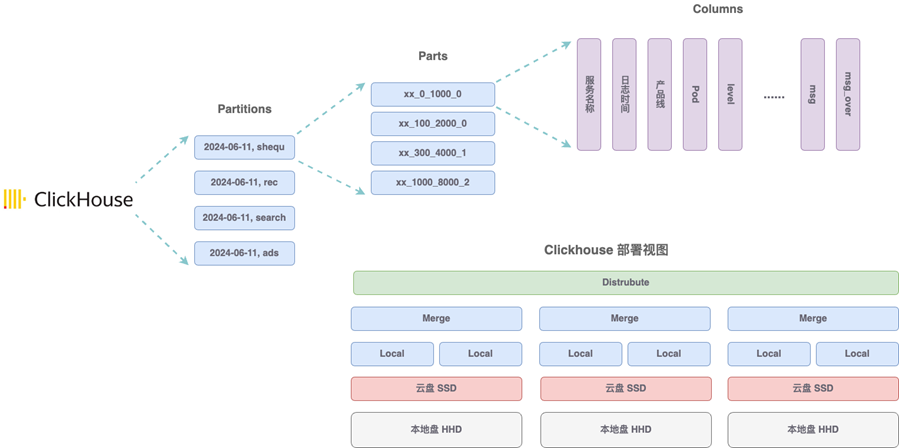
日志索引设计,通过主键结构+二级索引,实现检索优化,针对日志内容字段使用了 tokenbf_v1 索引,对于大日志内容进行分段存储,仅前 8K 进行索引。在日志分析上,提供提供类 SQL 的查询分析能力。
在 Logging 部分,小红书可观测团队还做了日志聚类功能,解决看清日志分布、日志治理等业务问题。在这里,王亚普老师还分享了团队参考的《Drain:一种具有固定深度树的在线日志解析方法》。
论文链接:https://jiemingzhu.github.io/pub/pjhe_icws2017.pdf
在 Profiling 上,王亚普表示小红书内部对性能防退化比较关注,其可观测团队目标是实现持续 Profiling,整体架构具备运维成本低、采集频率可控、熔断策略、支持多语言协议、可灰度的优势。
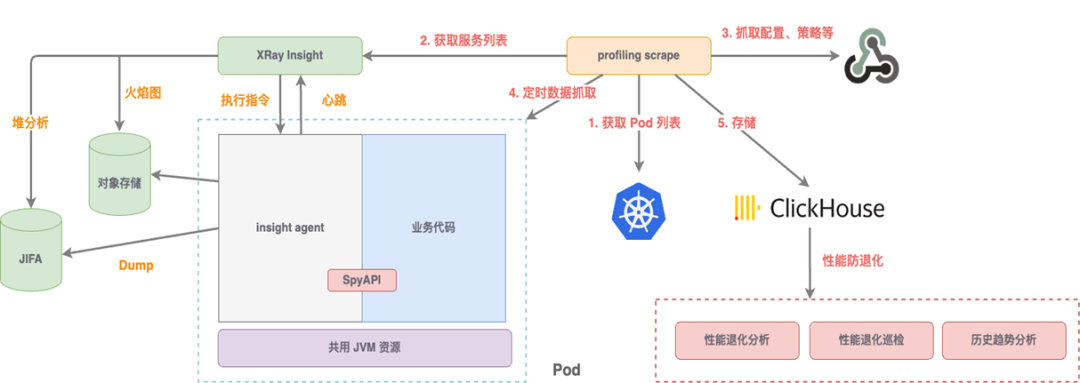
Profiling 针对性能退化问题,可通过对比函数开销历史对比趋势图、性能退化火焰图的分析报告,实现性能退化巡检。Profiling 在小红书的应用场景包括:中间件、可观测、大数据、存储、实验平台、GC 等基础组件;业务 TopK 函数 CPU 核数消耗;正则、String.format、压缩、序列化的通用性能优化;Thread.sleep、业务框架已知的错误用法的 bad-case 经验库。
除了以上四大支柱外,王亚普老师还分享了其 eBPF 在流量分析上的用途,如异常流量识别、老服务下线、共享存储集群成本分摊等;以及正在进行的 eBPF 更多探索,包括具备业务语义的流量分析、跨云带宽可观测、低开销的多言语 Profiling。
故障处理提效与 AIOps 实践部分,王亚普老师分享了故障根因定位技术实现,以及 SLO 稳定性数字化驱动的建设思路和当前进展。
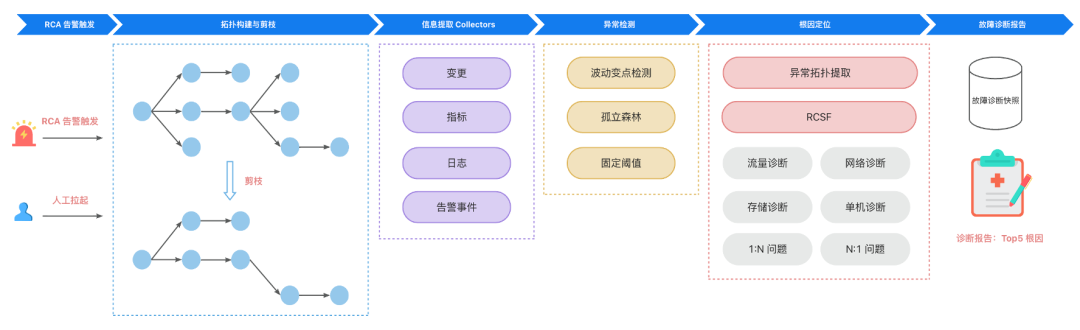
王亚普表示,单纯使用故障驱动不能代表稳定性真的做得好,SLO 是一个更加客观的稳定性度量方式,可以给到用户一个可量化的表现预期。围绕 SLO 数字化运营的目标来建设整个 SLO 体系,目前 SLO 已在上层覆盖了小红书所有的核心业务场景、基础组件和业务中台等。
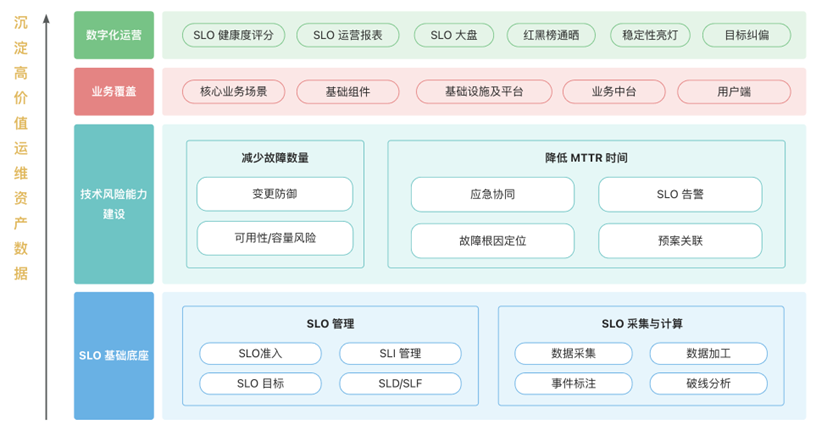
“在未来的规划上,我们还任重而道远。”王亚普表示,他在演讲的结尾对于其可观测性工作提出了五点未来计划:
一体化、标准化、差异化:平台心智、接入规范、更多公司生态;
更高性能、更长周期的数据存储:全局降采样、冷热存储等;
聚焦业务视角和故障洞察,挖掘 AIOps 中更多数据关联分析能力,并建设更多业务视角的排障工具;
技术先进性探索:持续挖掘 eBPF 的落地场景、大模型应用可观测性领域的探索;
稳定性体系:建设面向故障处理、运营的可观测体系,SLO 将作为重点建设的一环,辅助稳定性运营和故障定位提效。

BanyanDB 开源数据库,实现可观测性数据存储优化
“当然现阶段可观测领域一般来讲会有六大柱石,除了传统意义上的 Metrics、Logging、Tracing,还包括 Events、Profile,和 Exception,但最核心的就是这三类的数据。它们在数据信息密度上、存储量上有明显的不同。”Tetrate 创始工程师高洪涛带来了《基于 BanyanDB 的可观测性最佳实践》技术分享开场,先给大家普及了可观测领域的相关知识,包括观测性数据和实际数据。
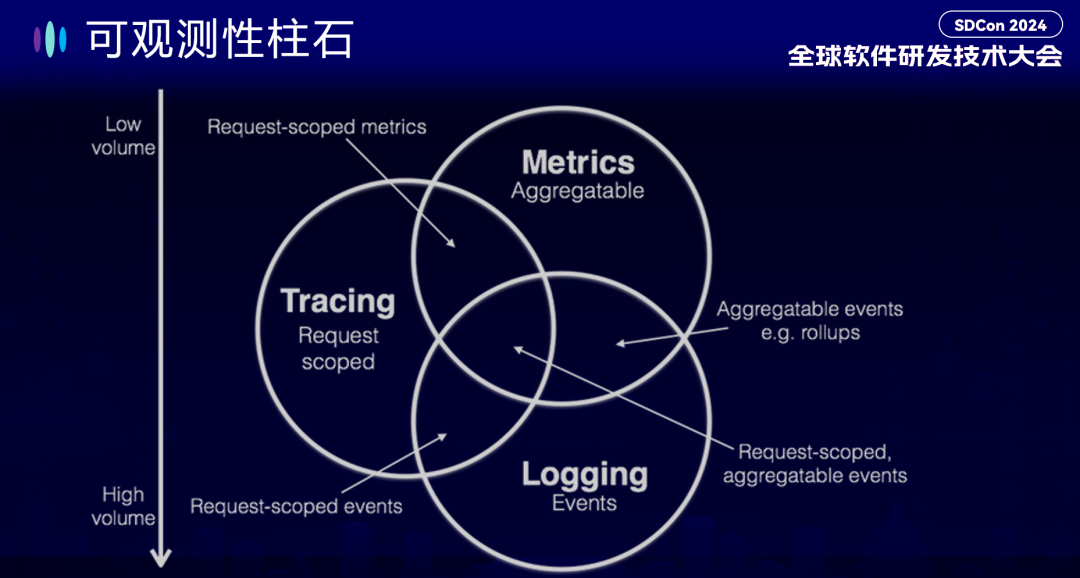
他介绍道:“从上到下可以看到 Metrics 的数据量是很少的,无论是用 Prometheus 还是用别的平台去采集,基本都是有一个时间间隔,大概是 5 秒到 15 秒去抓取一次,它是一些离散的点,有固定的采集频率,数据量非常小,紧接着在 Tracing 和 Logging 的数据量会越来越大。”
他还解释 Tracing 被放在中间位置的原因:“这涉及了一个比较古早的概念,Tracing 当开始出现的时候是有采样的,Tracing 不会 100% 开,会有一定采样频率,1%、1‰ 才会采一次 Tracing 这也是为什么在这张图里位于中间的原因。如果你用 100% 的采样的话,那么 Tracing 的数据量还是非常巨大的。”
Logging 是数据量最大的,被放在了最下面。“除了量巨大以外,Logging 格式也有较强的任意性,这个是无法避免的。即使去规范其格式,但最终呈现出来的有价值信息也不是格式化的。因此需要建设数据搜集,钻取和分析平台将这些数据格式化为有价值的信息。故此, Logging 数据的处理难度非常大。”
而时序数据就是一些随着时间变化的数据值,包括时间序列(Time Series)、键值对(Key- Value)两个核心概念。时间序列由一个名称(通常称为指标,Metric Name)和一系列 Key = Value 标签( Label 或 Tag)组成,比如7天内的天气预报就属于时间序列。
附加在时间序列上还有键值对,这提供给我们这个数据额外的一些信息作为补充。键值对按照时间戳自然排序,每一个数据点一般称为采样(Sample)。高洪涛表示,观测性数据与实际数据有个天然的连接点,就是时间。
他介绍道:时间序列最早从这种监控领域、观测性领域产生的。2013 年以来,时序数据库(Time Series DB)成为数据库行业除了图数据库之外最受关注的数据库类型。时序数据的需求也在随着汽车、能源、IoT、金融等行业的飞速发展而持续上升。与时序数据相关产业的市场规模达5000多亿元,并逐年上升。“目前国内做这种实训类数据库的创业公司起码有 5 家,在不同行业围绕着时序,比如观测类、分析类行业等。”

在上图所示的两种存储方式中,上方是一个经典的时序数据和观测数据的结合存储方式,下方展示了一种更为简洁的存储方式。“我们会倾向于同样序列的 Tracing 数据存储在一起。”那么 SkyWalking 的存储结构是什么样子的?
首先高洪涛介绍了 SkyWalking 目前支持的数据存储类型,由最早的 Traces,到覆盖了前面提到的可观测性数据的六大柱石,包括 Traces、Logs、Events、Error/Execption、Profiles、Metrics。

SkyWalking 产生的数据符合 Rum 假说。这是数据库设计领域的重要假说,由读性能、更新性能、内存性能优化的三个点构成。其原理是,如果优化其两个方向,那第三个方向上必然会出现负面影响。“目前市面上大部分的数据库都会采用读优化,”高洪涛分享了 Database 的词源来自古希腊记录谷仓信息的石板,并表示“目前大部分数据库都对读的性能要求比较高,从而在另两个方向上做一些取舍。”
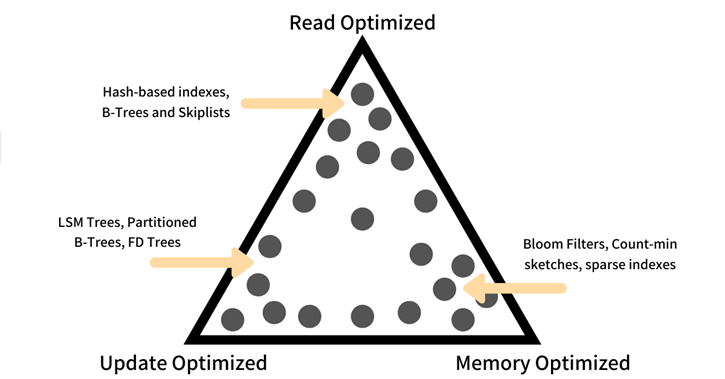
(Rum 假说图示)
他分享了这样的一个观点:“但我们有一个反直觉,对于观测性数据来讲,读的重要性并没有那么高。观测性的数据库设计,我们大胆抛弃了传统方式,把重点放在了内存和写入。这是 SkyWalking 的明显特点也是 BanyanDB 设计的方向。”对此,他解释道 Metrics 数据只做小规模热数据查询,同样 Tracing 和 Logging 数据在系统不出问题的情况下也不需经常查询。
随后,高洪涛介绍了 BanyanDB ,即为 Apache SkyWalking 构建的开源、高性能、可扩展的时间序列数据库。BanyanDB 已经发布了六个版本,在 2023 年的 V0.3.0 中集成了 WebUI、在 V0.5.0 加入了集群功能,在其今年发布的 V0.6.0 把之前的 KV 内核换成了列式。

(高洪涛在介绍 BanyanDB)
高洪涛分享了其数据模型的模式图如下,包括存储节点、分片、段、块几个部分。在存储节点中,他表示目前采用并行的处理模式。
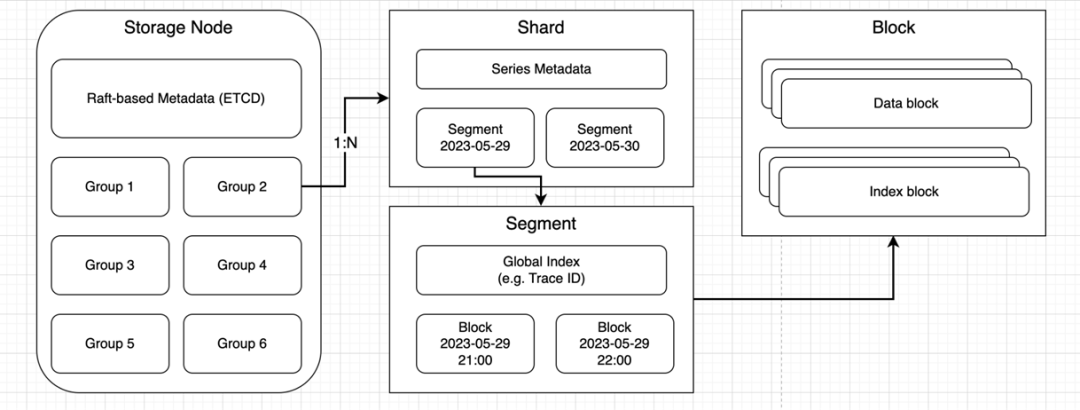
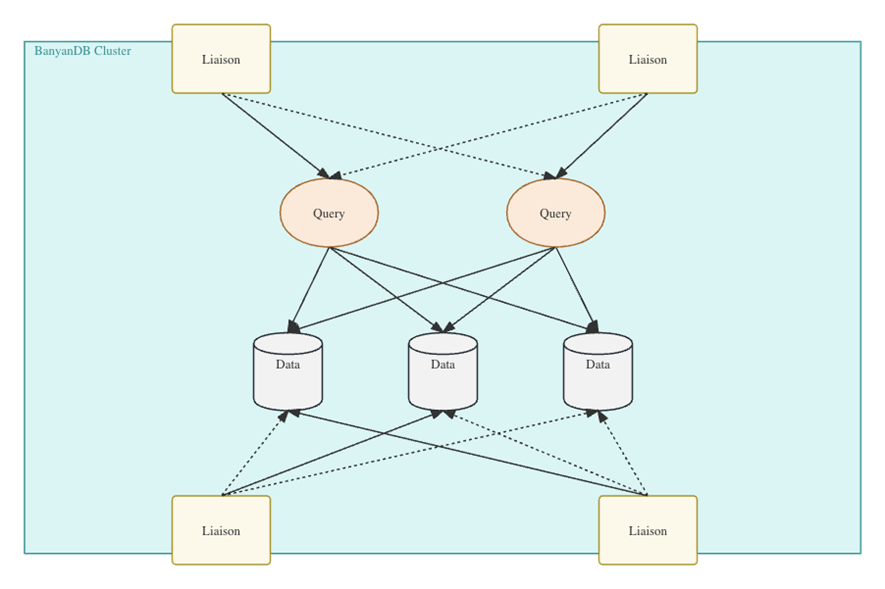
其分布式模式如下图。其中,Liaison 状态节点作为路由入口节点,会独立地计算出数据的拓扑情况,数据会被分散到特定的写入节点上。其写入模式与查询模式存在非常大的区别,在写入阶段数据会被写入特定的分片,在查询时,查询执行器会访问所有节点,而不会去访问数据分片信息。这样的设计可以防止数据节点的故障时系统不可用。这也是 BanyanDB 数据库与其他数据库相比的独特之处。所以BanyanDB是一个面向高可用的数据库。
他表示,其团队目前正在开发中的热数据、温数据和冷数据架构,会采用不同的介质,不同平衡策略来降低数据存储成本。
在数据的有效存储上,分成时间序列后,在同一序列内部存在高度相似性。对高度相似的数据做压缩,会得到一个比较高的压缩率,从而提高数据的存储效率。高洪涛表示,经测算,对 Metrics 的效率可达95%以上,Logging 数据也能达到80%。
对于高基数问题的解决和优化,BanyanDB 对于 Metrics 、Logging、Tracing 数据的存储,会选定 Tags 作为序列标志,可在 schema 阶段进行一个特定选择,而不会选择所有的 Tags 来做序列,从而有效地降低这部分存储。
在介绍 BanyanDB 测试设置时,高洪涛建议数据存储上鼓励大家使用云盘,而不是用数据复制,因为应用级的数据复制代价远远大于云供应商提供的云盘的可靠性的代价。在测试时,他表示给 Elastic 测试的内存会多一点,ES 很耗内存;给 BanyanDB 的 CPU 会多。在磁盘的使用方面,他介绍了其数据库具备的优势在于其整体对磁盘的吞吐量需求较小,对磁盘占用可减少 1/ 3,并且对磁盘的写入保护较好的。

(BanyanDB 测试设置图示)
最后,高洪涛呼吁更多人参与到 BanyanDB 和 SkyWalking的开源项目贡献,包括参与试用、加入社区,并给予反馈,并把产品介绍给更多的开发者。

阿里云 Prometheus 分布式采集探针,突破开源版本采存一体
阿里云基础事业部可观测研发专家隋吉智带来了《阿里云 Prometheus 分布式采集探针在 ASI 超大规模集群场景实践》的技术分享。

隋吉智介绍道,开源 Prometheus Server 模式采用的一体化采集与存储模式,带来了部署便捷的好处,同时也存在数据单点存储不好聚合、采集与查询性能有限的问题。相比之下,这两年很火的开源 VictoriaMetrics 模式,采集与存储分离模式,使得数据聚合灵活性提升、采集和查询性能较高,但在多副本和自适应集群采集的时候,也存在劣势。
阿里云 Prometheus 采用采集与存储分离模式,使得数据聚合灵活性提升、采集和查询性能较高、数据处理链路高可用。
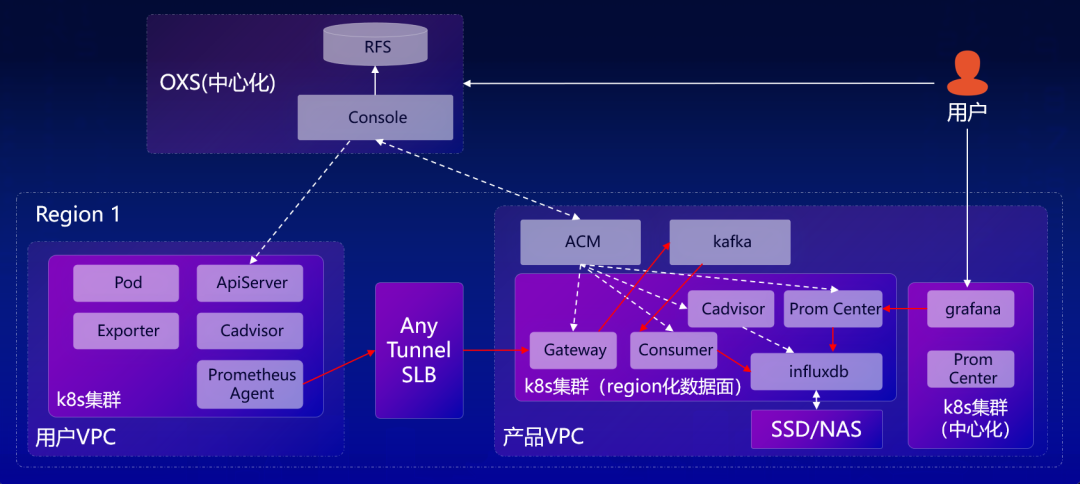
阿里云 Prometheus 分布式采集架构设计部分,他先介绍了其开源 Prometheus AgentMode 模式。这个模式禁止本地的查询、告警、存储,原理为TSDB WAL + RemoteWrite,本质上仍就为通过 RemoteWrite 远程投递数据,并不具备多副本采集能力。
针对上述问题,隋吉智介绍了阿里云 Prometheus 分布式采集探针的两代设计。
阿里云 Prometheus 分布式采集探针第一代设计,将控制面与数据面融合在一起,控制面可承担一定数据采集任务,在小规模集群中一个副本即可实现服务发现和数据采集,从而节省资源开销。
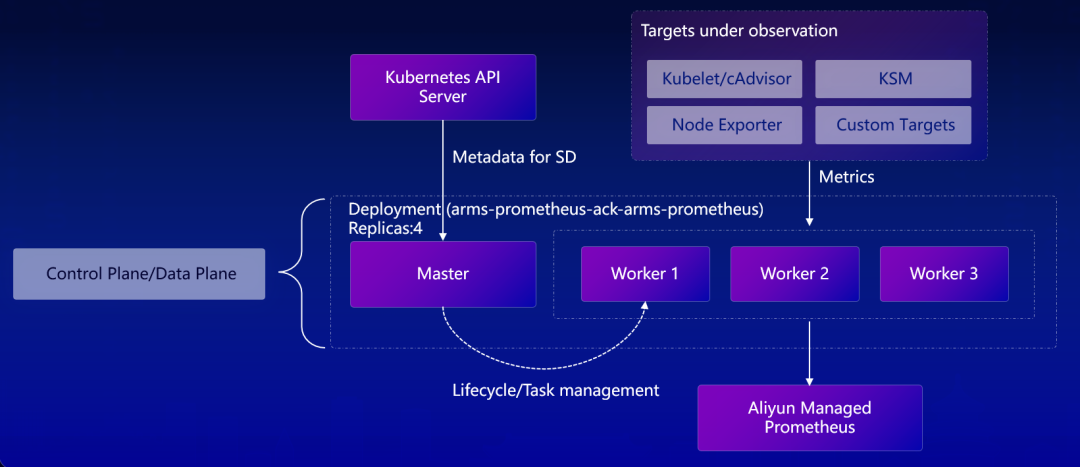
(阿里云 Prometheus 分布式采集探针第一代设计)
在阿里云 Prometheus 分布式采集探针第二代的设计,进一步优化,控制面与数据面拆分,即控制面仅做服务发现,数据面承担全部的数据采集任务。
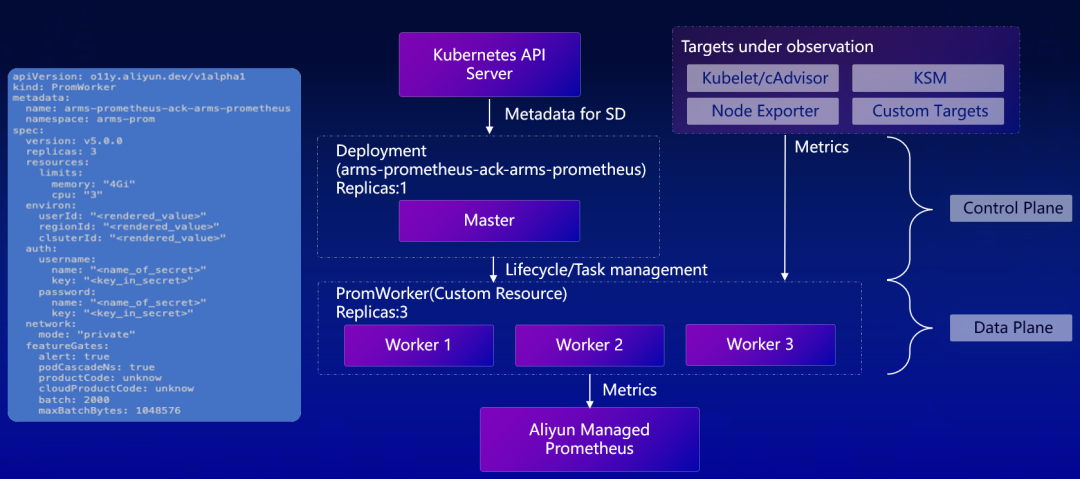
(阿里云 Prometheus 分布式采集探针第二代设计)
“在面对大规模集群的时候,往往一个 Master 是完全不够用的,那我们就把 Master 单独拆出来,只需要做服务发现和预抓取。其好处是仅有一个 Master 跟 K8S API 做交互,对 Master 的访问的压力就会下降,就没有从 Master 到 Worker 角色的一个切换。”隋吉智在解释迭代思路时表示,“第二代开始那就没有这个情况了, Master 就只是做服务发现和预抓取,然后和 Targets 的分配,然后计算需要多少个采集副本,采副本做横向的扩缩容即可,可以减少了故障率并提升稳定性。”
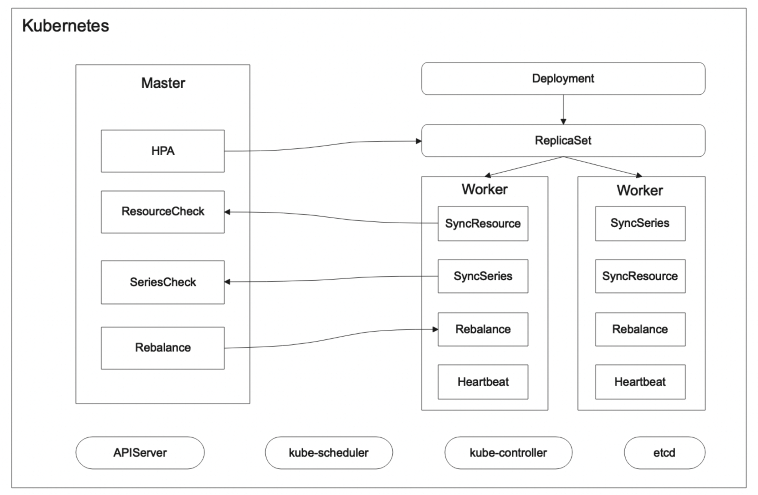
在阿里云 Prometheus 分布式采集探针第二代部署上,Master 与 Worker 拆分为两个 Deployment 部署模式以及 scrape_configs & Targets 订阅模式,HPA 采集扩容机制。其核心模块由原先的 Prometheus 核心模块改为基于 Opentelemetry operator + Target Allocator。
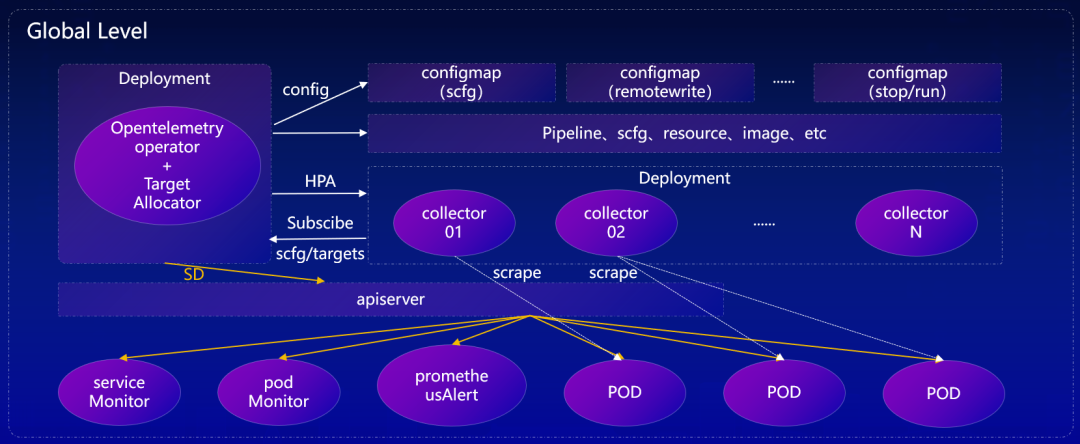
(阿里云 Prometheus 布式采集探针第二代架构图)
在功能模块中, Master 中都包含服务发现的模块和预抓取模块。具体来说,服务发现模块与采集模块的拆分,预抓取机制评估采集副本数量,Targets 调度机制实现采集负载均衡,HPA 机制实现采集副本扩容。
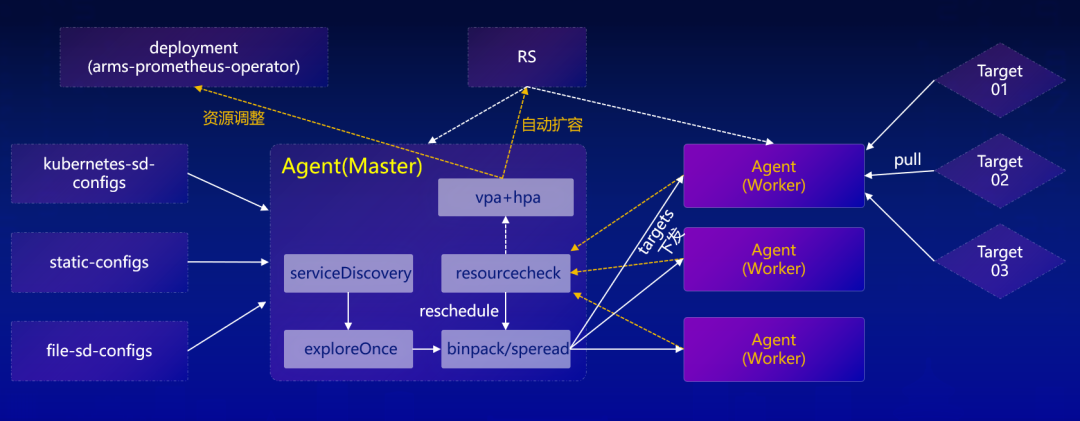
(阿里云 Prometheus 分布式采集探针功能模块)
第二代的探针设计,基于 pentelemetry Operator + TargetAllocator 实现scrape_configs 和 Targets 订阅,依托 K8S 滚动机制实现无损升级能力。
此外,阿里云 Prometheus 自研 Master-Slave 调度,可实现自适应采集负载波动。具体来讲,Master 加载采集配置,进行服务发现,预抓取后依据 Targets 和 Series 计算所需采集副本数,依据阈值切片和调度 Targets。Worker 启动后向 Master 注册并获取唯一 ID 身份标识,通过 TA 向 Master 获取采集配置,再依据采集配置按照Job颗粒度组装 URL 向 Master 获取分配的 Targets,最后启动 Targets 采集。Master 中的 Rebalance 模块依据 Worker 资源消耗和采集负载的同步结果,进行动态 Targets 调度,调度时会计算下次采集时间间隔,做到不掉点动态负载均衡。
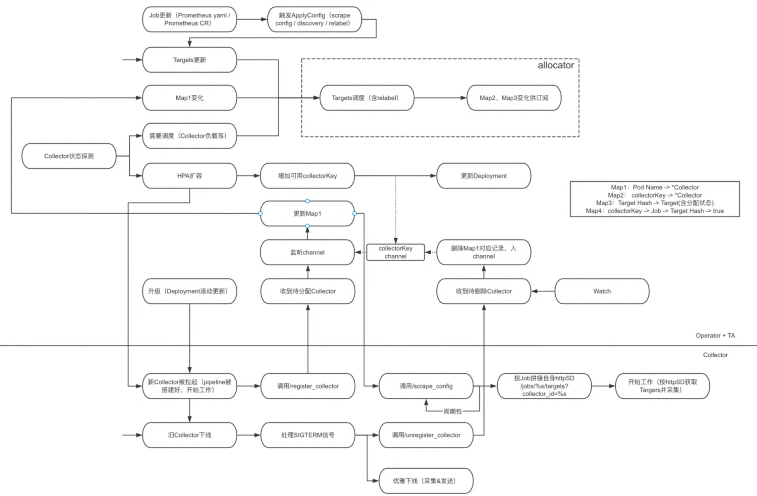
同时,阿里云 Prometheus 自研 HPA 实现采集副本扩容,具体过程如下:Master 与 Worker 间通过 SyncResource 模块进行资源消耗(Cpu&Memory)同步,实时获取 Worker 资源消耗,达到70%时触发 Rebalance 模块进行负载均衡调度;Master 与 Worker 间通过 SyncSeries 模块同步 Worker 实时采集量级,当有单 Target 出现时间线发散或波动时,超过 Worker 预定采集负载后,触发 Rebalance 模块进行负载均衡调度;Master 中的 HPA 模块,依据 SyncResource 和 SyncSeries 同步的结果,经过计算后进行扩容,通过设定 ReplicaSet 来改变采集副本数。
总结来说,阿里云 Prometheus 采用采存拆分架构,打造了轻量化采集探针,可在 K8S 集群做安装。
其轻量化的 Agent 支持分布式的采集,配合其自研的 HPA 和 VPA 的能力,可支持超大规模集群,其负载在上下波动时可自适应,自适应后可以做横向和纵向的扩容,不会出现在集群指标突然发散时形成探针故障。从后端可观测上发现数据有发散,可以做告警再去处理,从而保证监控数据的连续。
阿里云 Prometheus 在存储上采用高可用存储链路设计,支持远端指标投递,可构建统一的存储体系和告警体系。隋吉智表示:“我们是把存储和采集拆分之后,把存储上的链路又增加了 Kafka 缓存,让你的数据即使规模很大也不会延迟很久。然后在查询阶段做优化,让查询变快、变稳定,使得可观测大盘和告警会更高效。”
阿里云 ASI 超大规模集群采集量级和部署上,初始化部署单副本,即 Master,采集方式有全局服务发现 Kubernetes-pods、ServiceMonitor、PodMonitor 三种方式。他表示,三种类型采集配置,服务发现范围均为全集群,使用建议上其实是最不推荐的方式,但是测试性能时可以这么使用。
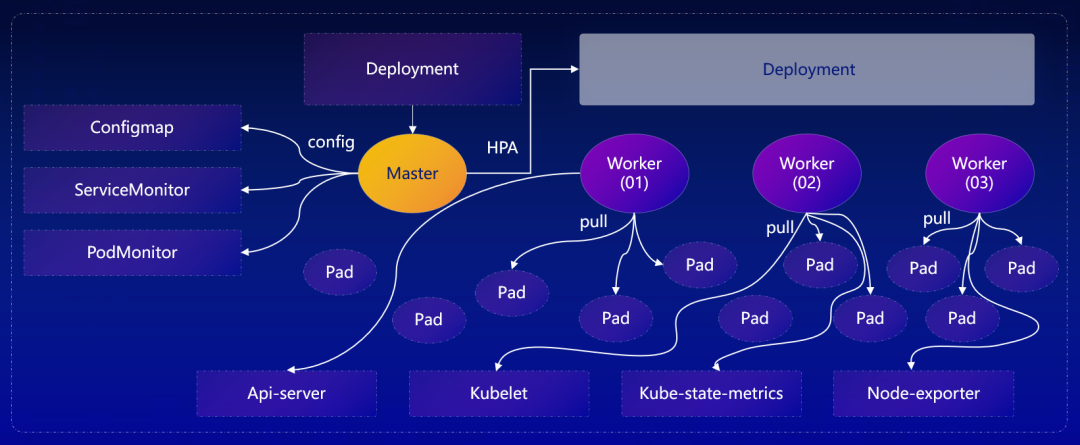
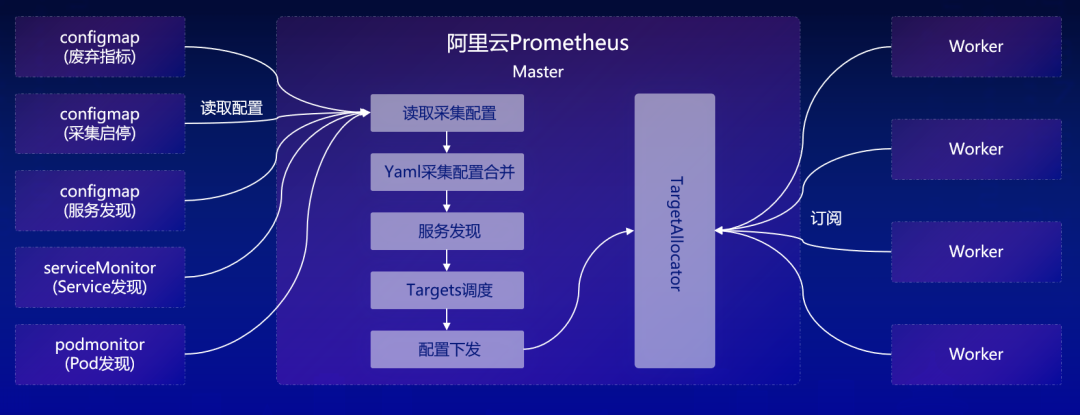
阿里云 ASI 超大规模集群采集配置合并上,Master 中进行采集配置的合并和服务发现,并根据自定义的采集开关启停 Job,Worker 中过滤废弃指标。
他解释了把废弃指标从 Metrics relabel 中提取出来的原因:“我们在实际过程中发现,在 Metrics relabel 做指标废弃的时候,是非常消耗性能的,会让性能变得很差很差。如果用户配了一些很多的正则,那做匹配的时候性能就下降得非常明显。”
最后,隋吉智总结了阿里云 Prometheus 第二代探针在 ASI 超大规模集群场景落地实践的效果:
在 ASI 超大规模集群场景约10w Pods 时,服务发现产生约4.5w Targets,单轮采集约7000万时间线,分布式采集探针 2c2g Limit 资源下实测所需约23个采集副本,实际资源开销约50%。
在ASI 超大规模集群场景 Pods 从10w 至 30w波动变化时,服务发现产生 Targets 由4.5w Targets 至 12w Targets,探针自适应波动并进行 HPA 扩容,分布式采集探针 2c2g Limit 资源下实测所需约50个采集副本,实际资源开销约50%。
单 Master 服务发现设计,有效降低对集群内 APIServer 的压力,同时增加 APIServer List 动作频率限制,一定程度上保证不会因 Master 故障导致 APIServer 压力骤增。
可观测性技术,正在将黑盒问题白盒化。数据存储、LLM应用、对外客户服务提供、企业内部故障排查、由开源版本进一步提升的产品迭代能力等,大厂们在可观测性技术领域上各显神通,为开发者提供技术觉察的慧眼。

















 7744
7744











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









