








核心模组对比


查看 Jetson Nano 技术规格
| Jetson Nano | |||
| AI Performance | 472 GFLOPS | ||
| GPU | 128-core NVIDIA Maxwell™ architecture GPU | ||
| GPU Max Frequency | 921MHz | ||
| CPU | Quad-core ARM® Cortex®-A57 MPCore processor | ||
| CPU Max Frequency | 1.43GHz | ||
| DL Accelerator | - | ||
| DLA Max Frequency | - | ||
| Vision Accelerator | - | ||
| Safety Cluster Engine | - | ||
| Memory | 4GB 64-bit LPDDR4 25.6GB/s | ||
| Storage | 16GB eMMC 5.1 | ||
| Video Encode | 1x 4K30 (H.265) 2x 1080p60 (H.265) | ||
| Video Decode | 1x 4K60 (H.265) 4x 1080p60 (H.265) | ||
| CSI Camera | Up to 4 cameras 12 lanes MIPI CSI-2 D-PHY 1.1 (up to 18 Gbps) | ||
| PCIe* | 1 x4 (PCIe Gen2) | ||
| USB* | 1x USB 3.0 (5 Gbps) 3x USB 2.0 | ||
| Networking* | 1x GbE | ||
| Display | 2 multi-mode DP 1.2/eDP 1.4/HDMI 2.0 1 x2 DSI (1.5Gbps/lane) | ||
| Other I/O | 3x UART, 2x SPI, 2x I2S, 4x I2C, GPIOs | ||
| Power | 5W - 10W | ||
| Mechanical | 69.6mm x 45mm 260-pin SO-DIMM connector | ||
查看 Jetson Orin 技术规格
| Jetson AGX Orin 系列 | Jetson Orin NX 系列 | Jetson Orin Nano 系列 | |||||||
| Jetson AGX Orin 开发者套件 | Jetson AGX Orin 64GB | Jetson AGX Orin 工业版 | Jetson AGX Orin 32GB | Jetson Orin NX 16GB | Jetson Orin NX 8GB | Jetson Orin Nano 开发者套件 | Jetson Orin Nano 8GB | Jetson Orin Nano 4GB | |
| AI 性能 | 275 TOPS | 248 TOPS | 200 TOPS | 100 TOPS | 70 TOPS | 40 TOPS | 20 TOPS | ||
| GPU | 搭载 64 个 Tensor Core 的 2048 核 NVIDIA Ampere 架构 GPU | 搭载 56 个 Tensor Core 的 1792 核 NVIDIA Ampere c GPU | 搭载 32 个 Tensor Core 的 1024 核 NVIDIA Ampere 架构 GPU | 搭载 32 个 Tensor Core 的 1024 核 NVIDIA Ampere 架构 GPU | 搭载 16 个 Tensor Core 的 512 核 NVIDIA Ampere 架构 GPU | ||||
| GPU 最大频率 | 1.3 GHz | 1.2 GHz | 930 MHz | 918 MHz | 765 MHz | 625 MHz | |||
| CPU | 12 核 Arm® Cortex®-A78AE v8.2 64 位 CPU 3MB L2 + 6MB L3 | 8 核 Arm® Cortex®-A78AE v8.2 64 位 CPU 2MB L2 + 4MB L3 | 8 核 Arm® Cortex®-A78AE v8.2 64 位 CPU 2MB L2 + 4MB L3 | 6 核 Arm® Cortex® A78AE v8.2 64 位 CPU 1.5MB L2 + 4MB L3 | 6 核 Arm® Cortex® A78AE v8.2 64 位 CPU 1.5MB L2 + 4MB L3 | ||||
| CPU 最大频率 | 2.2 GHz | 2.0 GHz | 2.2 GHz | 2 GHz | 1.5 GHz | ||||
| DL 加速器 | 2x NVDLA v2 | 1x NVDLA v2 | - | ||||||
| DLA 最大频率 | 1.6 GHz | 1.4 GHz | 614 MHz | - | |||||
| 视觉加速器 | 1x PVA v2 | - | |||||||
| 安全集群引擎 | - | - | - | ||||||
| 显存 | 64GB 256 位 LPDDR5 204.8GB/s | 64GB 256 位 LPDDR5 (+ ECC) 204.8GB/s | 32GB 256 位 LPDDR5 204.8GB/s | 16GB 128 位 LPDDR5 102.4GB/s | 8GB 128 位 LPDDR5 102.4GB/s | 8GB 128 位 LPDDR5 68 GB/s | 4GB 64 位 LPDDR5 34 GB/s | ||
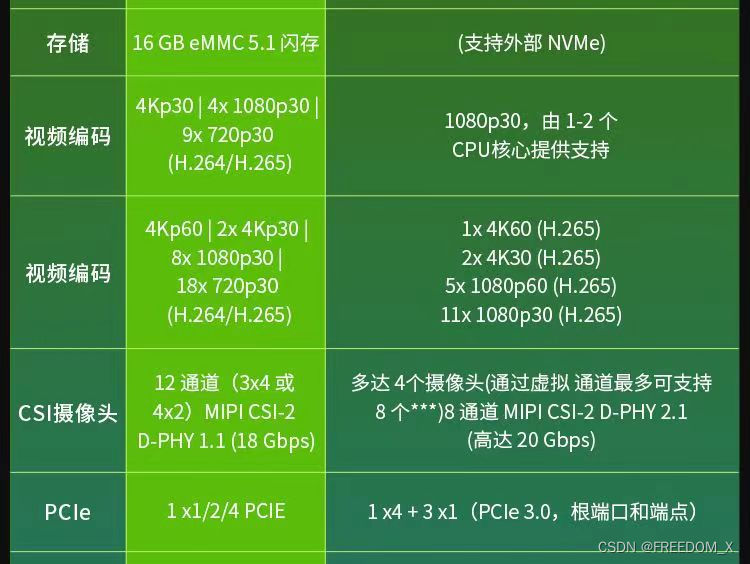
| 存储 | 64GB eMMC 5.1 | - (支持外部 NVMe) | - (配备 SD 卡插槽,且支持通过 M.2 Key M 连接外部 NVMe) | - (支持外部 NVMe) | |||||
| 视频编码 | 2x 4K60 (H.265) 4x 4K30 (H.265) 8x 1080p60 (H.265) 16x 1080p30 (H.265) | 1x 4K60 (H.265) 3x 4K30 (H.265) 7x 1080p60 (H.265) 15x 1080p30 (H.265) | 1x 4K60 (H.265) 3x 4K30 (H.265) 6x 1080p60 (H.265) 12x 1080p30 (H.265) | 1080p30,由 1-2 个 CPU 核心提供支持 | |||||
| 视频解码 | 1x 8K30 (H.265) 3x 4K60 (H.265) 7x 4K30 (H.265) 11x 1080p60 (H.265) 22x 1080p30 (H.265) | 1x 8K30 (H.265) 3x 4K60 (H.265) 7x 4K30 (H.265) 11x 1080p60 (H.265) 23x 1080p30 (H.265) | 1x 8K30 (H.265) 2x 4K60 (H.265) 4x 4K30 (H.265) 9x 1080p60 (H.265) 18x 1080p30 (H.265) | 1x 4K60 (H.265) 2x 4K30 (H.265) 5x 1080p60 (H.265) 11x 1080p30 (H.265) | |||||
| CSI 摄像头 | 16 通道 MIPI CSI-2 连接器 | 多达 6 个摄像头(通过虚拟通道支持 16 个) 16 通道 MIPI CSI-2 D-PHY 2.1(高达 40 Gbps)| C-PHY 2.0(高达 164 Gbps) | 多达 4 个摄像头(通过虚拟通道支持 8 个***) 8 通道 MIPI CSI-2 D-PHY 2.1(高达 20 Gbps) | 2x MIPI CSI-2 22 针摄像头连接器 | 多达 4 个摄像头(通过虚拟通道支持 8 个***) 8 通道 MIPI CSI-2 D-PHY 2.1(高达 20 Gbps) | ||||
| PCIe* | x16 PCIe 插槽,支持 x8 PCIe 4.0 M.2 Key M 插槽,支持 x4 PCIe 4.0 M.2 Key E 插槽,支持 x1 PCIe 4.0 | 高达 2 x8 + 1 x4 + 2 x1 (PCIe 4.0、根端口和端点) | 1 x4 + 3 x1 (PCIe 4.0、根端口和端点) | M.2 Key M 插槽,支持 x4 PCIe 3.0 M.2 Key M 插槽,支持 x2 PCIe 3.0 M.2 Key E 插槽 | 1 x4 + 3 x1 (PCIe 3.0、根端口和端点) | ||||
| USB* | USB Type-C 连接器:2x USB 3.2 2.0 USB Type-A 连接器:2x USB 3.2 2.0、2x USB 3.2 1.0 USB Micro-B 连接器:USB 2.0 | 3x USB 3.2 2.0 (10 Gbps) 4x USB 2.0 | 3x USB 3.2 2.0 (10 Gbps) 3x USB 2.0 | USB Type-A 连接器:4x USB 3.2 2.0 适用于 UFP 的 USB Type-C 连接器 | 3x USB 3.2 2.0 (10 Gbps) 3x USB 2.0 | ||||
| 网络* | RJ45 连接器,至高可支持 10 GbE | 1x GbE 1x 10GbE | 1x GbE | 1xGbE 连接器 | 1x GbE | ||||
| 显示器 | 1x DisplayPort 1.4a (+MST) 连接器 | 1x 8K60 多模 DP 1.4a (+MST)/eDP 1.4a/HDMI 2.1 | 1x 8K30 多模 DP 1.4a (+MST)/eDP 1.4a/HDMI 2.1 | 1x DisplayPort 1.2 (+MST) 连接器 | 1x 4K30 多模 DP 1.2 (+MST)/eDP 1.4/HDMI 1.4** | ||||
| 其他 I/O | 40 针接头(UART、SPI、I2S、I2C、CAN、PWM、DMIC、GPIO) 12 针自动化接头 10 针音频面板接头 10 针 JTAG 接头 4 针风扇接头 2 针 RTC 电池备份连接器 microSD 插槽 直流电源插座 电源、强制恢复和复位按钮 | 4x UART、3x SPI、4x I2S、8x I2C、2x CAN、PWM、DMIC 和 DSPK、GPIO | 3x UART、2x SPI、2x I2S、4x I2C、1x CAN、DMIC 和 DSPK、PWM、GPIO | 40 针扩展接头(UART、SPI、I2S、I2C、GPIO) 12 针按钮接头 4 针风扇接头 microSD 插槽 直流电源插座 | 3x UART、2x SPI、2x I2S、4x I2C、1x CAN、DMIC 和 DSPK、PWM、GPIO | ||||
| 功耗 | 15 瓦 - 60 瓦 | 15 瓦 - 75 瓦 | 15 瓦 - 40 瓦 | 10 瓦 – 25 瓦 | 10 瓦 - 20 瓦 | 7 瓦 - 15 瓦 | 7 瓦 - 10 瓦 | ||
| 规格尺寸 | 110 毫米 x 110 毫米 x 71.65 毫米 (高度包括支架、载板、模组和散热解决方案) | 100 毫米 x 87 毫米 699 针 Molex Mirror Mezz 连接器 集成导热板 | 69.6 毫米 x 45 毫米 260 针 SO-DIMM 连接器 | 100 毫米 x 79 毫米 x 21 毫米 (高度包括支架、载板、模组和散热解决方案) | 69.6 毫米 x 45 毫米 260 针 SO-DIMM 连接器 | ||||
† Jetson Nano 模组和 Jetson Xavier NX 模组是 Jetson Nano 开发者套件的一部分,Jetson Xavier NX 开发者套件配备插槽,支持使用 microSD 卡(而非 eMMC)作为系统存储设备。
* USB 3.2、MGBE 和 PCIe 共享 UPHY 通道。请参阅产品设计指南,了解受支持的 UPHY 配置。
** 有关 DP 1.4a 和 HDMI 2.1 的其他兼容情况的详细信息,请参阅 Jetson Orin Nano 系列产品手册
*** Jetson Orin NX 和 Jetson Orin Nano 的虚拟通道可能会发生变化
如要查看支持功能列表,请参阅新版 NVIDIA Jetson Linux 开发者指南的“Software Features”(软件功能)部分。
参考资料
Jetson Nano Brings the Power of Modern AI to Edge Devices | NVIDIA


















 1055
1055

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









