







之前一直看到说基于goal的分层强化学习的难点在于如何定义goal。在之前学习的goal-conditioned框架中,目标空间就是状态空间,目标是达到某一特定的状态。又看了几篇基于goal的分层强化学习,这篇博客用来记录每篇论文,并明确goal指代的是什么。
H-DQN: Hierarchical Deep Reinforcement Learning: Integrating Temporal Abstraction
这篇论文是我目前看过的分层强化学习中唯一一个人为定义目标的,这个目标是针对特定场景(Montezuma's Revenge游戏)人为定义。游戏中,需要得到某些特定的物品和到达某些特定的位置,在得到物品和到达位置之前,智能体都无法获得奖励,这就是稀疏奖励问题。所以选取特定的物品作为目标:门、梯子、钥匙等等。

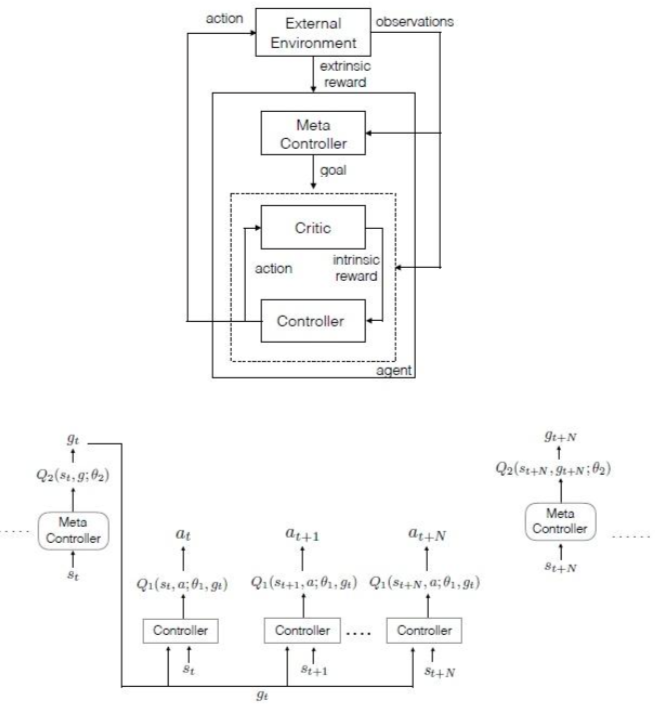
在H-DQN中,上层控制器以较长的时间跨度根据上层策略选择一个goal,下层控制器以较短的时间跨度选择action,上层策略和下层策略都以DQN算法为基础,其中上层策略根据外部奖励进行更新,下层策略则根据上层控制器传递下来的内部奖励进行更新,这里内部奖励的制定方式是,当上层控制器设定的目标完成时,内部奖励为一个正数,否则为0。
HIRO: Data-Efficient Hierarchical Reinforcement Learning
分析博文: 【分层强化学习】HIRO:一种off-policy的分层强化学习算法 - 知乎 (zhihu.com)
目标定义在状态空间,下层控制器的策略需要尽可能让状态朝着目标所表示的方向转移。
本文的创新点在于针对off-policy的分层强化学习中所存在的非平稳问题(上层控制器的状态转移概率取决于下层策略,在off-policy算法中,当上层策略进行更新时,由于下层策略不断更新已经发生了变化,此时回放池中的样本已经不能准确反映当前上层控制器所处的环境,给训练造成了很大的困难)提出解决方法。
对经验回放池中的样本进行修正,将原本设定的目标替换成一个新的目标,该目标能够最大化该样本对应轨迹的出现概率,概率的计算公式为![]()
HAC: Learning Multi-Level Hierachies with Hindsight
分析博文: 【分层强化学习】HAC:一种多层级的分层强化学习算法 - 知乎 (zhihu.com)
目标定义在状态空间,目标就是达到某一特定状态,实现时奖励为1,否则为0。
本文同样是解决分层强化学习的非平衡问题,同时还将HER算法应用到分层框架,解决稀疏奖励问题。本文提出了一个多层级的分层结构,除了最后一层外,每一层均用于输出下一层的目标,这里的目标即为状态空间中较好的状态,因此每个层级的目标就是实现上一层所设定的较好的状态。
本文的主要工作是设计了三种不同的transition样本分别用于解决策略更新中存在的不同问题。
















 237
237











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









