









论文: Learning Multi-Level Hierarchies with Hindsight
代码github地址:https://github.com/nikhilbarhate99/Hierarchical-Actor-Critic-HAC-PyTorch
HAC理论部分:https://blog.csdn.net/qq_47997583/article/details/126013369
算法伪码:
简而言之就是在原理DDPG算法的基础上,加入分层结构,为了提高不同层之间非平稳性不能并行训练的问题,在分层结构上加入hindsight的思路修改扩充经验回放池中的数据进行训练。

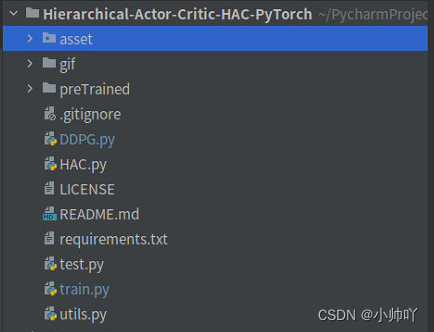
文件结构如上图所示,其中asset文件夹中为环境相关代码,gif文件夹下为效果图,preTrained文件夹下保存训练出的参数文件,DDPG.py文件中是单层加入goal的DDPG算法实现,HAC.py为核心的HAC算法的实现,train.py中是整个项目训练的主文件,utils.py中是经验回放池的实现代码,test.py中是测试的代码。
接下来通过debug代码走一遍训练的过程了解HAC的实现过程
首先是一些训练的参数设定:
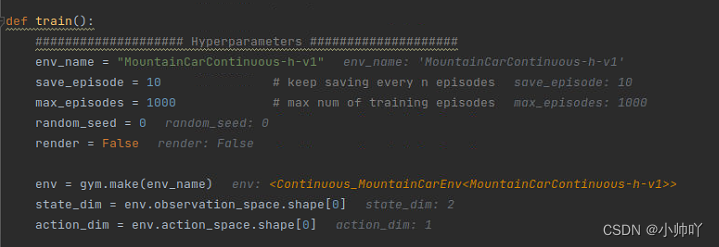
下面定义了action的bounds和offset、state的bounds和offset、action和goal的探索噪声、目标状态、阈值。在本项目中设定的goal为position是0.48±0.01,velocity是0.04±0.02。
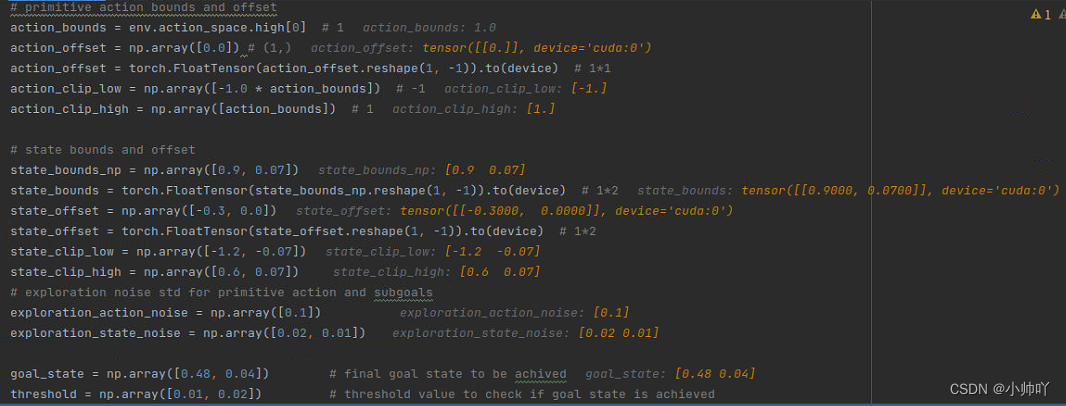
关于bounds和offset的设置,作者在issue中进行了解释:https://github.com/nikhilbarhate99/Hierarchical-Actor-Critic-HAC-PyTorch/issues/2
本项目中环境为MountainCarContinuous-h-v1,其中
状态空间为连续的二维信息,
self.observation_space = spaces.Box(low=self.low_state, high=self.high_state, dtype=np.float32)
[position, velocity] between min value = [-1.2, -0.07] and max value = [0.6, 0.07],
动作空间为连续的一维信息,
self.action_space = spaces.Box(low=self.min_action, high=self.max_action,shape=(1,), dtype=np.float32)
the action space is between [-1, 1]
我的理解是在本项目应用的环境中action和state空间不都是[-1,1]之间,神经网络最后一层是Tanh激活函数会将其归一化到[-1,1]之间,因此需要进行一些修改。
作者使用以下公式实现
action = ( network output (Tanh) * bounds ) + offset
对于action space:
the action space is between (-1, 1), and as the mean value [ (1 + (-1)) / 2 ] is 0 we do not require an offset, and the value of bound = 1, since our network only outputs between (-1, 1), so,
action = ( network output (Tanh) * bounds ) + offset
i.e action = (network output * 1) + 0
对于state space:
here the position variable (-1.2, 0.6) is NOT normalised to (-1,1) and its mean value
[ (0.6 + (-1.2)) / 2 ] is 0.3
action = ( network output (Tanh) * bounds ) + offset
for position variable:
action = (network output * 0.9) + 0.3
this bounds the value of the action to (-1.2, 0.6)
similarly, the velocity variable (-0.07, 0.07) is NOT normalised to (-1,1) and its mean value [ (0.6 + (-1.2)) / 2 ] is 0, so,for velocity variable:
action = (network output * 0.07) + 0
this bounds the value of the action to (-0.07, 0.07)
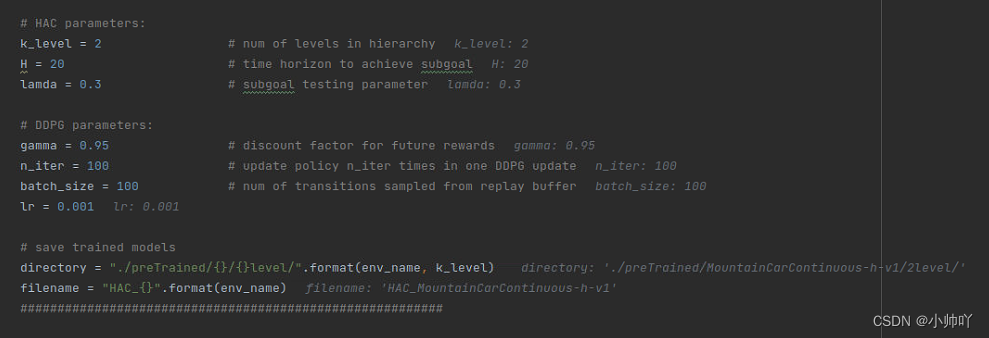
接下来HAC算法、DDPG算法以及模型参数文件保存路径的设定
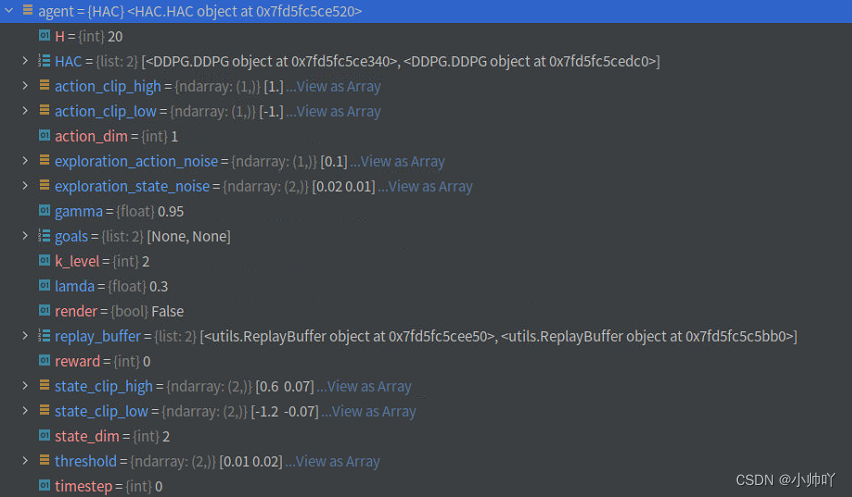
接下来创建HAC agent并设置相关参数,前面定义了这是一个两层的网络,因此HAC类下的HAC属性为一个包含两个DDPG的列表。

class HAC:
def __init__(self, k_level, H, state_dim, action_dim, render, threshold,
action_bounds, action_offset, state_bounds, state_offset, lr):
# adding lowest level
self.HAC = [DDPG(state_dim, action_dim, action_bounds, action_offset, lr, H)]
self.replay_buffer = [ReplayBuffer()]
# adding remaining levels
for _ in range(k_level-1):
self.HAC.append(DDPG(state_dim, state_dim, state_bounds, state_offset, lr, H))
self.replay_buffer.append(ReplayBuffer())
# set some parameters
self.k_level = k_level
self.H = H
self.action_dim = action_dim
self.state_dim = state_dim
self.threshold = threshold
self.render = render
# logging parameters
self.goals = [None]*self.k_level
self.reward = 0
self.timestep = 0
def set_parameters(self, lamda, gamma, action_clip_low, action_clip_high,
state_clip_low, state_clip_high, exploration_action_noise, exploration_state_noise):
self.lamda = lamda
self.gamma = gamma
self.action_clip_low = action_clip_low
self.action_clip_high = action_clip_high
self.state_clip_low = state_clip_low
self.state_clip_high = state_clip_high
self.exploration_action_noise = exploration_action_noise
self.exploration_state_noise = exploration_state_noise
接下来是整个训练过程
# training procedure
for i_episode in range(1, max_episodes+1):
agent.reward = 0
agent.timestep = 0
state = env.reset()
# collecting experience in environment
last_state, done = agent.run_HAC(env, k_level-1, state, goal_state, False)
if agent.check_goal(last_state, goal_state, threshold):
print("################ Solved! ################ ")
name = filename + '_solved'
agent.save(directory, name)
# update all levels
agent.update(n_iter, batch_size)
# logging updates:
log_f.write('{},{}\n'.format(i_episode, agent.reward))
log_f.flush()
if i_episode % save_episode == 0:
agent.save(directory, filename)
print("Episode: {}\t Reward: {}".format(i_episode, agent.reward))
在上面训练代码中有三行比较核心的代码,接下来逐一分析
1.跑一层HAC
last_state, done = agent.run_HAC(env, k_level-1, state, goal_state, False)
def run_HAC(self, env, i_level, state, goal, is_subgoal_test):
next_state = None
done = None
goal_transitions = []
# logging updates
self.goals[i_level] = goal
# H attempts
for _ in range(self.H):
# if this is a subgoal test, then next/lower level goal has to be a subgoal test
is_next_subgoal_test = is_subgoal_test
action = self.HAC[i_level].select_action(state, goal)
# <================ high level policy ================>
if i_level > 0:
# add noise or take random action if not subgoal testing
if not is_subgoal_test:
if np.random.random_sample() > 0.2: # p=0.8 exploratopm
action = action + np.random.normal(0, self.exploration_state_noise)
action = action.clip(self.state_clip_low, self.state_clip_high)
else: # p=0.2 random sample
action = np.random.uniform(self.state_clip_low, self.state_clip_high)
# Determine whether to test subgoal (action)
if np.random.random_sample() < self.lamda:
is_next_subgoal_test = True
# Pass subgoal to lower level
next_state, done = self.run_HAC(env, i_level-1, state, action, is_next_subgoal_test)
# if subgoal was tested but not achieved, add subgoal testing transition
if is_next_subgoal_test and not self.check_goal(action, next_state, self.threshold):
self.replay_buffer[i_level].add((state, action, -self.H, next_state, goal, 0.0, float(done)))
# for hindsight action transition
action = next_state
# <================ low level policy ================>
else:
# add noise or take random action if not subgoal testing
if not is_subgoal_test:
if np.random.random_sample() > 0.2:
action = action + np.random.normal(0, self.exploration_action_noise)
action = action.clip(self.action_clip_low, self.action_clip_high)
else:
action = np.random.uniform(self.action_clip_low, self.action_clip_high)
# take primitive action
next_state, rew, done, _ = env.step(action)
if self.render:
# env.render() ##########
if self.k_level == 2:
env.unwrapped.render_goal(self.goals[0], self.goals[1])
elif self.k_level == 3:
env.unwrapped.render_goal_2(self.goals[0], self.goals[1], self.goals[2])
# this is for logging
self.reward += rew
self.timestep +=1
# <================ finish one step/transition ================>
# check if goal is achieved
goal_achieved = self.check_goal(next_state, goal, self.threshold)
# hindsight action transition
if goal_achieved:
self.replay_buffer[i_level].add((state, action, 0.0, next_state, goal, 0.0, float(done)))
else:
self.replay_buffer[i_level].add((state, action, -1.0, next_state, goal, self.gamma, float(done)))
# copy for goal transition
goal_transitions.append([state, action, -1.0, next_state, None, self.gamma, float(done)])
state = next_state
if done or goal_achieved:
break
# <================ finish H attempts ================>
# hindsight goal transition
# last transition reward and discount is 0
goal_transitions[-1][2] = 0.0
goal_transitions[-1][5] = 0.0
for transition in goal_transitions:
# last state is goal for all transitions
transition[4] = next_state
self.replay_buffer[i_level].add(tuple(transition))
return next_state, done
2.检查goal是否实现
agent.check_goal(last_state, goal_state, threshold)
def check_goal(self, state, goal, threshold):
for i in range(self.state_dim):
if abs(state[i]-goal[i]) > threshold[i]:
return False
return True
3.更新agent
agent.update(n_iter, batch_size)
HAC.py
def update(self, n_iter, batch_size):
for i in range(self.k_level):
self.HAC[i].update(self.replay_buffer[i], n_iter, batch_size)
DDPG.py
def update(self, buffer, n_iter, batch_size):
for i in range(n_iter):
# Sample a batch of transitions from replay buffer:
state, action, reward, next_state, goal, gamma, done = buffer.sample(batch_size)
# convert np arrays into tensors
state = torch.FloatTensor(state).to(device)
action = torch.FloatTensor(action).to(device)
reward = torch.FloatTensor(reward).reshape((batch_size,1)).to(device)
next_state = torch.FloatTensor(next_state).to(device)
goal = torch.FloatTensor(goal).to(device)
gamma = torch.FloatTensor(gamma).reshape((batch_size,1)).to(device)
done = torch.FloatTensor(done).reshape((batch_size,1)).to(device)
# select next action
next_action = self.actor(next_state, goal).detach()
# Compute target Q-value:
target_Q = self.critic(next_state, next_action, goal).detach()
target_Q = reward + ((1-done) * gamma * target_Q)
# Optimize Critic:
critic_loss = self.mseLoss(self.critic(state, action, goal), target_Q)
self.critic_optimizer.zero_grad()
critic_loss.backward()
self.critic_optimizer.step()
# Compute actor loss:
actor_loss = -self.critic(state, self.actor(state, goal), goal).mean()
# Optimize the actor
self.actor_optimizer.zero_grad()
actor_loss.backward()
self.actor_optimizer.step()
未完待续

















 1328
1328

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









