







论文名称:Learning Multi-Level Hierarchies with Hindsight
论文作者:Andrew Levy, George Konidaris, Robert Platt, Kate Saenko
发表自:ICLR 2019
当前谷歌学术引用量:134
文章链接:https://arxiv.org/abs/1712.00948
与HIRO一样,本文解决的同样是分层强化学习中不同层级策略学习所存在的non-stationary(非平稳问题),但是用了完全不同思想的方法。分层强化学习通过将任务分解成多个子任务,样本利用率更高。然而,在分层结构中,上层的转移函数取决于下层的策略,当所有层级的策略同时进行训练时,下层策略不断更新,这就导致了上层的转移函数会随之不断变化,在这样的非平稳环境中,智能体很难学习到最优策略,这就是分层强化学习所面临的非平稳(non-stationary)问题。
为了有效解决这个non-stationary问题,HIRO使用了off-policy correction的方式,即重新提出子目标,使其能够适应不同时刻的底层策略。这篇文章则使用了hindsight的方法。加入了一些hindsight transition。hindsight就是事后的意思。文章假设一旦所有下层策略收敛到最优或者次优的时候,这时候同时学习多层策略就可以做到。
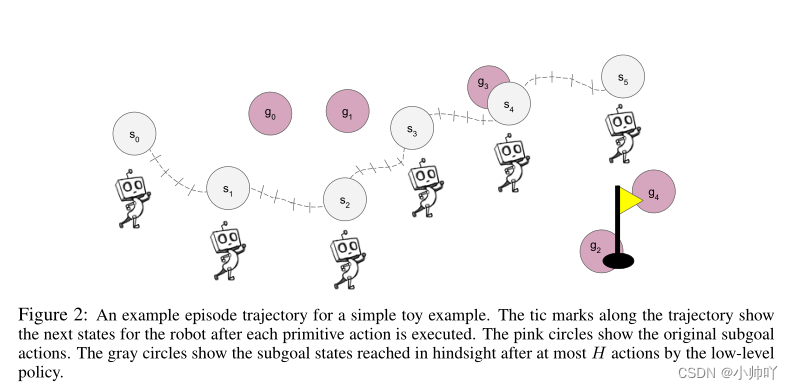
文章中主要提出Hindsight Action Transitions、Hindsight Goal Transitions、Subgoal Testing Transitions实现原始transition的修改和扩展来解决非平稳性问题。
已经总结的比较好博客:
知乎XuanAxuan:https://www.zhihu.com/question/520764541/answer/2439785957
知乎赵英男:
https://zhuanlan.zhihu.com/p/91055669
总结:
1.关于hindsight action transitions其实就是将transition中的action(也就是下一层的goal)修改为实际到达的state,通过这样的方式实现了假定底层策略为最优或者次优策略的目的(因为在这种修改下你的trajectory是按照提出的goal走的)。
2.关于Hindsight Goal Transitions是将 Hindsight Experience Replay 扩展到了分层结构中,保证了每一层级均能在一段动作之后获得一个稀疏奖励。简单来说,Hindsight goal transitions 就是在每隔一段transitions序列之后,在这一些transitions中选择一个所达到的 next state作为当前层级的goals,这样就能保证一定会有一个transitions的reward是有效的。

3.关于Subgoal testing transitions,尽管 hindsight action transitions 与 hindsight goal transitions 能够让智能体在稀疏奖励下并行学习各级策略,但hindsight action的定义限制了第 i 层的hindsight action只能是第 i−1层在 H个action以内能够达到的状态,这就使得一个层级只能学习到当前状态附近的subgoal action的Q值,而忽略需要超过 H 个动作才能达到的subgoal actions,进而会导致Q值的估计出现偏差。Subgoal testing transitions的作用与hindsight action transitions的作用截然相反:hindsight action transitions在假设下层策略最优的情况下,学习当前层级策略;而 subgoal testing transitions 则是用于让当前策略理解在当前的低层策略下,一个subgoal状态是否能够被实现。

加入了subgoal testing transition,critic function不会忽略那些不可达的子目标的值函数,同时每个子目标层也能够同时学习,Q值还是会更倾向那些底层目标可达到的子目标。
疑问:
1.在hindsight action transitions中对于为什么该方法对于智能体的顶层有效,在赵的博客中这样描述:尽管目前这些transtition的奖励仍然为-1,但是对于智能体的顶层还是有用的。通过这些transitions,高层策略能够学习如何提出自己的子目标,因为time scale是相同的。同时这些transition能够不考虑non-stationary的问题。
在Xuan的博客中这样描述:尽管这些hindsight action均不能获得稀疏奖励,它们对智能体的上层训练依然是有帮助的,因为它们能够帮助高层策略找到 个原始动作所能达到的目标。并且,这些transitions都能够克服下层策略变化或者探索产生的影响。
算法伪码:
本算法总结来说,其实就是产生三种不同的transitions放入经验回放池里用于训练,因此算法的流程实际上就是产生不同样本的流程。

仿真结果:
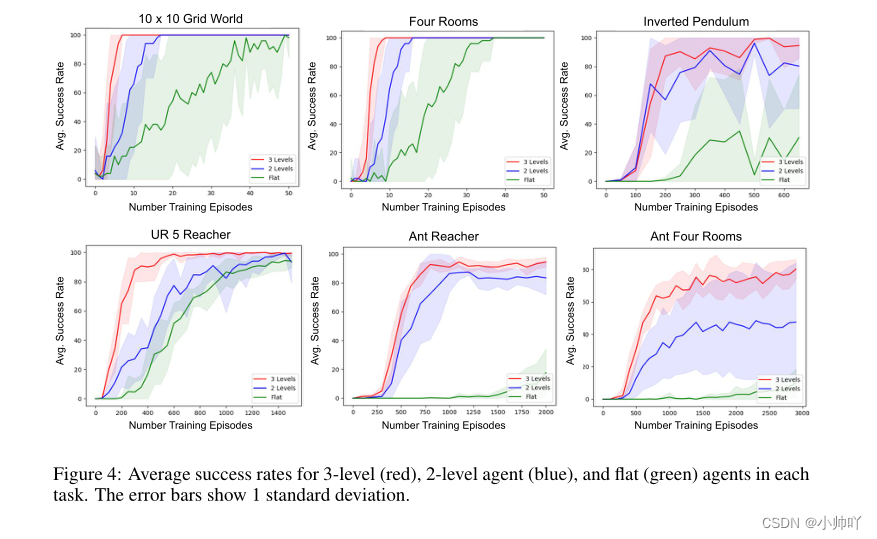
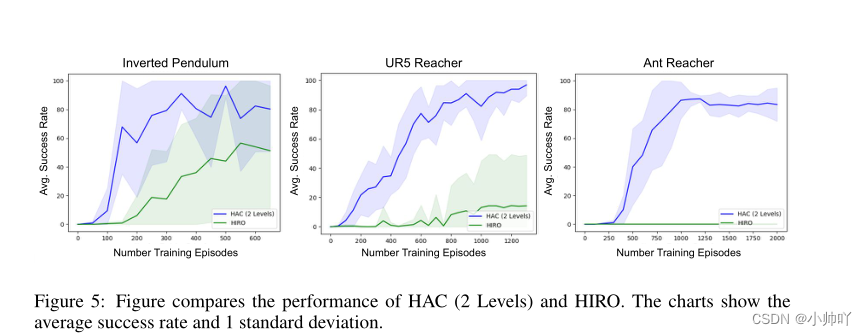
1.分层比不分层效果好
2.分三层比分两层效果好
3.HAC比HIRO效果好
HAC实现代码(pytorch版本):https://github.com/nikhilbarhate99/Hierarchical-Actor-Critic-HAC-PyTorch

















 1628
1628

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









