









径向基函数网络(Radial Basis Function Network):就是将基假设函数进行线性聚合。
径向基函数网络假设函数(RBF Network Hypothesis)
先回顾一下高斯支持向量机(Gaussian SVM):
g s v m ( x ) = sign ( ∑ S V α n y n exp ( − γ ∥ x − x n ∥ 2 ) + b ) g _ { \mathrm { svm } } ( \mathbf { x } ) = \operatorname { sign } \left( \sum _ { \mathrm { SV } } \alpha _ { n } y _ { n } \exp \left( - \gamma \left\| \mathbf { x } - \mathbf { x } _ { n } \right\| ^ { 2 } \right) + b \right) gsvm(x)=sign(SV∑αnynexp(−γ∥x−xn∥2)+b)
其实际上是找出系数 α n \alpha_n αn 将以 x n \mathbf { x } _ { n } xn 为中心的高斯函数进行线性结合。
Gaussian kernel 又叫 Radial Basis Function (RBF) kernel,其中 Radial 指的是这里之关系 x \mathbf { x } x 与中心 x n \mathbf { x } _ { n } xn 之间的距离(类似于一种放射线长度求解)。
那么写出高斯支持向量机中的径向基假设函数:
g n ( x ) = y n exp ( − γ ∥ x − x n ∥ 2 ) g _ { n } ( \mathbf { x } ) = y _ { n } \exp \left( - \gamma \left\| \mathbf { x } - \mathbf { x } _ { n } \right\| ^ { 2 } \right) gn(x)=ynexp(−γ∥x−xn∥2)
那么高斯支持向量机可以改写为:
g s v m ( x ) = sign ( ∑ S V α n g n ( x ) + b ) g _ { \mathrm { svm} } ( \mathbf { x} ) = \operatorname { sign } \left( \sum _ { \mathrm { SV } } \alpha _ { n } g _ { n } ( \mathbf { x } ) + b \right) gsvm(x)=sign(SV∑αngn(x)+b)
可以看出被选择的径向基假设函数的线性结合(linear aggregation of selected radial hypotheses)。
RBF Network 的网络结构示意图如下:
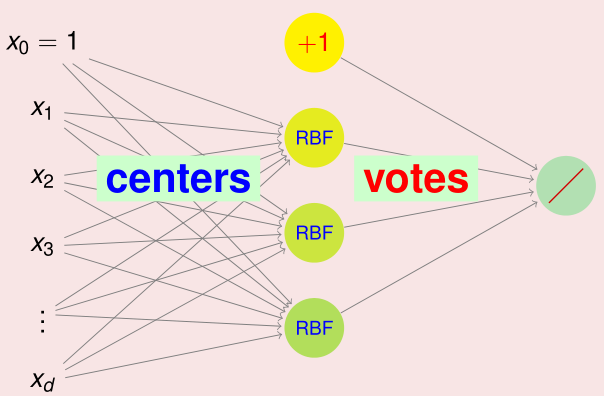
实际上 RBFNet 是 NNet 的一个分支,可见输出层虽然使用的是投票,但是这也是一种线性组合所以与神经网络是一样的。但是隐含层是不同的,在神经网络中使用的是内积加 tanh 输出,而在 RBFNet 中使用的是距离计算加高斯函数。
那么可以写出 RBFNet 的输出假设函数:
h ( x ) = Output ( ∑ m = 1 M β m RBF ( x , μ m ) + b ) h ( \mathbf { x } ) = \text { Output } \left( \sum _ { m = 1 } ^ { M } \beta _ { m } \operatorname { RBF } \left( \mathbf { x } , \mu _ { m } \right) + b \right) h(x)= Output (m=1∑MβmRBF(x,μm)+b)
其中 μ m \mu _ { m } μm 是中心点, β m \beta _ { m } βm 是投票系数。
对比与高斯支持向量机:
- RBF(径向基函数)选择的是高斯函数。
- Output(输出)选择 sign 做为二分类输出。
- M 则是支持向量的个数(#SV)。
- μ m \mu _ { m } μm 则是支持向量 x m \mathbf{x}_m xm。
- β m \beta _ { m } βm 则是通过 SVM Dual 问题求解 α m \alpha_m αm 与 y m y_m ym 的乘积。
不失普遍性的来说:如果要学习径向基函数网络的话,需要选择四个部分:径向基函数 RBF ,输出层假设函数 Output ,中心点的求取 μ m \mu _ { m } μm ,投票的系数 β m \beta _ { m } βm。
实际上核技巧实际上就是根据在 Z \mathcal Z Z 空间上的内积求取相似性,比如多项式核:
Poly ( x , x ′ ) = ( 1 + x T x ′ ) 2 \operatorname { Poly } \left( \mathbf { x } , \mathbf { x } ^ { \prime } \right) = \left( 1 + \mathbf { x } ^ { T } \mathbf { x } ^ { \prime } \right) ^ { 2 } Poly(x,x′)=(1+xTx′)2
而RBF则是直接通过在 X \mathcal X X 空间上的距离求取相似性,一般认为距离越近相似性越大,也就是说距离与相似性单调相关。比如下面这个截断相似性函数:
Truncated ( x , x ′ ) = [ ∥ x − x ′ ∥ ≤ 1 ] ( 1 − ∥ x − x ′ ∥ ) 2 \text { Truncated } \left( \mathbf { x } , \mathbf { x } ^ { \prime } \right) = \left[ \left\| \mathbf { x } - \mathbf { x } ^ { \prime } \right\| \leq 1 \right] \left( 1 - \left\| \mathbf { x } - \mathbf { x } ^ { \prime } \right\| \right) ^ { 2 } Truncated (x,x′)=[∥x−x′∥≤1](1−∥x−x′∥)2
而高斯函数则处于他们的交集。
Gaussian ( x , x ′ ) = exp ( − γ ∥ x − x ′ ∥ 2 ) \text { Gaussian } \left( \mathbf { x } , \mathbf { x } ^ { \prime } \right) = \exp \left( - \gamma \left\| \mathbf { x } - \mathbf { x } ^ { \prime } \right\| ^ { 2 } \right) Gaussian (x,x′)=exp(−γ∥x−x′∥2)
相似性是很好的一种特征转换方法。在RBF中则是将中心距离相似性作为特征转换的。其他的相似性函数比如神经元函数或者DNA序列相似性函数:
Neuron ( x , x ′ ) = tanh ( γ x T x ′ + 1 ) DNASim ( x , x ′ ) = EditDistance ( x , x ′ ) \begin{array} { c } \text { Neuron } \left( \mathbf { x } , \mathbf { x } ^ { \prime } \right) = \tanh \left( \gamma \mathbf { x } ^ { T } \mathbf { x } ^ { \prime } + 1 \right) \\ \text { DNASim } \left( \mathbf { x } , \mathbf { x } ^ { \prime } \right) = \text { EditDistance } \left( \mathbf { x } , \mathbf { x } ^ { \prime } \right) \end{array} Neuron (x,x′)=tanh(γxTx′+1) DNASim (x,x′)= EditDistance (x,x′)
RBF网络的训练/学习(RBF Network Learning)
完全RBF网络(Full RBF Network)
如果不考虑 bais ,那么可以写为:
h ( x ) = Output ( ∑ m = 1 M β m RBF ( x , μ m ) ) h ( \mathbf { x } ) = \operatorname { Output } \left( \sum _ { m = 1 } ^ { M } \beta _ { m } \operatorname { RBF } \left( \mathbf { x } , \boldsymbol { \mu } _ { m } \right) \right) h(x)=Output(m=1∑MβmRBF(x,μm))
如果令 M = N M = N M=N 并且每一个 μ m = x m \mu _ { m } = \mathbf { x } _ { m } μm=xm 那么这个RBF网络便是完全RBF网络(full RBF Network)。这么做的物理意义是 x m \mathbf { x } _ { m } xm 将通过系数 β m \beta_ { m } βm 来影响每一个与之相似的 x \mathbf x x。
那么举例来说,如果使用一个 uniform influence 即 β m = 1 ⋅ y m \beta _ { m } = 1 \cdot y _ { m } βm=1⋅ym,也就是说大家票数一致。
g unitorm ( x ) = sign ( ∑ m = 1 N y m exp ( − γ ∥ x − x m ∥ 2 ) ) g _ { \text {unitorm } } ( \mathbf { x } ) = \operatorname { sign } \left( \sum _ { m = 1 } ^ { N } y _ { \operatorname { m} } \exp \left( - \gamma \left\| \mathbf { x } - \mathbf { x } _ { m } \right\| ^ { 2 } \right) \right) gunitorm (x)=sign(m=1∑Nymexp(−γ∥x−xm∥2))
所以说完全RBF网络是一种偷懒的做法,省去了中心向量 μ m \mu _ m μm 的求取。
最邻近算法(Nearest Neighbor)
由于高斯函数衰减很快,那么会导致离中心最近的值会获得很大的权重,支配(dominates)投票过程,也就是说具有 “专断权”。所以这个过程更类似于选择一个最大值(最近向量),而不是聚合过程。即:
g nbor ( x ) = y m such that x closest to x m g _ { \text {nbor } } ( \mathbf { x } ) = y _ { m } \text { such that } \mathbf { x } \text { closest to } \mathbf { x } _ { m } gnbor (x)=ym such that x closest to xm
所以叫做最邻近模型(nearest neighbor model)。
常用的是 K 邻近模型,根矩 Top k 最邻近的样本进行均值投票(uniformly aggregate k neighbor),虽然很懒(lazy)但是很直观。
无正则化用于插值(Interpolation)
那么如果用于 Regression,那么以平方误差作为误差测量函数,最后的假设函数可以写为:
h ( x ) = ( ∑ m = 1 N β m RBF ( x , x m ) ) h(\mathbf x) = \left( \sum _ { m = 1 } ^ { N } \beta _ { m } \operatorname { RBF } \left( \mathbf { x } , \mathbf { x } _ { m } \right) \right) h(x)=(m=1∑NβmRBF(x,xm))
可以看出这就是在通过 RBF 映射到的空间上训练线性回归模型
那映射后的数据表示为:
z n = [ RBF ( x n , x 1 ) , RBF ( x n , x 2 ) , … , RBF ( x n , x N ) ] \mathbf { z } _ { n } = \left[ \operatorname { RBF } \left( \mathbf { x } _ { n } , \mathbf { x } _ { 1 } \right) , \operatorname { RBF } \left( \mathbf { x } _ { n } , \mathbf { x } _ { 2 } \right) , \ldots , \operatorname { RBF } \left( \mathbf { x } _ { n } , \mathbf { x } _ { N } \right) \right] zn=[RBF(xn,x1),RBF(xn,x2),…,RBF(xn,xN)]
矩阵 Z \mathrm { Z } Z 由 n n n 个 z n \mathbf { z } _ { n } zn 构成,所以矩阵 Z \mathrm { Z } Z 为 N (example) × N (centers) N\text{(example)} \times N\text{(centers)} N(example)×N(centers) 的对称方阵(symmetric square matrix),根据线性回归可以写出 β \beta β 的最优解:
β = ( Z T Z ) − 1 Z T y , if Z T Z invertible \beta = \left( \mathrm { Z } ^ { T } \mathrm { Z } \right) ^ { - 1 } \mathrm { Z } ^ { T } \mathbf { y } , \text { if } \mathrm { Z } ^ { T } \mathrm { Z } \text { invertible } β=(ZTZ)−1ZTy, if ZTZ invertible
那么如果全部的 x n \mathbf { x } _ { n } xn 的都是不同的,那么 Z \mathrm { Z } Z (with Gaussian RBF)便是可逆的(invertible)。
又因为 Z \mathrm { Z } Z 是对称方阵,也就是说 Z T = Z \mathrm { Z }^T = \mathrm { Z } ZT=Z。那么可以化简为:
β = ( Z Z ) − 1 Z y = Z − 1 y \beta = \left( \mathrm { Z } \mathrm { Z } \right) ^ { - 1 } \mathrm { Z } \mathbf { y } = \mathrm { Z } ^ { - 1 } \mathbf { y } β=(ZZ)−1Zy=Z−1y
正则化(Regularization)
那么 x 1 \mathrm { x } _ { 1 } x1 的 RBF的网络输出为:
g R B F ( x 1 ) = β T z 1 = y T Z − 1 ( first column of Z ) = y T [ 1 0 … 0 ] T = y 1 g _ { \mathrm { RBF } } \left( \mathrm { x } _ { 1 } \right) = \boldsymbol { \beta } ^ { T } \mathrm { z } _ { 1 } = \mathbf { y } ^ { T } \mathrm { Z } ^ { - 1 } ( \text {first column of } \mathrm { Z } ) = \mathbf { y } ^ { T } \left[ \begin{array} { l l l l } 1 & 0 & \ldots & 0 \end{array} \right] ^ { T } = y _ { 1 } gRBF(x1)=βTz1=yTZ−1(first column of Z)=yT[10…0]T=y1
也就是说 g R B F ( x n ) = y n , i.e. E i n ( g R B F ) = 0 g _ { \mathrm { RBF } } \left( \mathrm { x } _ { n } \right) = y _ { n } , \text { i.e. } E _ { \mathrm { in } } \left( g _ { \mathrm { RBF } } \right) = 0 gRBF(xn)=yn, i.e. Ein(gRBF)=0,那么这样的结果用于精确插值的函数估计(exact interpolation for function approximation)是非常好的,但是在机器学习中便会出现过拟合问题。所以可以加入 Regularization,当然前面学习过岭回归(ridge regression),可以将 regularized full RBFNet β \beta β 的求解改写为:
β = ( Z T Z + λ I ) − 1 Z T y \beta = \left( \mathrm { Z } ^ { T } \mathrm { Z } + \lambda \mathrm { I } \right) ^ { - 1 } \mathrm { Z } ^ { T } \mathrm { y } β=(ZTZ+λI)−1ZTy
在 kernel ridge regression 中,有一个 K \mathbf { K } K 矩阵:
Z = [ Gaussian ( x n , x m ) ] = Gaussian kernel matrix K \mathrm { Z } = \left[ \text {Gaussian } \left( \mathbf { x } _ { n } , \mathbf { x } _ { m } \right) \right] = \text { Gaussian kernel matrix } \mathbf { K } Z=[Gaussian (xn,xm)]= Gaussian kernel matrix K
在 kernel ridge regression 中, β \beta β 的求解为:
β = ( K + λ I ) − 1 y \beta = ( \mathrm { K } + \lambda \mathrm { I } ) ^ { - 1 } \mathrm { y } β=(K+λI)−1y
两者很相近,但是由于正则化的对象不同所以求解公式也不同,在核岭回归中的针对的正则化对象为无限多维的转换。而 RBF 中针对的是有限多维的 N N N 维的转换。
K均值算法(k-Means Algorithm)
反观 SVM,实际上并没有使用到全部的 x n \mathbf x_n xn ,而只是用到了支持向量,即 M ≪ N M \ll N M≪N。
g s v m ( x ) = sign ( ∑ S V α m y m exp ( − γ ∥ x − x m ∥ 2 ) + b ) g _ { \mathrm { svm } } ( \mathbf { x } ) = \operatorname { sign } \left( \sum _ { \mathrm { SV } } \alpha _ { m } y _ { m } \exp \left( - \gamma \left\| \mathbf { x } - \mathbf { x } _ { m } \right\| ^ { 2 } \right) + b \right) gsvm(x)=sign(SV∑αmymexp(−γ∥x−xm∥2)+b)
也就是通过限制中心的个数和投票的权重来达到正则化的效果(regularization by constraining number of centers and voting weights)。
现在的思路是找出一些“中心”代表(prototypes)。
聚类问题(Clustering Problem)
找代表的过程实际上是一种聚类问题。什么意思呢?
if x 1 ≈ x 2 ⟹ no need both RBF ( x , x 1 ) & RBF ( x , x 2 ) in RBFNet ⟹ cluster x 1 and x 2 by one prototype μ ≈ x 1 ≈ x 2 \begin{array} { l } \quad \text { if } \mathbf { x } _ { 1 } \approx \mathbf { x } _ { 2 } \\ \Longrightarrow \text { no need both } \operatorname { RBF } \left( \mathbf { x } , \mathbf { x } _ { 1 } \right) \& \operatorname { RBF } \left( \mathbf { x } , \mathbf { x } _ { 2 } \right) \text { in RBFNet } \\ \Longrightarrow \text { cluster } \mathbf { x } _ { 1 } \text { and } \mathbf { x } _ { 2 } \text { by one prototype } \mu \approx \mathbf { x } _ { 1 } \approx \mathbf { x } _ { 2 } \end{array} if x1≈x2⟹ no need both RBF(x,x1)&RBF(x,x2) in RBFNet ⟹ cluster x1 and x2 by one prototype μ≈x1≈x2
也就是说 RBF ( x , x 1 ) \operatorname { RBF } \left( \mathbf { x } , \mathbf { x } _ { 1 } \right) RBF(x,x1) 可以很大程度上代表(表示) RBF ( x , x 2 ) \operatorname { RBF } \left( \mathbf { x } , \mathbf { x } _ { 2 } \right) RBF(x,x2)。
那么这种通过代表(代理人)进行聚类(clustering with prototype)的过程为:
- 将 { x n } \left\{ \mathbf { x } _ { n } \right\} {xn} 分为M个互斥(不想交)的集合(disjoint sets): S 1 , S 2 , ⋯ , S M S _ { 1 } , S _ { 2 } , \cdots , S _ { M } S1,S2,⋯,SM。
- 为每一个 S m S_m Sm 选择最佳的 μ m ≈ x 1 m ≈ ⋯ ≈ x K m { \mu } _ { m } \approx \mathbf { x } _ { 1_m } \approx \cdots \approx \mathbf { x } _ { K_m } μm≈x1m≈⋯≈xKm ,其中 x 1 m ⋯ x K m ∈ S m \mathbf { x } _ { 1_m } \cdots \mathbf { x } _ { K_m } \in S _ { m } x1m⋯xKm∈Sm。
使用平方测量的聚类误差
E i n ( S 1 , ⋯ , S M ; μ 1 , ⋯ , μ M ) = 1 N ∑ n = 1 N ∑ m = 1 M [ x n ∈ S m ] ∥ x n − μ m ∥ 2 E _ { \mathrm { in } } \left( S _ { 1 } , \cdots , S _ { M } ; \mu _ { 1 } , \cdots , \mu _ { M } \right) = \frac { 1 } { N } \sum _ { n = 1 } ^ { N } \sum _ { m = 1 } ^ { M } \left[ \mathbf { x } _ { n } \in S _ { m } \right] \left\| \mathbf { x } _ { n } - \boldsymbol { \mu } _ { m } \right\| ^ { 2 } Ein(S1,⋯,SM;μ1,⋯,μM)=N1n=1∑Nm=1∑M[xn∈Sm]∥xn−μm∥2
所以现在的聚类问题的优化目标为:
min { S 1 , ⋯ , S M : μ 1 , ⋯ , μ M } E i n ( S 1 , ⋯ , S M ; μ 1 , ⋯ , μ M ) \min _ { \left\{ S _ { 1 } , \cdots , S _ { M } : \mu _ { 1 } , \cdots , \mu _ { M } \right\} } E _ { i n } \left( S _ { 1 } , \cdots , S _ { M } ; \mu _ { 1 } , \cdots , \mu _ { M } \right) {S1,⋯,SM:μ1,⋯,μM}minEin(S1,⋯,SM;μ1,⋯,μM)
优化(Optimization)
在优化过程中涉及到两个部分的最佳化问题:如何分群以及如何寻找中心点。
这样的组合和数值( combinatorial-numerical optimization)两个问题结合优化的过程是比较难以优化的:
那么如果只对一个问题寻优,那么问题就会简单很多。
分区寻优(Partition Optimization)
假设 μ 1 , μ 2 , … , μ k \mu _ { 1 } , \mu _ { 2 } , \ldots , \mu _ { k } μ1,μ2,…,μk 已经固定,那么一个又一个地通过下面这个公式选择最优的组群:
optimal chosen subset S m = the one with minimum ∥ x n − μ m ∥ 2 \text { optimal chosen subset } S _ { m } = \text { the one with minimum } \left\| \mathbf { x } _ { n } - \boldsymbol { \mu } _ { m } \right\| ^ { 2 } optimal chosen subset Sm= the one with minimum ∥xn−μm∥2
也就是对于每一个 x n \mathbf { x } _ { n } xn 都在 μ 1 , μ 2 , … , μ k \mu _ { 1 } , \mu _ { 2 } , \ldots , \mu _ { k } μ1,μ2,…,μk 中选择最近的 μ m \mu _ { m } μm ,并以此为依据进行最优分区(optimally partitioned)。
代表寻优(Prototype Optimization)
假设 S 1 , ⋯ , S M S _ { 1 } , \cdots , S _ { M } S1,⋯,SM 已经固定,那么这个优化问题便成为了一个关于每一个 μ m \mu _ m μm 的无约束最优化问题:
∇ μ m E i n = − 2 ∑ n = 1 N [ x n ∈ S m ] [ x n − μ m ) = − 2 ( ( ∑ x n ∈ S m x n ) − ∣ S m ∣ μ m ) \nabla _ { \boldsymbol { \mu } _ { m } } E _ { \mathrm { in } } = - 2 \sum _ { n = 1 } ^ { N } \left[ \mathbf { x } _ { n } \in S _ { m } \right] \left[ \mathbf { x } _ { n } - \boldsymbol { \mu } _ { m } \right) = - 2 \left( \left( \sum _ { \mathbf { x } _ { n } \in S _ { m } } \mathbf { x } _ { n } \right) - \left| S _ { m } \right| \boldsymbol { \mu } _ { m } \right) ∇μmEin=−2n=1∑N[xn∈Sm][xn−μm)=−2((xn∈Sm∑xn)−∣Sm∣μm)
可以看出来最优的代表值便是全部样本的平均值:
optimal prototype μ m = average of x n within S m \text { optimal prototype } \mu _ { m } = \text { average of } \mathbf { x } _ { n } \text { within } S _ { m } optimal prototype μm= average of xn within Sm
对于每个 S 1 , S 2 , … , S k S _ { 1 } , S _ { 2 } , \ldots , S _ { k } S1,S2,…,Sk 都求均值作为最佳 μ m \mu_m μm 的计算方法(optimally computed)。
具体实现
(1) initialize μ 1 , μ 2 , … , μ k : say, as k randomly chosen x n (2) alternating optimization of E in : repeatedly (1) Optimize S 1 , S 2 , … , S k : each x n optimally partitioned using its closest μ i (2) Optimize μ 1 , μ 2 , … , μ k : each μ n optimally computed as the consensus within S m until converge \begin{array} { l } \text { (1) initialize } \mu _ { 1 } , \mu _ { 2 } , \ldots , \mu _ { k } : \text { say, as } k \text { randomly chosen } x _ { n } \\ \text { (2) alternating optimization of } E _ { \text {in } } \text { : repeatedly } \\ \qquad \text { (1) Optimize } S _ { 1 } , S _ { 2 } , \ldots , S _ { k } : \text { each } x _ { n } \text { optimally partitioned using its closest } \mu _ { i } \\ \qquad \text { (2) Optimize } \mu _ { 1 } , \mu _ { 2 } , \ldots , \mu _ { k } \text { : each } \mu _ { n } \text { optimally computed as the consensus within } S _ { m } \\ \qquad \text { until converge } \end{array} (1) initialize μ1,μ2,…,μk: say, as k randomly chosen xn (2) alternating optimization of Ein : repeatedly (1) Optimize S1,S2,…,Sk: each xn optimally partitioned using its closest μi (2) Optimize μ1,μ2,…,μk : each μn optimally computed as the consensus within Sm until converge
收敛(converge ): S 1 , S 2 , … , S k S _ { 1 } , S _ { 2 } , \ldots , S _ { k } S1,S2,…,Sk 不再改变。因为上述的交替迭代过程是使得 E in E _ { \text {in } } Ein 不断变小的过程,同时 E in E _ { \text {in } } Ein 的最小值为 0,所以必然收敛。
由于交替寻优(alternating minimization)的特性,K均值算法成为了最流行的距离算法。
正则化RBF网络
使用K均值算法,找出K个具有代表性的 μ k \mu _ k μk,来构造 N (examples) × K (centers) N \text{(examples)} \times K \text{(centers)} N(examples)×K(centers) 的 Z \mathrm{Z} Z 矩阵。
那么 RBF Network Using k-Means 的实现过程为:
(1) run k -Means with k = M to get { μ m } (2) construct transform Φ ( x ) from RBF (say, Gaussian) at μ m Φ ( x ) = [ RBF ( x , μ 1 ) , RBF ( x , μ 2 ) , … , RBF ( x , μ M ) ] (3) run linear model on { ( Φ ( x n ) , y n ) } to get β (4) return g RBFNET ( x ) = LinearHypothesis ( β , Φ ( x ) ) \begin{array} { l } \text { (1) run } k \text { -Means with } k = M \text { to get } \left\{ \boldsymbol { \mu } _ { m } \right\} \\ \text { (2) construct transform } \Phi ( \mathbf { x } ) \text { from RBF (say, Gaussian) at } \mu _ { m } \\ \qquad \mathbf { \Phi } ( \mathbf { x } ) = \left[ \operatorname { RBF } \left( \mathbf { x } , \mu _ { 1 } \right) , \operatorname { RBF } \left( \mathbf { x } , \mu _ { 2 } \right) , \ldots , \operatorname { RBF } \left( \mathbf { x } , \mu _ { M } \right) \right] \\ \text { (3) run linear model on } \left\{ \left( \mathbf { \Phi } \left( \mathbf { x } _ { n } \right) , y _ { n } \right) \right\} \text { to get } \beta \\ \text { (4) return } g _ { \text {RBFNET } } ( \mathbf { x } ) = \text { LinearHypothesis } ( \boldsymbol { \beta } , \mathbf { \Phi } ( \mathbf { x } ) ) \end{array} (1) run k -Means with k=M to get {μm} (2) construct transform Φ(x) from RBF (say, Gaussian) at μmΦ(x)=[RBF(x,μ1),RBF(x,μ2),…,RBF(x,μM)] (3) run linear model on {(Φ(xn),yn)} to get β (4) return gRBFNET (x)= LinearHypothesis (β,Φ(x))
这实际上就是使用无监督学习方法来辅助特征转换(using unsupervised learning (k-Means) to assist feature transform)。需要的参数有两个:一个是代表的个数 M M M,另一个是RBF的选择(比如中心为 γ \gamma γ 的高斯函数)。
k-Means和RBF网络的实际应用(k-Means and RBF Network in Action)
K-Means in Action
下面展示k-Means算法的实际优化过程:
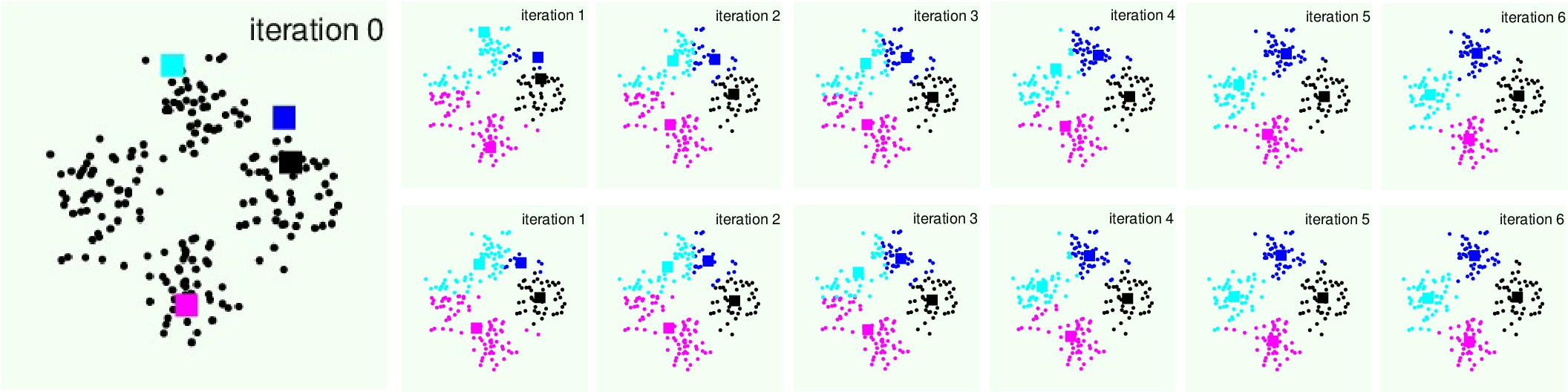
其中第一行是分区优化,第二行是代表(中心点)寻优。可看出合理的初始值和k可以获得不错的聚类效果。
RBF Network Using k-Means in Action
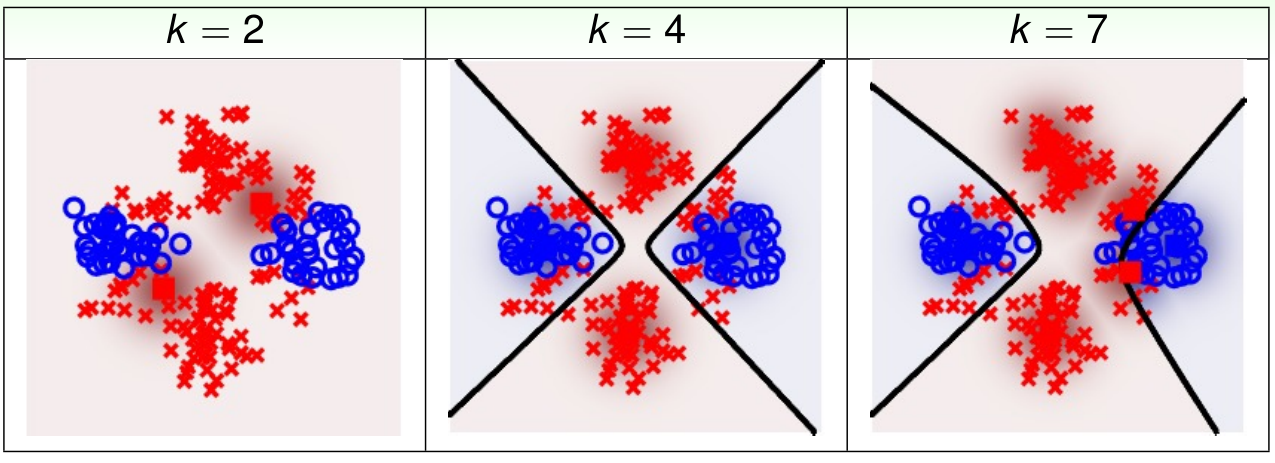
图中发黑的地方代表了高斯密度函数的分布形式。可以看出合理的中心点可以使得 RBF Network 获得比较好的效果。
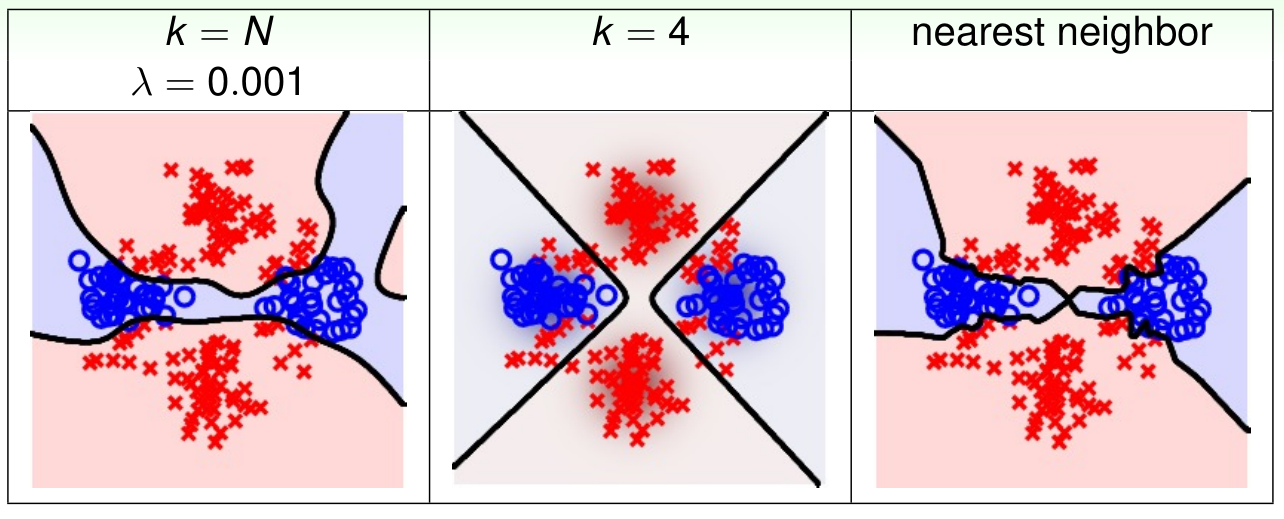
Full RBF Network in Action
最左边是使用了正则化的RBF的分类效果。最右边是最近邻算法的分类效果。因为两者在一定程度上都用到了全部的数据,所以看起来有些过拟合。所以在实际运用中完全 RBF 网络很少使用。















 1364
1364











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











