










Radial Basis Function Network
什么是Radial Basis Function
放射:说明我们的计算只与我们资料点x之间的距离有关。
基本函数:我们要将放射计算的模型进行线性组合。
如果把整个模型组合的过程想象成一种投票。
实务上我们首先计算放射函数模型,根据资料点与中心的距离决定它应该拿到多少票。然后再乘上它要投的是同意或者反对的票。最后得到一个与距离相关的函数模型。
得到函数模型之后,我们再将这些小的函数模型进行线性组合进而融合成一个大的模型。当然我们需要的仅仅是线性融合时权重不为0的那些模型。联想到SVM中就是我们只选用支撑向量的部分。

与一般神经网络的对比
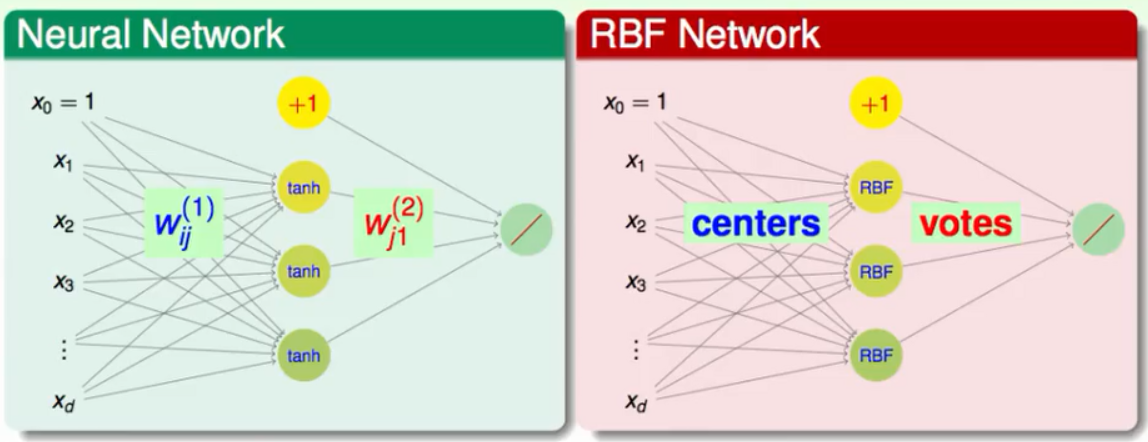
首先说它们的输出的方式是一样的都是将上一层的神经元进行线性组合。不同的是输入,一般的神经网络都是对输入与权重进行线性组合然后进行一些特征转换。而RBFN是计算每个输入与中心点的距离然后使用这些距离去计算RBF,最后将这些RBF进行投票(也就是线性组合)从而得到最终的模型。RBFN是一般神经网络的一个分支。
RBFNetwork模型
一般的RBFN模型如下:
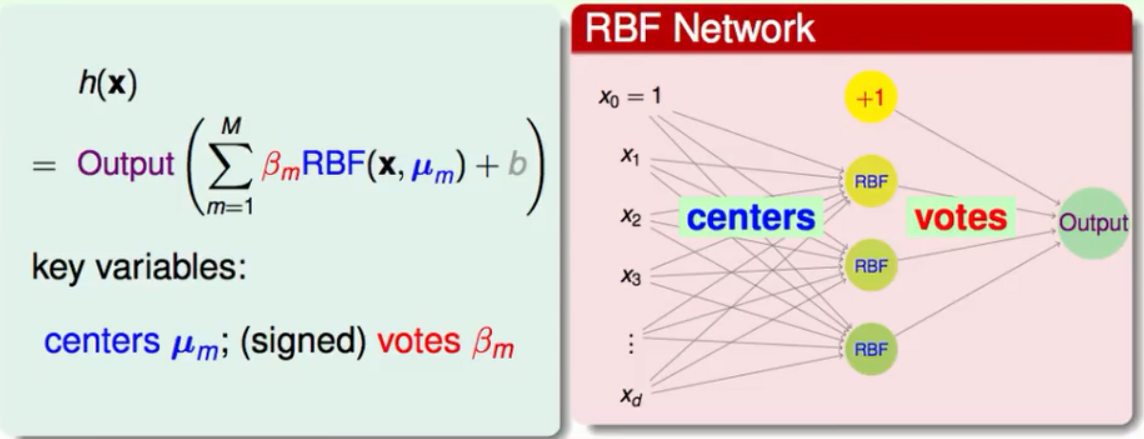
参数详解
①x我们输入的资料。
②μ资料的中心点。
③β每个模型所投的票数(每个模型的权重),可以通过SVM的对偶问题中的αy来计算。
④M一共融合模型的个数。(权重不为0的模型个数,也可以理解为支持向量机中的支持向量的个数)。
⑤RBF函数,我们常用的是高斯函数。
现在我们的任务就是在给定的RBF与Output的情况下去求出最好的中心点与最好的权重进而得到最好的模型。
RBF与相似性
在SVM中我们学过Kernel(核函数),事实上kernel表达的是一种相似性。它的具体操作就是将原始的两笔资料转换到另一个维度的空间去做内积(内积的大小就是一种相似性的体现),进而描述这两个向量的相似性。
在RBF中使用的是另一种相似性的衡量。它是使用两笔资料之间的距离来衡量,距离越近那么相似性越大。而高斯函数正好
除此之外还有其它的相似性的衡量,比如说在神经网络中是用当前权重与一笔资料的内积来做相似性的判断,这些都是不同的相似性的表现。相似性是一个很好的定义特征转换的方法。

Full RBFNetwork与KNN算法
按照一般的RBF来说我们会需要一个中心点的资料,但现在的场景是我们很懒没有去找那个所谓的中心点而是认为每个点都是中心点。这样的话一个新来的点都会受到以前资料点的投票表决,离新来的的点越近的所持有的票数越大。如果如果是二元分类,我们有N笔资料的话就会有N个中心点进行N次表决最后决定新的点的正负情况。以这样RBF构成的神经网络就叫做Full RBFNetwork。

KNN算法
假设我们现在使用的RBF函数是高斯函数(也就是正太函数)。我们依然遵循上面的规则让每一个点都进行投票。但是由于高斯函数衰减的很快,这就导致了距离新来的点最近的那个点会掌握大部分的票数如下图所示(一个伪正太分布):
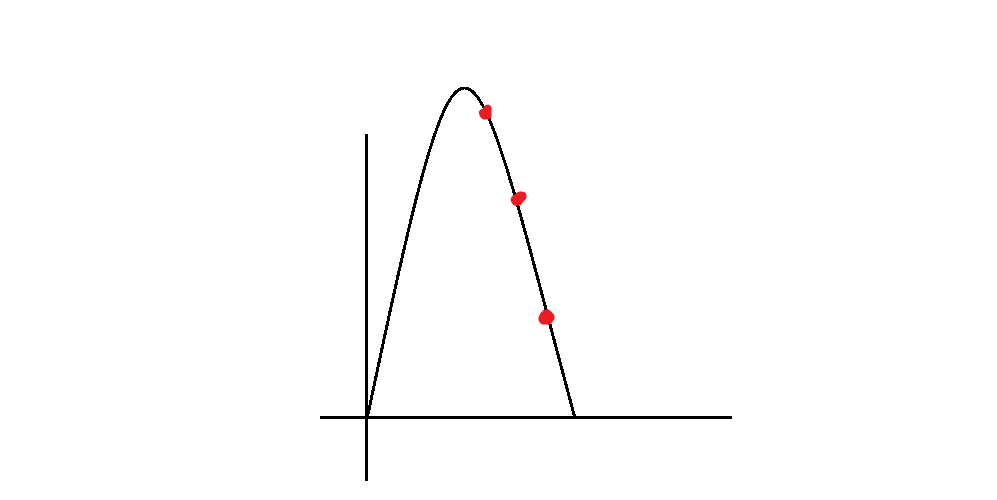
这样我们就能更加偷懒的用离新的资料点最近的那个点去估计新的资料点。或者是用离新的资料点最近的那几个点去预测这个新的资料点。这样就诞生了著名的K nearest neighbor 算法也就是KNN算法。
修正RBFNetwork
以前的RBFNetwork模型就是混合一堆的RBF模型然后做出每人一票但是票的权重不同。现在我们要更加优化这个票数什么人需要给更多的票什么人或许甚至不需要给票等等的情景。为了计算简单我们首先将最后的融合视为一个线性回归的问题,所以我们的目的就是要求出使得平方错误最小的权重。同时我们也要将RBF当做是一个原来资料的特征转换。转换后的问题与结论如下图所示:

①由于线性回归问题的最优问题有公式解,所以我们一步登天的完成了最优β的计算如上图所示。
②单个z向量(原始向量转换过后的向量)是一个n维的向量,所以Z矩阵就是一个n*n的方形对称矩阵。
③如果我们用到的函数是一个高斯函数的话,如果每一笔资料都不同那么Z矩阵就是一个可逆矩阵。由此β的表达式也就变成了β= Z逆*y。这样就得到了一个较为简单的表示结果。
Full RBFNetwork的正则化
在RBF为高斯函数的情况下,当我们拥有β的一种简单表示之后我们又有了以下的大发现。我们把x1这笔资料带入到我们的RBFNet的模型中会得到如下的结果:

x1(我们训练集中的一笔资料)的特征转换就是z1,也就相当于Z矩阵的第一列,Z逆*Z的第一列就会成为一个第一列为1其余行为0的向量。也就是说输入x1就得到y1,输入xn就得到yn。这样我们的模型就成为了一个在训练集上不会犯错的模型。但是在机器学习中一个模型在训练集上犯错误的概率为0那么它很可能有过拟合的危险。所以我们需要对这个模型进行正则化。所以我们要在β的解上面使用山脊回归(Ridge Regression)而不是普通的线性回归。

除此之外我们还能使用其它的正则化。比如在SVM中我们并没有使用所有的点去决定我们的边界而是只用到了少数的支持向量。对应到这个场景,我们不需要每个点都来投票我们只需要选出一些代表的点来投票就好了这样也可以达到正则化的效果。
Full RBFNetwork与K-means算法
如何选择资料的代表:一个聚类的问题
什么是好的代表?如果μ是x与y的代表那么就会有μ≈x≈y。也就是说μ能够代表一定范围内的点也就是一个群内的点。要知道那一个点属于那个群就要知道这个点与哪个群的代表最为接近。而要找到几个好的代表就需要给现有的资料进行分群。当我们找到了群以及他们群的代表我们就能够给新来的点进行投票。假设Sm为第m个群,μm为第m群的代表。那么我们将有如下的错误衡量的函数:

我们的目标就是要使得错误最小化。
组合最优化问题:K-means算法
我们想要求出一个群的代表就需要知道那些点属于这个群,但是我们想要知道一个点属于哪个群就需要知道群的代表的情况,这是一个鸡生蛋蛋生鸡的问题。所以我们不能够同时找到最优的群的分配并且找到最优的代表,而是先定好一个量去求另一个量然后迭代更新最后达到最优的结果。
①如果每个群的代表μ固定的话
对于每个x来说就能够通过它与不同μ之间的平方差来估计自己属于哪个群

②当每个群固定的话
我们就能够利用当前群中各个资料的平均来求出新一轮的代表。

实务上我们一开始会随机选择几个群的代表然后利用上述步骤去更新直到最好的结果。这个算法也就是著名的K-means算法。
我们在使用K-means算法找到最佳的代表之后将这个结果搭载到我们的RBFNet上就会得到一个带有正则化味道的演算法。这里使用了非监督的演算法来萃取到特征这一点与deeplearning中的autoencoder一样。最后重要的是K-means演算法的表现对分群的数量有所依赖。


















 2056
2056

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











