







写在前面
TimeGPT是由Nixtla开发的一款专门用于预测任务的生成式预训练Transformer模型。TimeGPT是在有史以来最大的数据集上进行训练的——超过1000亿行的金融、天气、能源和网络数据。这个工具能够在几秒钟内识别出模式并预测未来的数据点。在本文中,我们利用Nixtla的nixtlats框架,实现一个将TimeGPT应用于股票价格预测的简单例子。
1
TimeGPT
TimeGPT是一种创新的时间序列预测模型,它代表了将深度学习技术应用于时间序列分析的前沿尝试。作为一个基于生成式预训练Transformer(Generative Pre-trained Transformer, GPT)的模型,TimeGPT的核心理念是利用大数据集进行深度训练,从而实现对复杂时间序列数据的高精度预测。该模型的突破性在于其独特的能力,可以处理各种类型的时间序列数据,包括但不限于金融、天气、能源和网络数据。通过在超过1000亿行数据上的训练,TimeGPT展示了如何在短时间内识别出模式并预测未来的数据点,同时显著降低计算复杂性。TimeGPT的架构特别设计用于适应不同的输入大小和预测时段,其核心是一个高效的Transformer网络。这种架构允许模型学习和理解数据中的长期依赖性,这在时间序列分析中至关重要。此外,TimeGPT的创新性还体现在其训练过程中,模型不仅要在大规模数据集上训练以获得广泛的时间序列认知,还要能够最小化预测误差。总体来说,TimeGPT的开发标志着时间序列分析领域的一个重要转折点。它不仅展示了大型时间序列模型在提高预测精度和减少不确定性方面的潜力,而且强调了深度学习在未来时间序列分析中的重要角色。

TimeGPT采用了完整的编码器-解码器Transformer架构,这种架构允许模型有效地处理复杂的时间序列数据。在这个架构中,输入可以是历史数据窗口,也可以包括外生数据窗口。这种灵活的输入机制使TimeGPT能够适应多种不同类型的时间序列分析任务。在模型内部,输入首先被输入到编码器部分。编码器利用内部的注意力机制从输入中学习和识别不同的属性和模式。学习到的信息随后被传递到解码器,解码器使用这些信息来生成预测。这个过程持续进行,直到达到用户设定的预测范围长度。一个关键的特性是TimeGPT在模型中实现了适形预测(conformal prediction),这允许模型基于历史误差估计来预测区间。这不仅增强了模型的预测准确性,而且提高了其在异常检测方面的能力。例如,如果一个数据点落在99%的置信区间之外,模型可以将其标记为异常,这对于风险管理和早期警报系统非常有价值。此外,TimeGPT作为一个预训练的模型,它可以在没有特定针对新数据的训练的情况下生成预测,同时还支持根据特定数据进行微调。

2
环境配置
本地环境:
Python 3.8
IDE:VScode库版本:
Nixtla version: 0.5.1
Pandas version: 2.0.3
Matplotlib version: 3.7.5
NumPy version: 1.24.4
Scikit-learn version: 1.3.23
代码实现
获取API token
在使用TimeGPT之前,需要先去Nixtla官网注册账号并获取API token:https://docs.nixtla.io/docs,如下图所示。


之后在控制台中创建API key,目前API的调用支持每分钟200次的调用,后续TimeGPT会设置一些调用收费的规则:

具体地TimeGPT的其他用法,包括异常检测,不规则时间步预测以及微调等同样也可以在它的文档中查看:
https://docs.nixtla.io/docs/getting-started-about_timegpt
代码实现
在进行TimeGPT的使用之前,需要先安装nixtla库。
pip install nixtla导入必要的库:
from nixtla import NixtlaClient
import pandas as pd
import matplotlib.pyplot as plt
import numpy as np
from sklearn.metrics import mean_absolute_error, mean_squared_error将申请的Token填入NixlaClient进行初始化:
nixtla_client = NixtlaClient(api_key = 'Your Token')
nixtla_client.validate_api_key()如果token没有问题,则会显示:
INFO:nixtla.nixtla_client:Happy Forecasting! :), If you have questions or need support, please email ops@nixtla.io这里股价预测的例子用到的是浦发银行sh.60000的五分钟级别数据,用前60个时间点来预测后5个时间点的价格趋势。
input_size = 5 * 12
horizon = 5
window_size = input_size + horizon
df = pd.read_csv('./SH600001.csv')[:2000]
windows = create_windows(df, window_size, horizon)由于TimeGPT的输入形式需要是Dataframe的数据格式,所以这里先手动实现一个构建滑动窗口的方式:
def create_windows(df, window_size, overlap):
"""
将时间序列的 DataFrame 转换为多个重叠的窗口
:param df: 输入的时间序列 DataFrame
:param window_size: 窗口的大小
:param overlap: 窗口之间的重叠大小
:return: 包含每个窗口 DataFrame 的列表
"""
step_size = window_size - overlap
windows = []
for start in range(0, len(df) - window_size + 1, step_size):
end = start + window_size
window = df.iloc[start:end]
windows.append(window)
return windows之后调用TimeGPT进行预测,这里进行预测时是通过TimeGPT的零样本推理方式进行预测的,即没有再针对特定数据的训练,而是通过大量时间序列数据训练后习得的能力。
prediction_list = []
ground_truth_list = []
for df in windows:
input_df = df[:input_size]
timegpt_fcst_df = nixtla_client.forecast(df=input_df, h=horizon, freq='5T', time_col='Date', target_col='Close', model='timegpt-1')
prediction = timegpt_fcst_df['TimeGPT'].values
ground_truth = input_df['Close'].values[-horizon:]
prediction_list.append(prediction)
ground_truth_list.append(ground_truth)其中,forecast函数中的主要参数的用法如下:
df:用于输入的pandas.DataFrame。至少包含以下列:
time_col:在 df 中包含时间序列的时间索引的列名。这通常是一个具有规律间隔的日期时间列,例如,每小时、每日、每月的数据点。
target_col:在 df 中包含时间序列目标变量的列名。
id_col:在 df 中用于识别唯一时间序列的列名。此列中的每个唯一值对应一个独特的时间序列,用于区别多条时间序列的预测。
h:预测的时间步数。
freq:数据的频率。默认情况下,频率将被自动推断。
id_col(默认值='unique_id'):用于识别每个时间序列的列。
time_col(默认值='ds'):用于识别时间戳,其值可以是时间戳或整数。
target_col(默认值='y'):包含目标值的列。
X_df(可选,默认值=None):包含 ['unique_id', 'ds'] 列和 df 的未来外生变量的 DataFrame。
level(可选,默认值=None):预测区间的置信水平列表,范围在0到100之间。
quantiles(可选,默认值=None):要预测的分位数列表,范围在 (0, 1) 之间。
finetune_steps(默认值=0):用于在新数据中微调 TimeGPT 的步数。
finetune_loss(默认值='default'):用于微调的损失函数。选项包括:default, mae, mse, rmse, mape, 和 smape。
clean_ex_first(默认值=True):使用 TimeGPT 进行预测前清理外生信号。
add_history(默认值=False):返回模型的拟合值。
date_features(可选,默认值=False):从日期计算得出的特征。可以是 pandas 日期属性或将日期作为输入的函数。如果为 True,则自动添加对于 df 的频率最常用的日期特征。
date_features_to_one_hot(默认值=True):对这些日期特征应用一键热编码。如果date_features=True,则默认对所有日期特征进行一键热编码。
model(默认值='timegpt-1'):作为使用的模型。选项包括:timegpt-1, 和 timegpt-1-long-horizon。如果希望预测超过一个季节期间的数据,推荐使用 timegpt-1-long-horizon 进行预测。
将预测的数据和真实值进行可视化,可以看出TimeGPT拟合出了一些趋势信息。
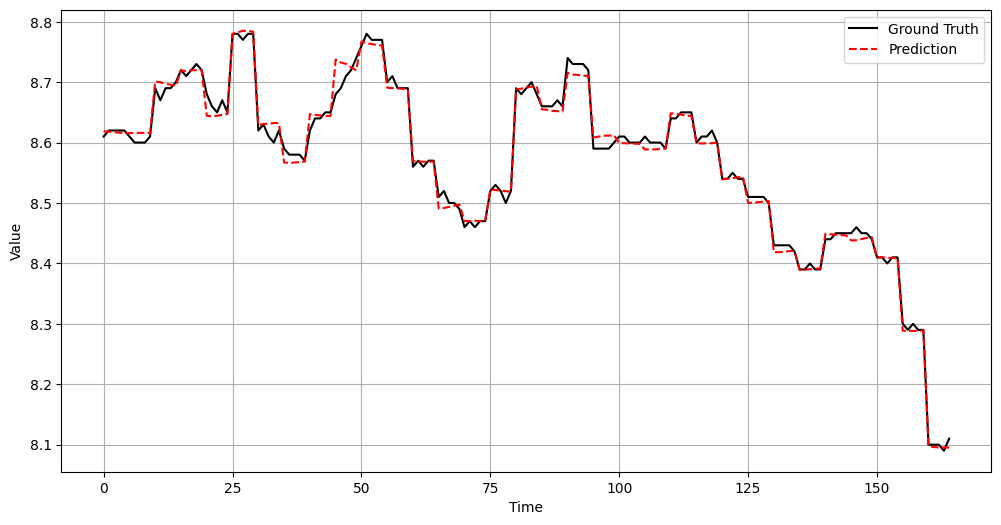
目前TimeGPT还不支持历史外生变量的引入,只支持未来外生变量,即未来可知的信息,例如节假日,天气等。如果想引入历史外生变量,则需要先对历史外生变量进行预测,得到它们的未来值作为forecast函数中X_df参数来传递进去。
下面展示了浦发银行sh.60000天级别的数据的预测效果。其中用前300天来预测后50天,并设置了80,90 level的置信区间。由于涉及到了长周期预测,这里用到的模型是timegpt的长周期预测版本timegpt-1-long-horizon,然后调用其内部的接口对其进行可视化:
all_df = pd.read_csv('./SH600000_Day.csv')[:350]
input_df = all_df[:300]
horizon=50
timegpt_fcst_df = nixtla_client.forecast(df=input_df, h=horizon, freq='B', time_col='Date', target_col='Close', model='timegpt-1-long-horizon', level=[80, 90])
nixtla_client.plot(df=all_df, forecasts_df=timegpt_fcst_df, level=[80, 90], time_col='Date', target_col='Close')
由于股票的长周期预测难度较大,TimeGPT仅能拟合出大致的趋势。为了提升预测精度,可以在forecast函数中指定微调的步数。在此示例中,我们将fintune_steps设置为20,然后进行预测。经过微调后,模型的预测结果展示出了趋势的变化,尤其是预测到了下降的趋势。这表明微调对模型更好地捕捉股票价格的动态变化有一定的帮助。

4
总结
TimeGPT的独特之处在于其将LLM背后的技术和Transformer架构应用于时间序列预测,并构建除了第一个可以实现零样本推理的时间序列基础模型。TimeGPT经过海量数据的预训练,不仅能够捕捉到深层次的时间依赖性,还能适应不同行业领域的需求,为未来的趋势提供预测指导。通过本文的实例,我们展示了如何利用TimeGPT在股票市场预测中进行预测的示例,尽管没有取得显著的表现,但也展现了零样本推理大模型在股票市场的初步表现。未来,我们期待看到更多创新的时序大模型案例,以及这一技术如何进一步推动时间序列分析的边界。
参考资料:
Garza, A., & Mergenthaler-Canseco, M. (2023). TimeGPT-1. arXiv preprint arXiv:2310.03589.
https://docs.nixtla.io/docs/getting-started-about_timegpt
本文内容仅仅是技术探讨和学习,并不构成任何投资建议。
获取完整代码与数据以及其他历史文章完整源码与数据可加入《人工智能量化实验室》知识星球。
往期推荐阅读
解读:ChatGPT在股票市场预测方面的应用
【python量化】多种Transformer模型用于股价预测(Autoformer, FEDformer和PatchTST等)
【python量化】挖掘股价中的图关系:基于图注意力网络的股价预测模型
【python量化】基于backtrader的深度学习模型量化回测框架
【python量化】将Transformer模型用于股票价格预测

《人工智能量化实验室》知识星球

加入人工智能量化实验室知识星球,您可以获得:(1)定期推送最新人工智能量化应用相关的研究成果,包括高水平期刊论文以及券商优质金融工程研究报告,便于您随时随地了解最新前沿知识;(2)公众号历史文章Python项目完整源码;(3)优质Python、机器学习、量化交易相关电子书PDF;(4)优质量化交易资料、项目代码分享;(5)跟星友一起交流,结交志同道合朋友。(6)向博主发起提问,答疑解惑。
















 1044
1044











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









