






1. dreamfields
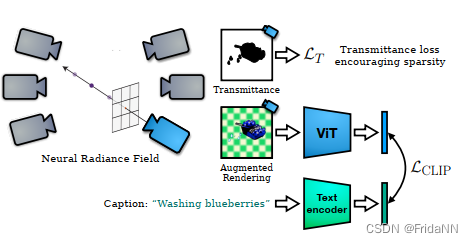
利用预训练的图像和文本编码器,构造CLIP loss用于优化NeRF,实现文字生成三维物体。并且使用一些方法优化生成效果,如:对透射率增加正则化、随机相机位置采样、固定物体位置、3d数据增强(遮蔽背景、随机剪裁)。
1)为了描述文字和渲染图片的相似性,设计CLIP loss:![]()
其中分别为图像编码器和文字编码器;
是在pose下渲染的图片。
2)由于NeRF倾向于学习高频和信息,所以会出现半透明物体漂浮在空间中。这些高频信息会填满相机视角,而不会用于生成物体。所以作者想到约束渲染的透明度。所以对场景的透明度分布的均值设计约束。
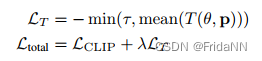
由于如果对一个黑色或白色的alpha-blending的场景渲染,则场景中带密度的点会随着反向传播增加。所以在训练时为物体增加随机的背景(如棋盘格、高斯噪声、随机傅里叶纹路)
3)由于远离物体的点有密度,也能满足CLIP loss,所以需要限制密度分布的重心。
4) 对MLP增加带有layer normalization的残差结构,能够优化模型在复杂prompt的表达能力。
注:
dream fields和NeRF的差别:dreamfileds中的MLP输出颜色只受光线方向
影响,不受viewing direction( azimuthal angle θ, and polar angle φ)影响。dreamfusion保留了该设置
2. clip-mesh
由于dreamfields输出NeRF,存在纹理和几何难解耦,计算量大等问题。而clip-mesh可以直接输出mesh。文章利用Loop subdivision、embedding prior以及渲染器增强作为正则化项优化模型输出。
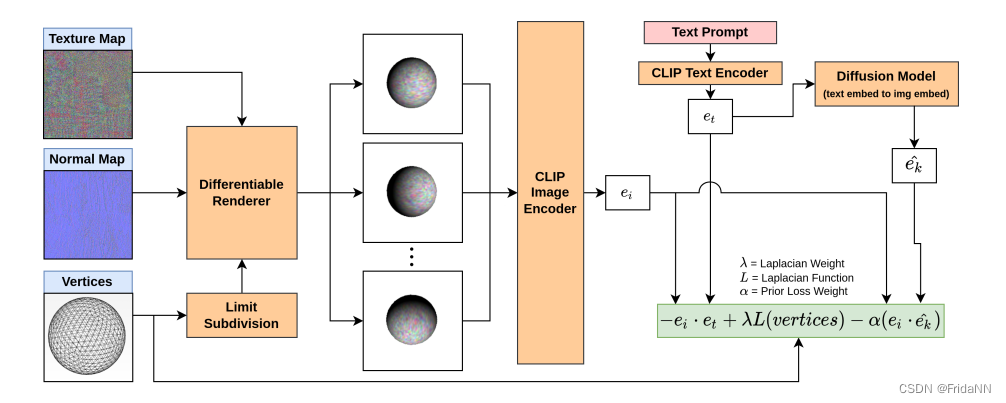
模型将纹理图、初始化控制点网格、法线图输入到可微渲染器中,优化三者。模型使用初始化控制点网格按照loop subdivision计算limit surface。
其中使用的可微渲染器:Modular Primitives for High-Performance Differentiable Rendering (arxiv.org)
结构如下: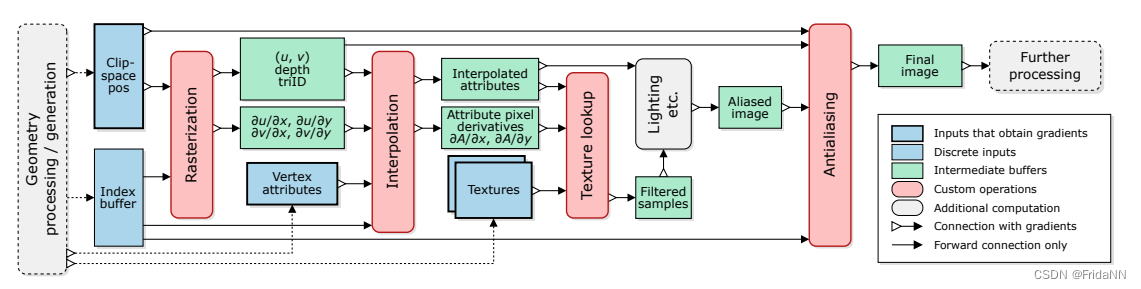
1)laplacian regularizer
为了使得网格整体紧凑,使用laplacian regularizer,最小化顶点和相邻顶点的平均距离:
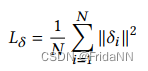
2)diffuse prior
用扩散模型根据prompt生成的图片再送入clip,将clip得到的图像embedding和渲染的图像embedding计算相似度。
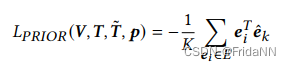
3)CLIP loss
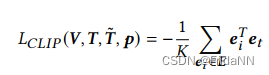
-----------
1. CLIP是什么?
CLIP 的全称为Contrastive Language-Image Pre-training。首先,什么是Contrastive Learning(对比学习)。通过对比样本学习类别和特征的共性和区别。CLIP不需要额外的训练数据,就能改为为另一个视觉任务分类。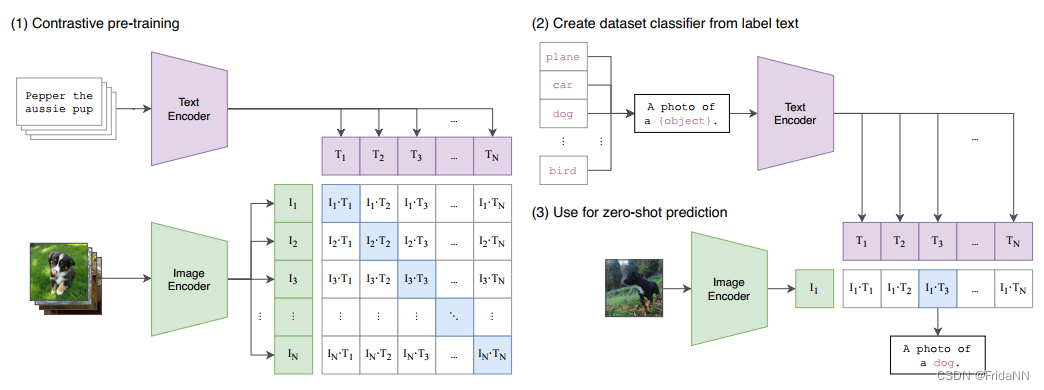
使用CLIP包含三个步骤:
1)向CLIP的图像和文字编码其中输入文字
2)编码器计算两者的embedding.
3)计算两个embedding 的余弦相似度
两个结构中,image encoder都使用ViT;第一个结构中的text encoder使用ResNet,第二个结构中使用Transformer。
2.CLIP结合生成模型的方式
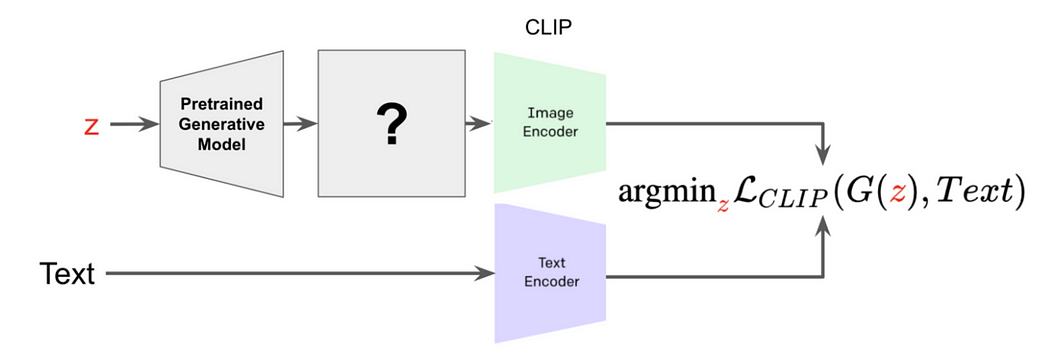
--------------------
1.VIT-L/16:Large参数量+16*16patch尺寸

-----------
1.laplace operator:二阶微分操作符
divergence of a gradient
:
由于gradient:
所以laplace:
--------
1.extreme close up
close-up shot的升级版,有时只显示主体的眼睛。close-up shots指非常靠近主体,整张照片充满主体细节。
2.azimuth angle:方位角&elevation angle:仰角
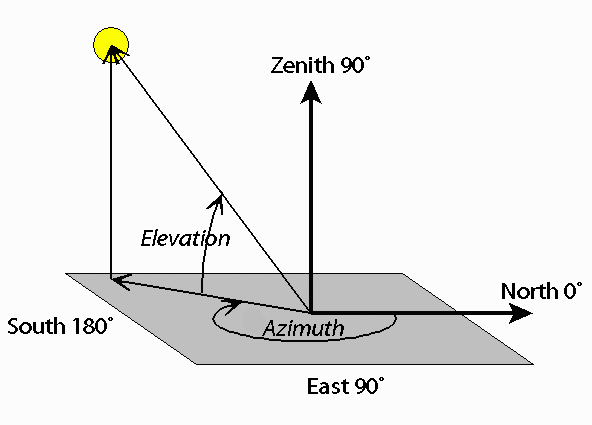
3.reverberation 混响:光线在封闭空间的多次弹射,弥留在空间中。
4.standard deviation:标准差















 454
454











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









