






今天分享的是智能汽车系列深度研究报告:《智能汽车专题:汽车行业智能驾驶研究框架:(三)特斯拉专题》。
(报告出品方:财通证券)
报告共计:32页
来源:人工智能学派
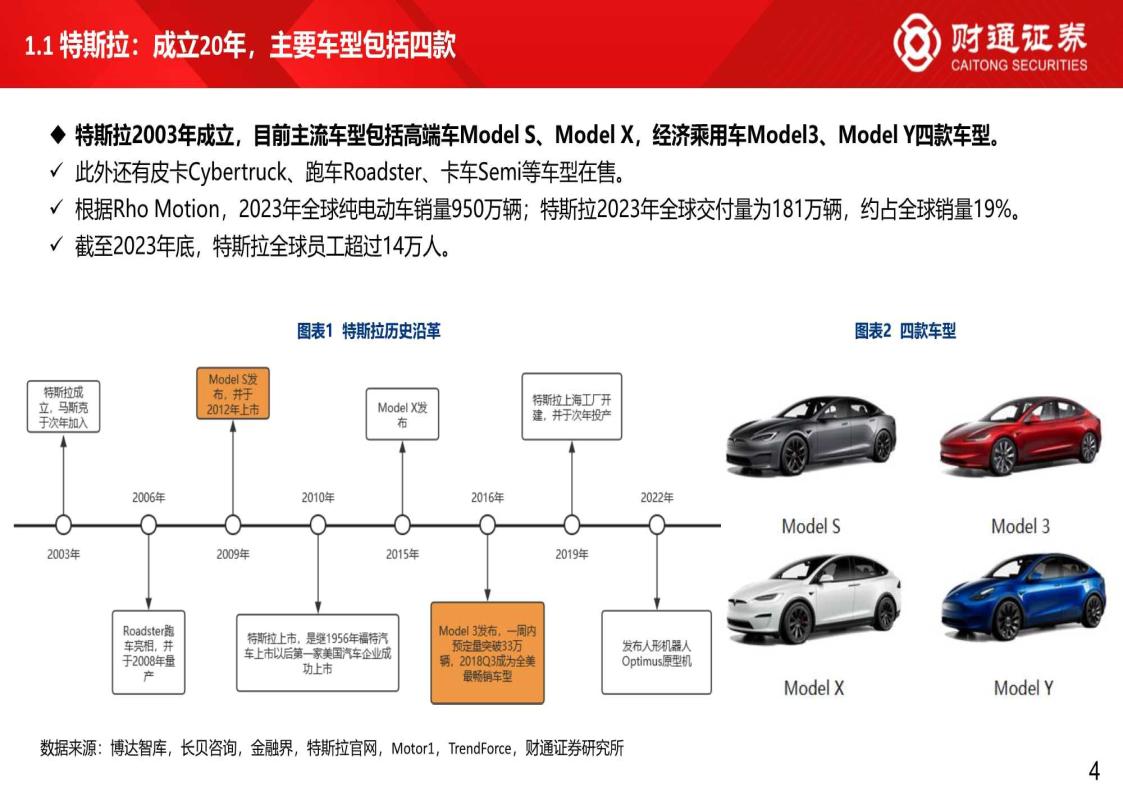
特斯拉:成立20年,主要车型包括四款
特斯拉2003年成立,目前主流车型包括高端车ModelS、ModelX,经济乘用车Model3、ModelY四款车型。此外还有皮卡Cybertruck、跑车Roadster、卡车Semi等车型在售。
根据Rho Motion,2023年全球纯电动车销量950万辆;特斯拉2023年全球交付量为181万辆,约占全球销量19%。截至2023年底,特斯拉全球员工超过14万人。
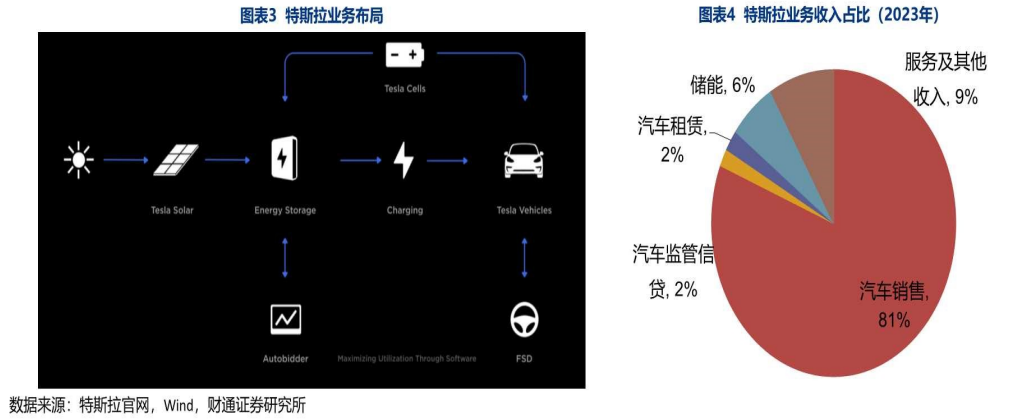
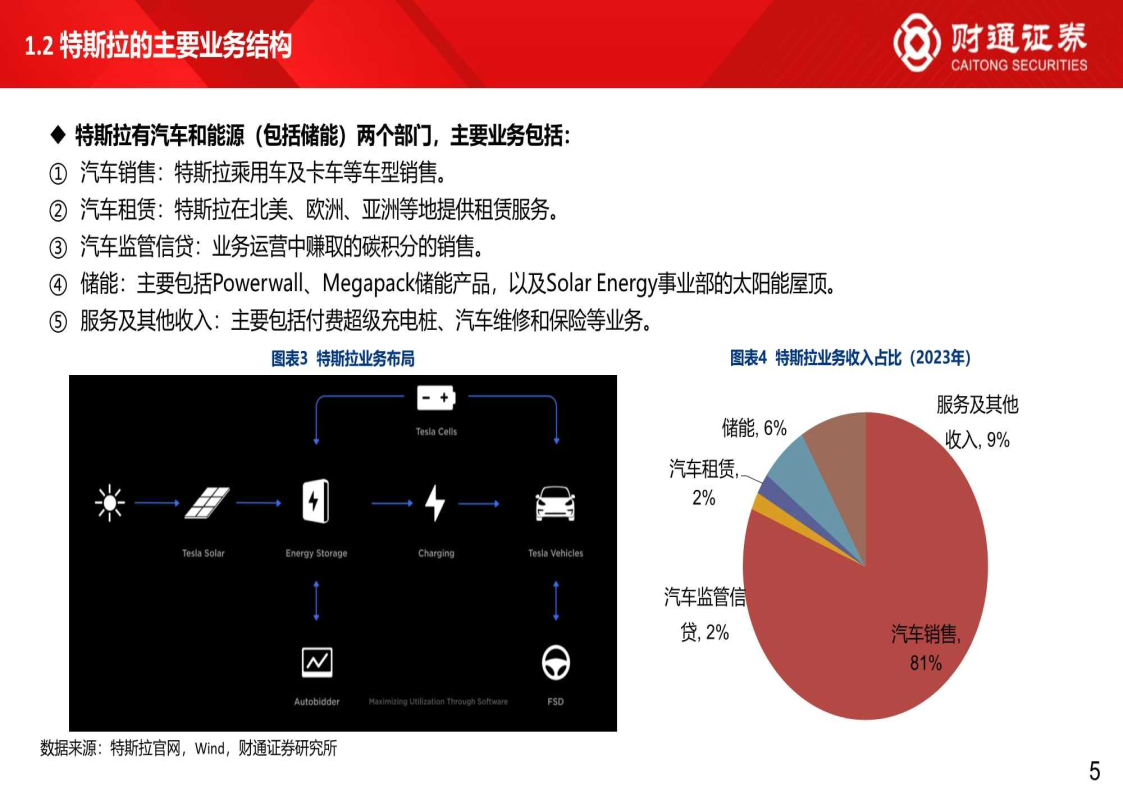
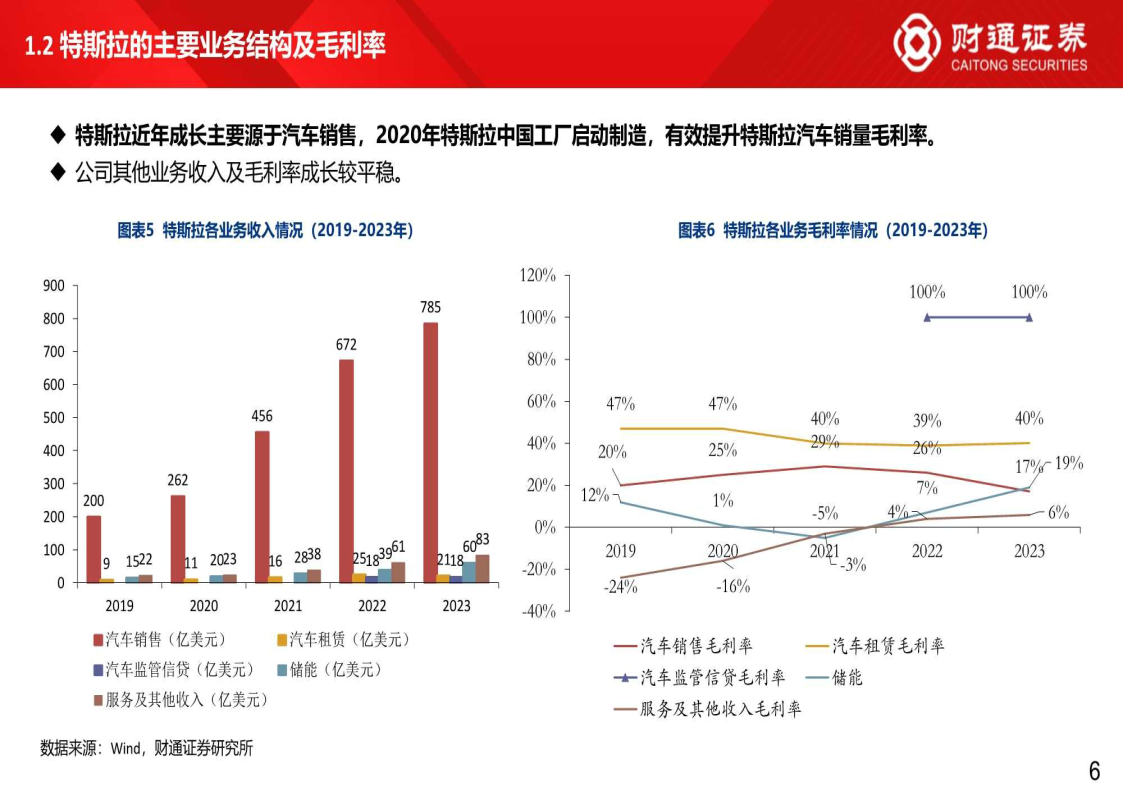
特斯拉的主要业务结构
特斯拉有汽车和能源(包括储能)两个部门,主要业务包括:汽车销售:特斯拉乘用车及卡车等车型销售。
- 汽车租赁:特斯拉在北美、欧洲、亚洲等地提供租赁服务。
- 汽车监管信贷:业务运营中赚取的碳积分的销售。
- 储能:主要包括Powerwal、Megapack储能产品,以及SolarEnergy事业部的太阳能屋顶服务及其他收入:主要包括付费超级充电桩、汽车维修和保险等业务。
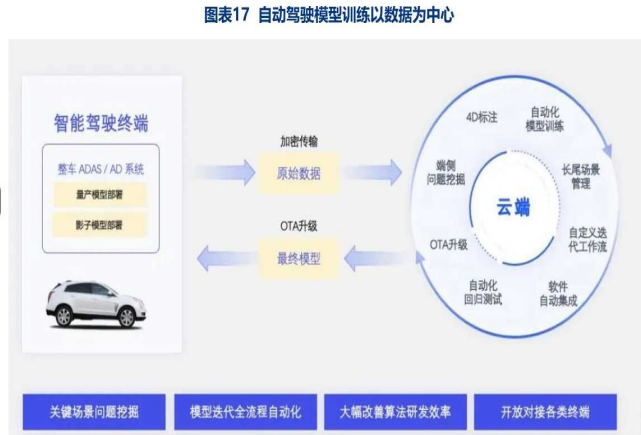
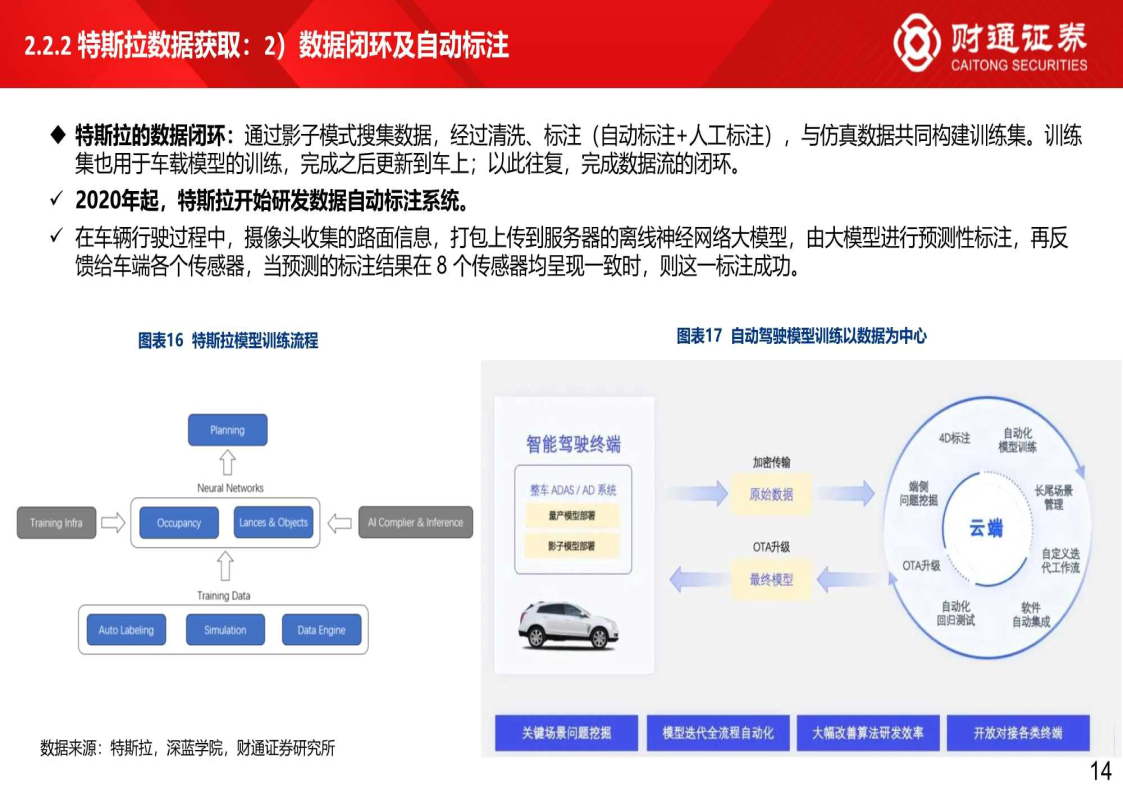
特斯拉数据获取:数据闭环及自动标注
特斯拉的数据闭环:通过影子模式搜集数据,经过清洗、标注(自动标注+人工标注),与仿真数据共同构建训练集。训练集也用于车载模型的训练,完成之后更新到车上;以此往复,完成数据流的闭环。
- 2020年起,特斯拉开始研发数据自动标注系统。
- 在车辆行驶过程中,摄像头收集的路面信息,打包上传到服务器的离线神经网络大模型,由大模型进行预测性标注,再反溃给车端各个传感器,当预测的标注结果在8个传感器均呈现一致时,则这一标注成功。
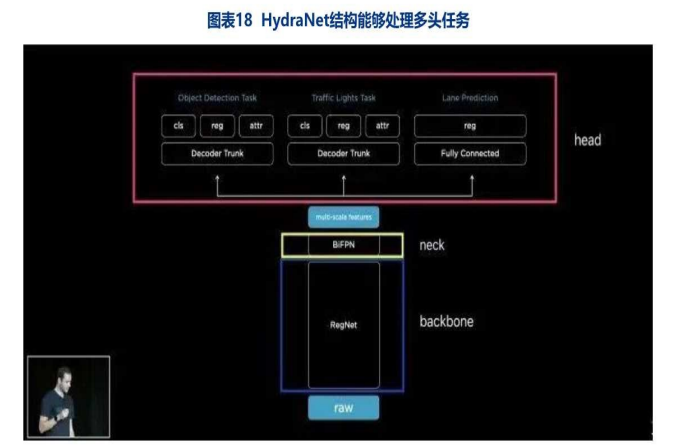
特斯拉算法引领行业:多任务学习神经网络架构HydraNet
◆背景:传统自动驾驶目标检测采用通用网络结构,当时业内自动驾驶视觉神经网络只有一个head,在同时完成多项任务方面(如车道线检测,人物检测与追踪,信号灯检测等等视觉任务)存在效率低下的问题。
◆2018年,特斯拉做出对其自动驾驶算法的第一次革新,构建HydraNet,重构自动驾驶目标检测结构。
√ HydraNet 结构能够完成多头任务,减少重复的卷积计算,提升算法效率。
特斯拉算法引领行业:BEV+Transformer
背景:传统SLAM+DL下,①融合不同传感器的采集数据,并实时输出下游所需的一系列任务结果是当时的核心挑战;②多采用后融合处理方式,每个传感器对应一个神经网络,计算量大、效率低。
2020年,特斯拉引入BEV+Transformer架构,后引入时序信息。
- 特斯拉认为采集后的2D图像需要升维才能实现自动驾驶,而升维的最佳表达方式是BEV(鸟瞰图)。因此引入大模型Transformer进行升维开发,实现将2D图像转换成BEV视角,形成车辆自身坐标系。
- BEV 使得自动驾驶从后融合(或称「决策层融合」)向特征级融合(或称「中融合」)方向迈进,提升决策精准度且降低计算量。
- 特斯拉引入时空序列特征层,为自动驾驶增添短时记忆功能,从而具有推演能力,提升系统安全性。

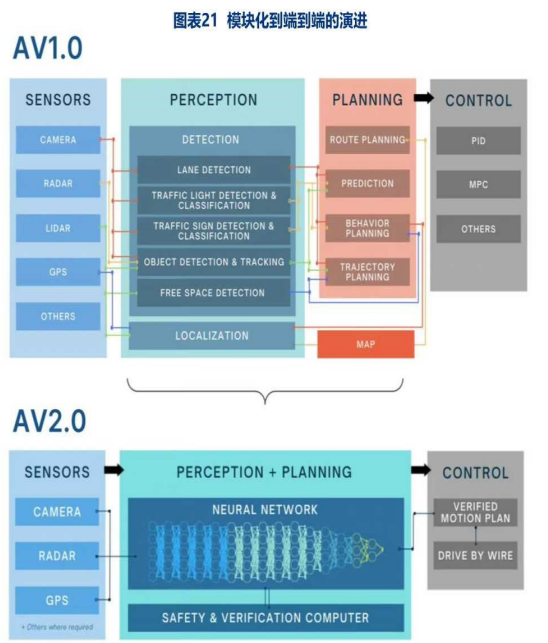
特斯拉算法引领行业:端到端
背景:传统的自动驾驶方案数据处理模块多、步骤多可能出现级联误差(前级模型输出的结果有误差,会影响下一级模型的输出)
2024年1月,特斯拉FSDv12(FSDv12.1.2)开始正式向用户推送,将城市街道驾驶堆栈升级为端到端神经网络。
- 端到端技术方案基于深度神经网络,通过摄像头采集驾驶场景的信息,将其作为深度卷积神经网络模型的输入再不断对网络模型进行训练,得到学习好的网络参数从而对智能车方向盘转角进行预测。更加接近最真实的人类驾驶。
- 端到端的主要弊端是:①模型可解释性差,工作原理是黑盒。②模型很难引入先验知识,系统不了解人类动作背后的规则。






报告共计:32页
来源:人工智能学派















 1229
1229

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









