







 本文介绍了t-SNE,一种非线性降维技术,通过将高维手写数字数据集映射到二维空间进行可视化,展示了PCA初始化在t-SNE中的应用,尽管存在默认超参数限制和数据质量影响,但依然能基本区分不同数字。
本文介绍了t-SNE,一种非线性降维技术,通过将高维手写数字数据集映射到二维空间进行可视化,展示了PCA初始化在t-SNE中的应用,尽管存在默认超参数限制和数据质量影响,但依然能基本区分不同数字。
t-SNE 的全称是 t-distributed stochastic neighbor embedding(t-分布随机领域嵌入),这是一种非线性降维技术。而 PCA 和 LDA 是线性的降维技术。
t-SNE 通常用来在二维或者三维空间中可视化复杂数据集。
简单来说,t-SNE 试图发现数据集中的样本在原始高维空间中距离的概率分布,然后再去低维空间中重建这种概率分布。我们通过 t-SNE 将高维空间中的数据点嵌入到了低维空间,同时还保留了数据点在高维空间中的距离关系。
不过 t-SNE 只能用于数据可视化,我们没法用训练集的数据去拟合一个 t-SNE 模型,然后将模型用于测试集,我们只能用整个数据集(训练集和测试集)去拟合 t-SNE 模型,然后得到数据集的低维表示,并可视化。
我们现在就以著名的手写数字数据集为例,scikit-learn 自带了该数据集。

这个数据集中包含了 1797 张手写的 0 到 9 的数字图片,每张图片都是一个 8 x 8 的灰度图,如上图所示。
我们可以将 8 x 8 的灰度图展平成长为 64 的表示样本特征的向量。
现在我们将 64 维特征投影到了 2 维空间。
你可能注意到了我们使用了 PCA 初始化 t-SNE 嵌入。而且 t-SNE 还有很多额外的超参数,我们这里都使用了 scikit-learn 提供的默认值。
现在我们就在二维空间可视化这个手写数字数据集。y_digits 只被用来在可视化时标记不同的数据点族群,并没有参与到 t-SNE 的训练中。
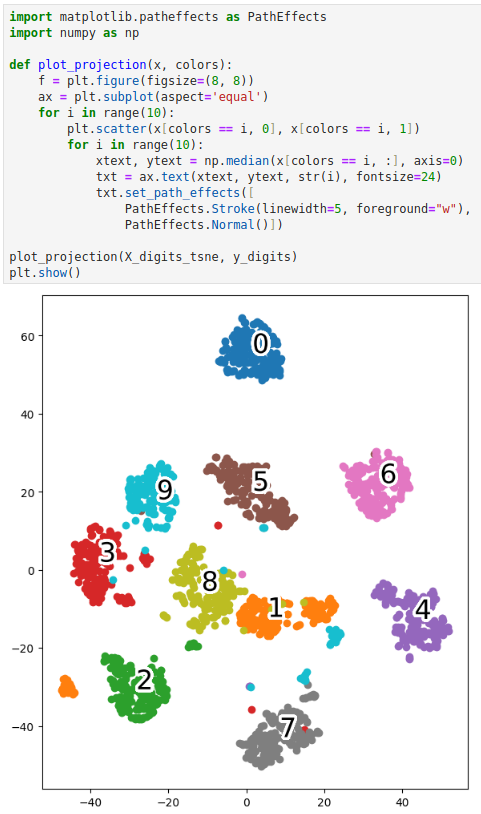
我们可以看到 t-SNE 降维后,还是能够将表示不同数字的样本区分开,但是这种区分不是很完美,部分是因为我们使用了默认的超参数,部分是因为数据集本身的问题,比如这里图像的分辨率很低,手写的 3 和手写的 8 可能很相似。

















 896
896

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









