










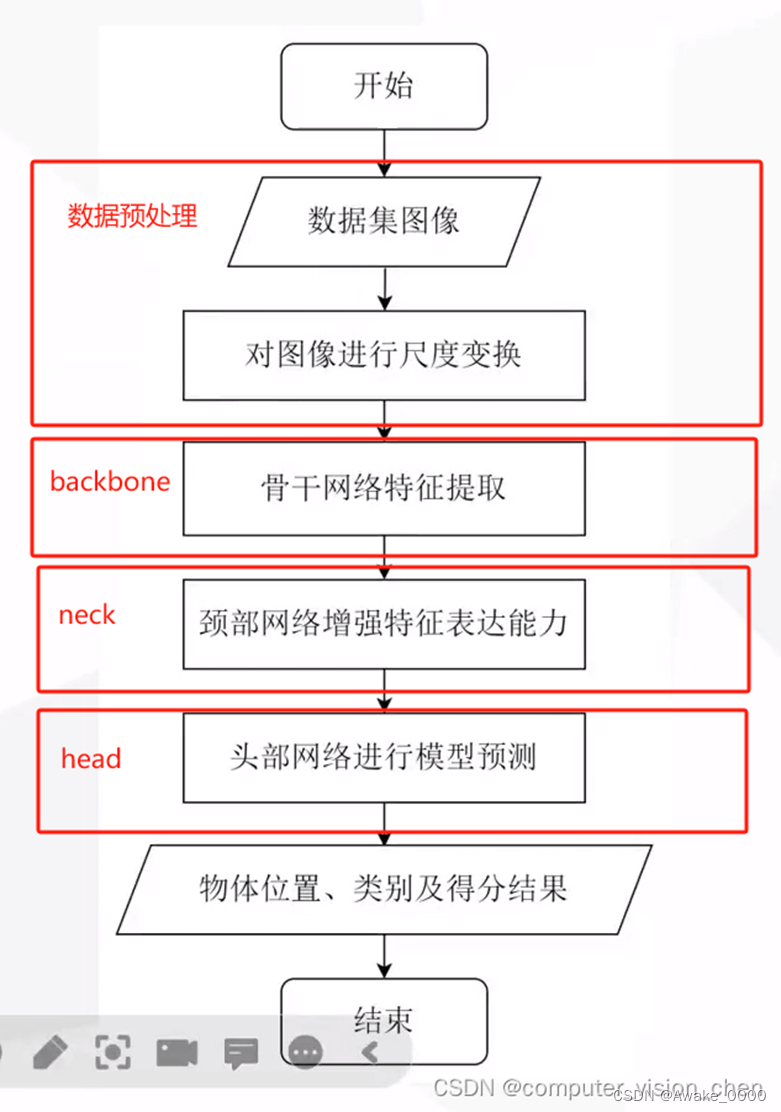
-
🍀Yolov5网络结构
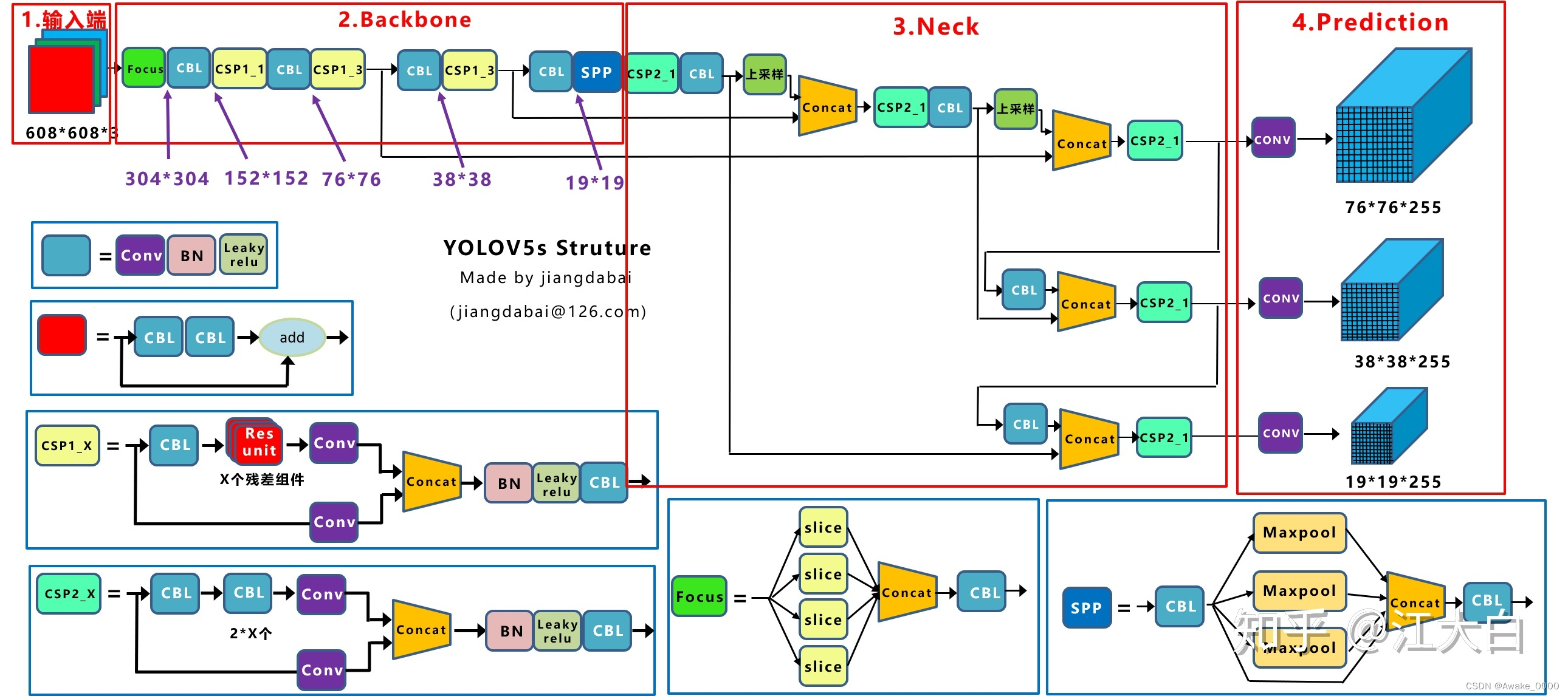
-
🦄各结构原理概念:
1.输入端:mosaic数据增强,自适应锚框计算,自适应图片缩放
Mosaic数据增强:将多张图片按一定比例组合成一张图片,在更小范围识别目标

自适应锚框计算:
yolov5针对不同的数据集,都会有预设定长宽的锚框,在训练时,以真实的边框位置相对于预设边框的偏移来构建(也就是我们打下的标签)训练样本。 这就相当于,预设边框先大致在可能的位置“框“出来目标,然后再在这些预设边框的基础上进行调整。
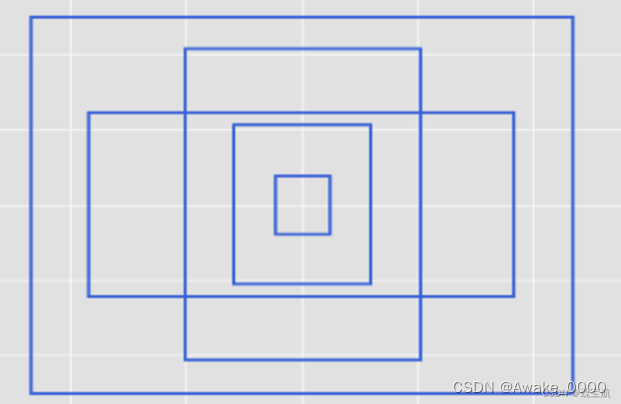
自适应图片缩放:
允许模型处理不同尺寸的输入图像,同时保持图像的比例和尽可能少的失真(该功能在模型推理阶段执行)

2.Backbone:focus结构,CSP结构,SPPF结构
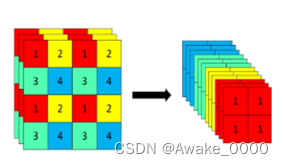
Focus结构:
对输入图片进行切片操作, 即每隔一个像素取一个值, W和H信息集中到通道空间,输入通道扩充了4倍,再进行卷积得到二倍下采样特征图(在YOLOv5-7.0版本中,Focus层可能已经被6×6卷积层所替代)
CSP结构:
将输入特征分为两个分支,并进行特定的操作来防止梯度消失, 旨在提高模型的特征表示能力,进而提升模型的准确性和泛化能力
SPPF结构:
串行堆叠多个最大池化层来实现局部特征和全局特征的融合, 能将任意大小的特征图转换为固定大小的特征向量,使模型适应不同尺寸的输入
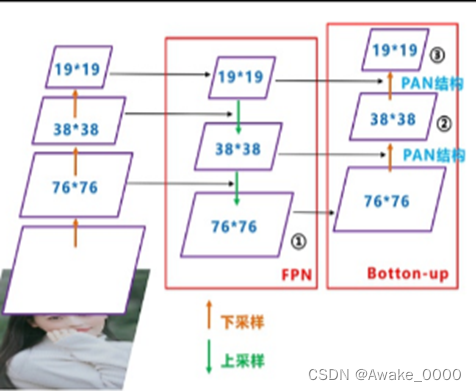
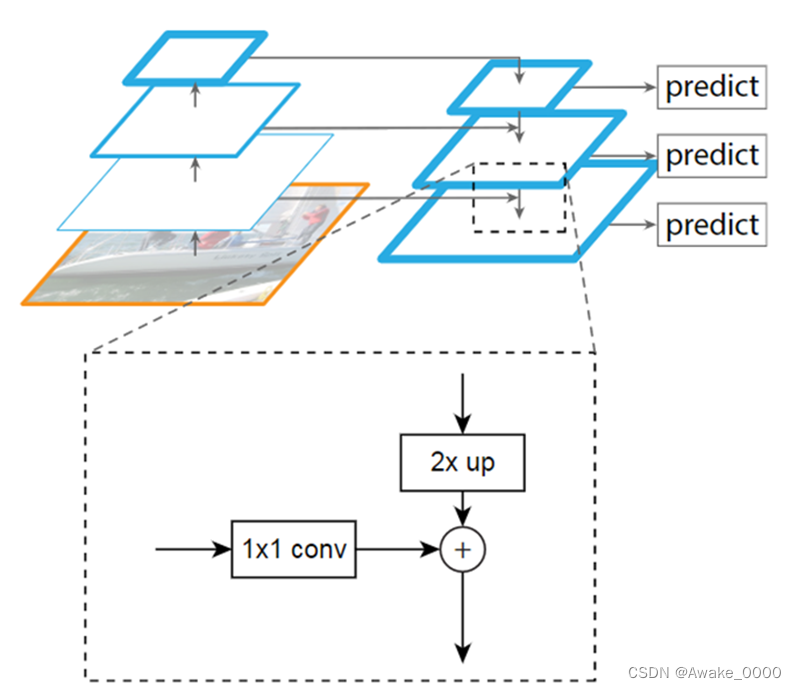
3.Neck: FPN+PAN结构
FPN结构:
自上向下的一个特征金字塔,通过自顶向下的上采样操作使得底层特征图包含更强的语义信息。
PAN结构:
自下向上的金字塔,通过自底向上的下采样操作将低层定位特征传递到高层,确保高层特征兼具语义信息和定位能力。
4.Head: Bounding box损失函数,NMS非极大值抑制
Bounding box损失函数:
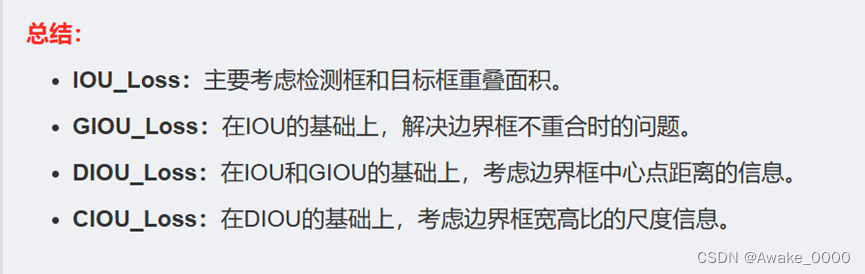
IOU是目标检测中常用的损失函数之一,它衡量的是预测框(bounding box)与真实框(ground truth box)之间的重叠程度。IOU值越大,表示预测框与真实框的重叠程度越高,损失越小。但是,当预测框与真实框没有交集时,IOU值为0,此时损失函数无法提供有效的梯度信息,导致模型无法继续学习。
IOU_Loss,GIOU_Loss,DIOU_Loss,CIOU_Loss详细区别请参考另外一位博主的博客,戳这👆
NMS非极大值抑制:
用于目标检测后处理的关键技术,其主要目的是消除冗余的检测框,保留最具代表性的检测框,从而提高目标检测的准确性和效率
👾各模块算法流程:
Mosaic数据增强(在训练阶段使用):
随机产生拼接中心点坐标:
首先,随机产生一个拼接中心点坐标,该坐标的范围通常在原始图像大小的一半到三倍之间(即img_size/2 ~ 3img_size/2)。
选择四张图像:
随机选择四张图像,并将它们依次放置在新图像的左上方、右上方、左下方和右下方。新图像的大小通常为原始图像大小的两倍(即[2×img_size, 2×img_size])。
计算并截取原始图像:
根据新图像上的坐标,计算并截取原始图像在新图像上的部分。
拼接图像:将截取后的四张原始图像贴在新图像上,形成一张新的合成图像。
调整标签位置:
根据四张原始图像在新图像上的偏移,计算并调整对应的真实标签(如边界框)在新图像上的位置。
随机变换:对新图像进行随机旋转、平移、缩放、剪切等变换,以增加数据的多样性。
调整图像大小:最后,通过resize操作将新图像的大小调整回原始图像大小(即img_size)。

Mosaic模块在utils里的datasets.py文件中(代码详细解释)
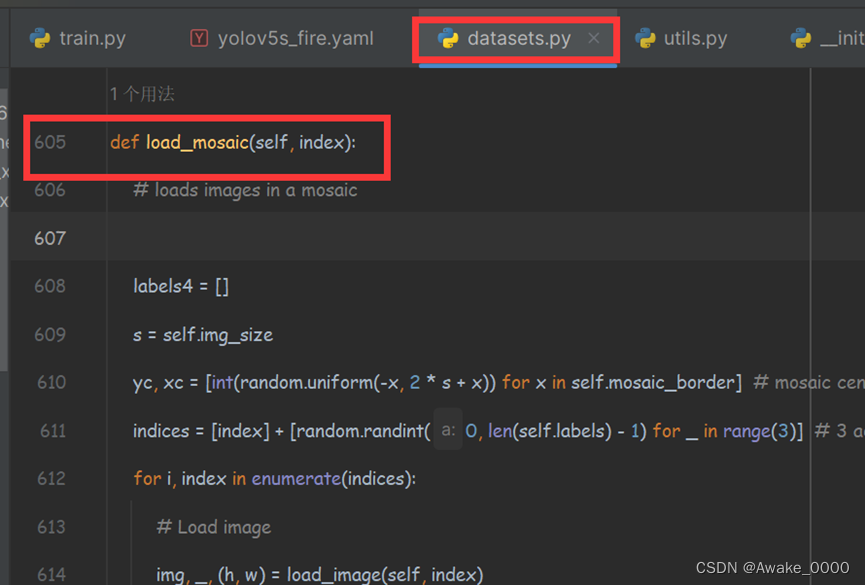
自适应锚框计算(效果不好可关闭此功能):
获取数据集目标信息:读取训练集中所有图片的w、h以及检测框的w、h
坐标转换:将读取的坐标修正为绝对坐标
K-means聚类:使用Kmeans算法对训练集中所有的检测框进行聚类,得到k个anchors
锚框变异:通过遗传算法对得到的anchors进行变异,如果变异后效果好将其保留,否则跳过
筛选边界框:将最终得到的最优anchors按照面积返回
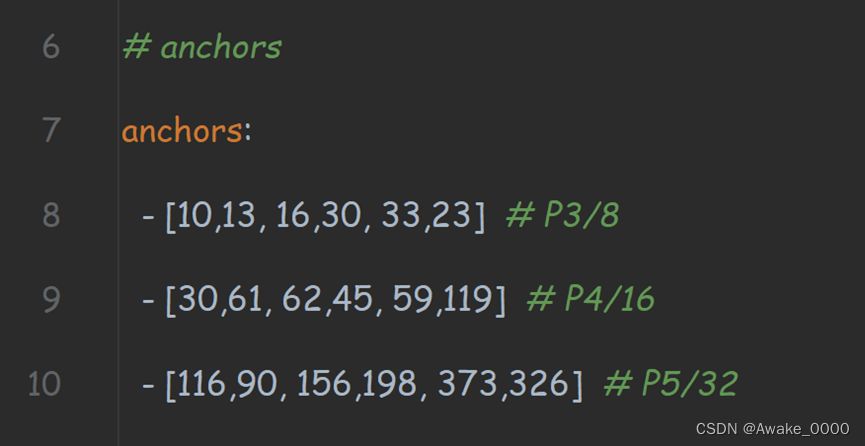
在配置文件yolov5s.yaml文件中, 这个先验框是在coco数据集上通过聚类方法得到的,第一行是在最大的特征图上的锚框,第二行是在中间的特征图上的锚框,第三行是在最小的特征图上的锚框,每一行后面的注释是特征图的大小(P3/8为当前特征图大小的3/8)详细解释点击
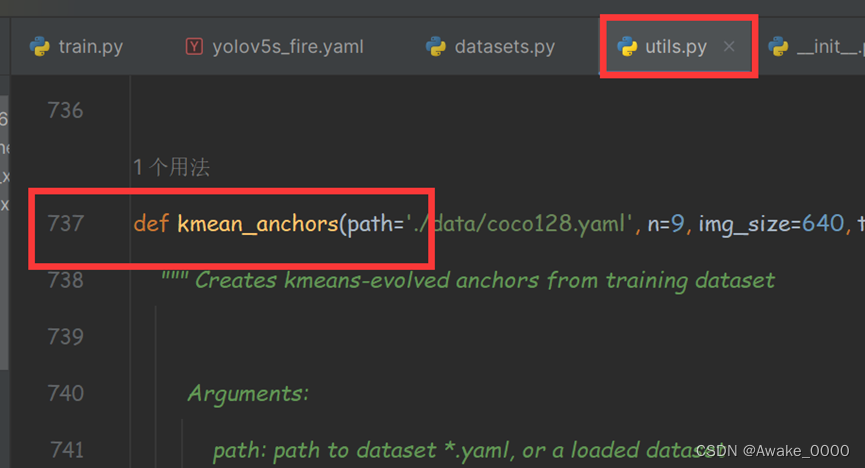
Kmean_anchors模块在utils里的utils.py文件中(代码详细解释)
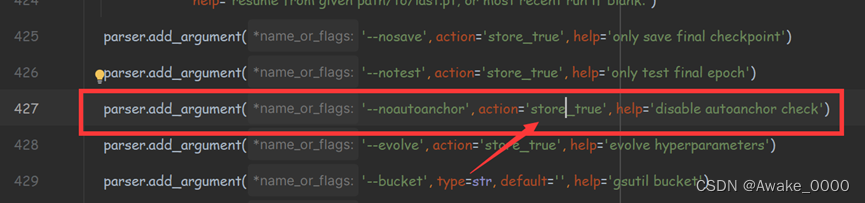
PS:如果觉得计算的锚框效果不是很好,也可以在train.py中将自动计算锚框功能关闭。
自适应图片缩放(在常用的目标检测算法中):
计算缩放比:根据原始图片的长宽和输入网络图片的长宽,计算出一个缩放比例。这个比例取的是长宽方向上变化范围最小的一个,以确保图片在缩放后不会失真过多。
计算缩放后图片的长宽:使用计算出的缩放比例,对原始图片的长宽进行缩放。
计算填充像素:根据输入网络图片的要求和缩放后的图片尺寸,计算出需要填充的像素值。这些像素值被填充到图片的相应边上,以确保图片的长宽满足模型的输入要求。详细举例
letterbox模块在utils里的datasets.py文件中(代码详细解释)
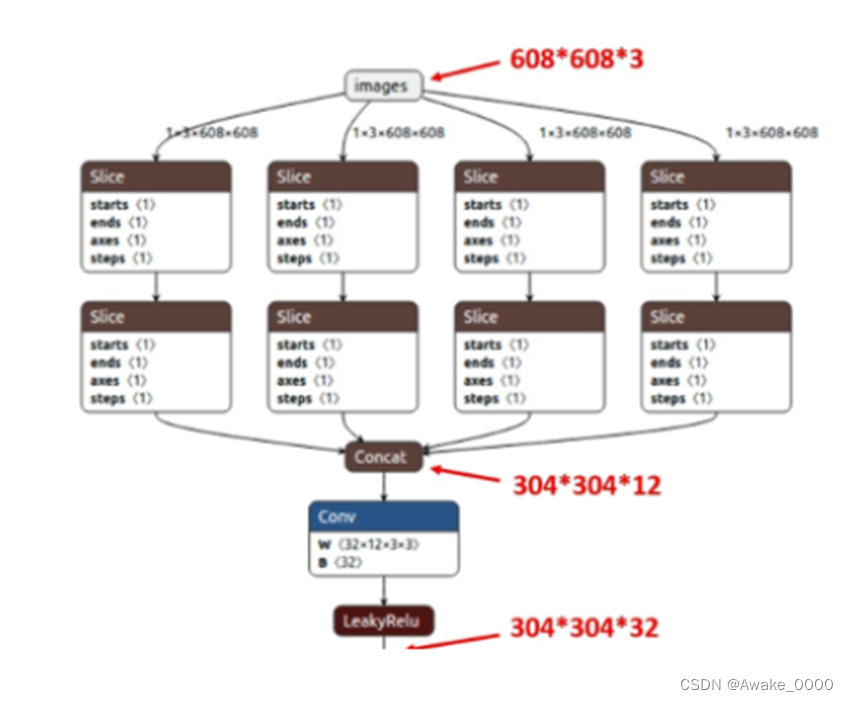
Focus结构(位于图片进入backbone之前):
1.Focus结构会采用切片(slice)操作,将高分辨率的图片(特征图)拆分成多个低分辨率的图片/特征图。这一操作类似于隔列采样+拼接,即将图片中的像素每隔一个取一个值,形成四张互补的子图片。
2.切片操作后,四张图片在通道维度上进行拼接(concat),将W、H信息集中到了通道空间,输入通道扩充了4倍。例如,原始的608 × 608 × 3的图像输入Focus结构后,会先变成304 × 304 × 12的特征图。
3.接下来,经过一次卷积操作(通常是3×3卷积conv),最终得到没有信息丢失情况下的二倍下采样特征图。例如,304 × 304 × 12的特征图经过卷积后,最终变成304 × 304 × 32(或64,取决于具体的网络配置)的特征图。
focus模块在utils里的common.py文件中(代码详细解释)
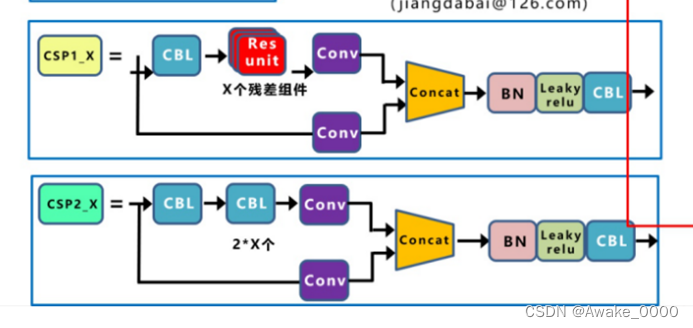
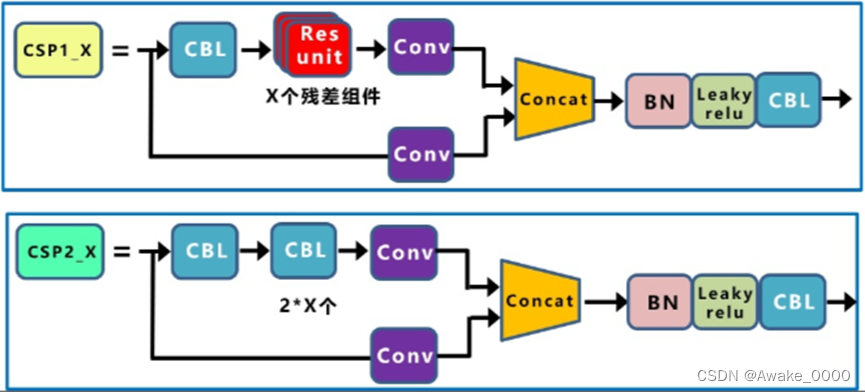
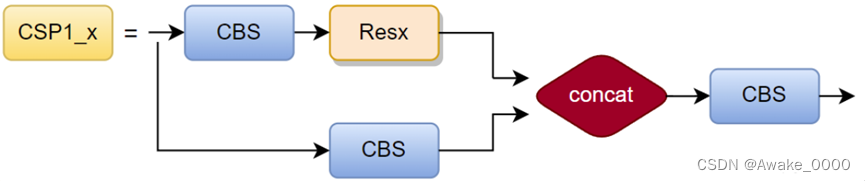
CSP结构(yolov5有两种结构)
CSP结构将原始输入分为两分支:
一分支经卷积减通道数后通过多个残差结构,另一分支直接卷积。
两分支结果连接(concat),保持BottleneckCSP输入输出大小一致。
YOLOv5有两种CSP结构:CSP1_X用于Backbone,CSP2_X用于Neck。
两者区别在于是否使用shortcut(由BottleneckCSP的shortcut参数控制),其中残差组件由两个CBL组成。
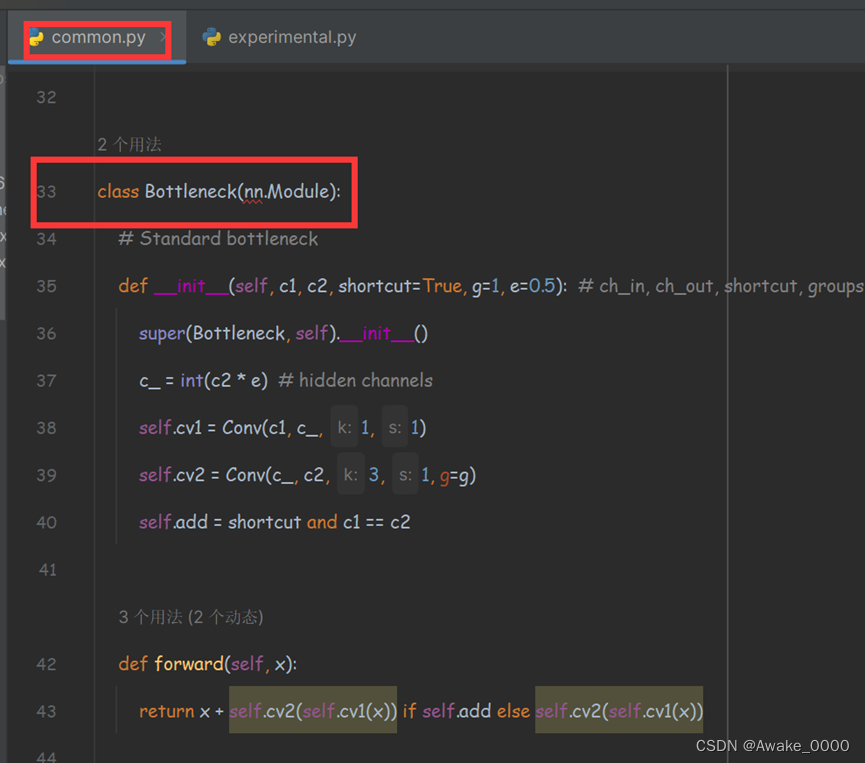
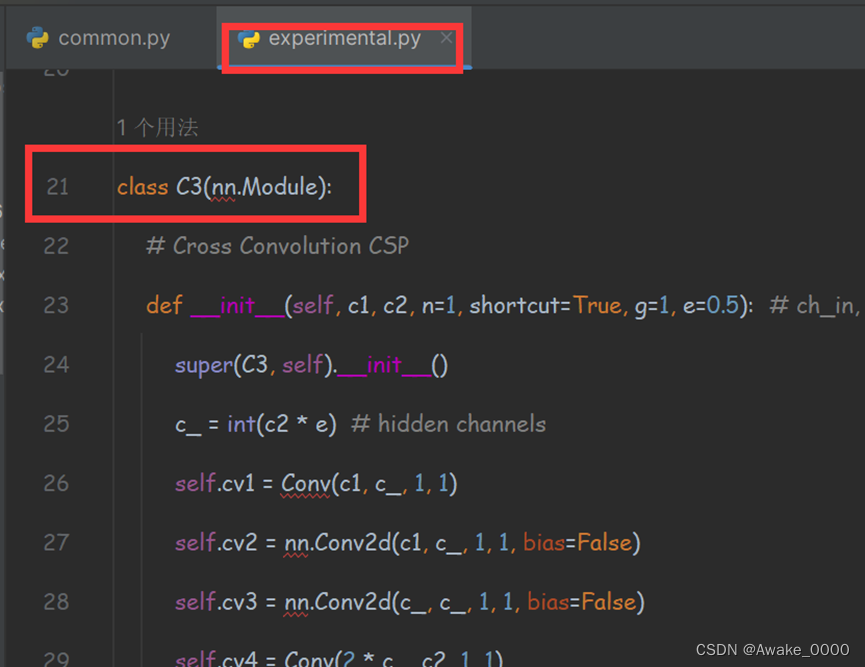
注: 在YOLOv5 v4.0中,BottleneckCSP模块被C3模块取代,移除了残差输出后的Conv模块。C3包含3个标准卷积层和多个Bottleneck模块,其数量由配置文件参数决定。此外,C3中的激活函数从LeakyReLU变为SiLU
CSP模块代码在models下的common.py文件中, C3模块代码在models下的experimental.py文件中(代码解释)
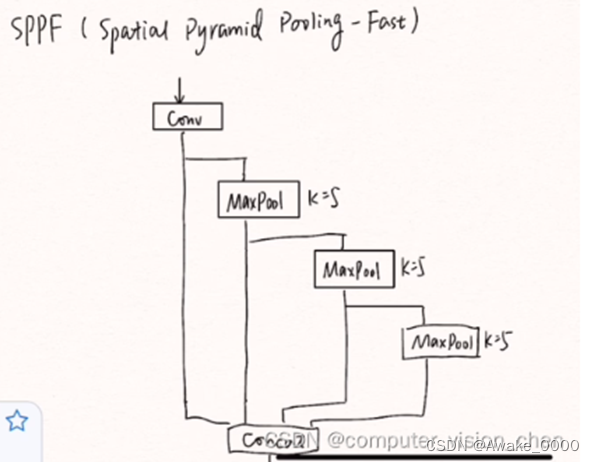
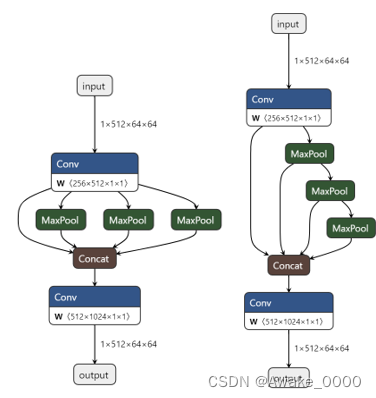
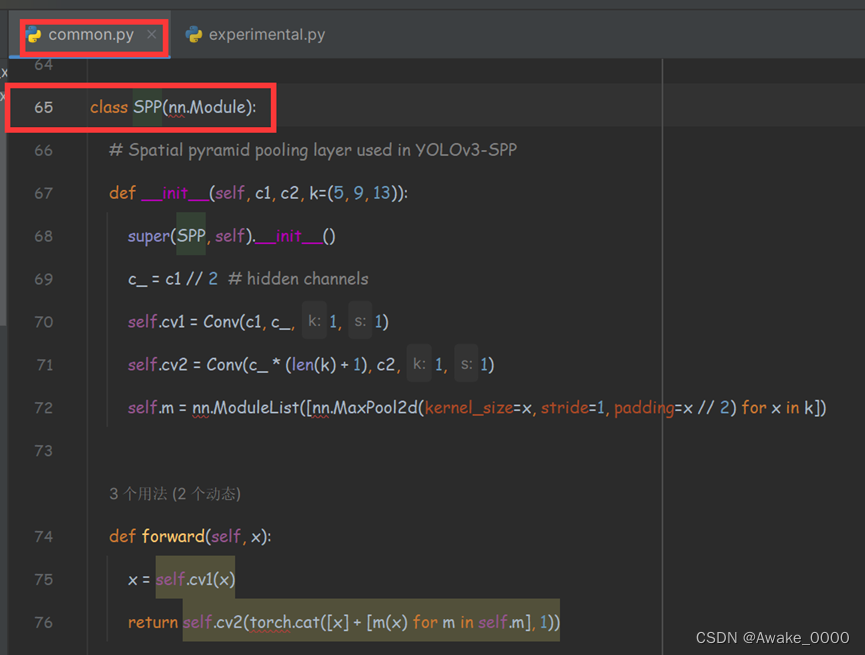
SPPF结构
对输入特征图进行一次卷积(Conv)操作以进行特征压缩,然后经过三次串行的一模一样的最大池化操作。这三次最大池化(MaxPool2d)串行使用了不同大小(如5x5、9x9、13x13)的最大池化层,效果等效于SPP并行使用, 只是在结构上略有差异, 模型计算量变小了很多,模型速度提升。(左图为SPP右图为SPPF)
SPP/SPPF模块代码在models下的common.py文件中(代码解释)
FPN结构
FPN的输入是Backbone部分输出的不同尺度的特征图,然后通过上采样(自顶向下)、卷积等操作,将高层特征图与低层特征图进行融合,得到新的特征图。这些新的特征图将作为后续PAN结构的输入
PAN结构
PAN通过从低层到高层的特征传递,将低层特征的细节信息融入到高层特征中,使得高层特征在保持丰富语义信息的同时,也具备更强的空间信息。
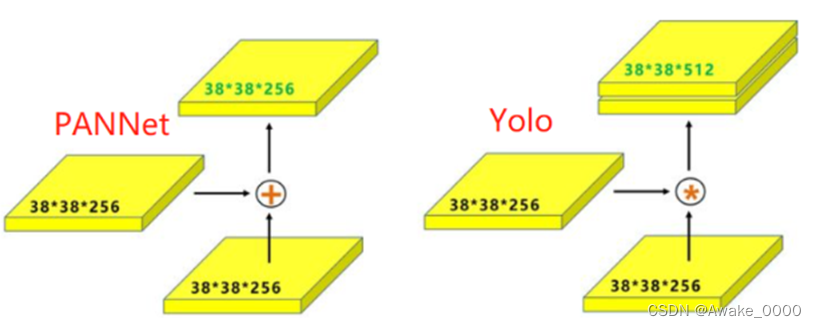
在YOLOv5中,PAN的实现方式与原始论文中的描述类似,但可能结合了CS等结构进行改进。CSP结构通过分块卷积和特征融合的方式,进一步提高了特征图的表达能力和模型的性能。
PS:原本的PANet网络的PAN结构中,两个特征图结合是采用shortcut操作,而Yolov4/5中则采用concat操作,特征图融合后的尺寸发生了变化。
Bounding box损失函数
损失函数的组成:
YOLOv5采用CIOU Loss进行边界框回归,该损失函数综合考量了预测框与真实框的重叠度、中心点距离和长宽比一致性。
IOU(Intersection over Union):
IOU是计算两个边界框交集与并集之比的值,用于衡量两个边界框的重叠程度。
公式:(IOU = \frac{交集面积}{并集面积})
CIOU Loss:
CIOU Loss在IOU Loss的基础上,增加了两个边界框中心点之间距离和长宽比一致性的考量。
公式:(L_{CIOU} = 1 - IOU + \frac{\rho^{2}(b, b^{gt})}{c^{2}} + \alpha v)
其中,(\rho{2}(b, b{gt})) 是预测框和真实框中心点之间的欧氏距离的平方。
(c^{2}) 是预测框和真实框最小外接矩形的对角线长度的平方。
(\alpha) 和 (v) 是用于平衡不同损失项的权重和因子。
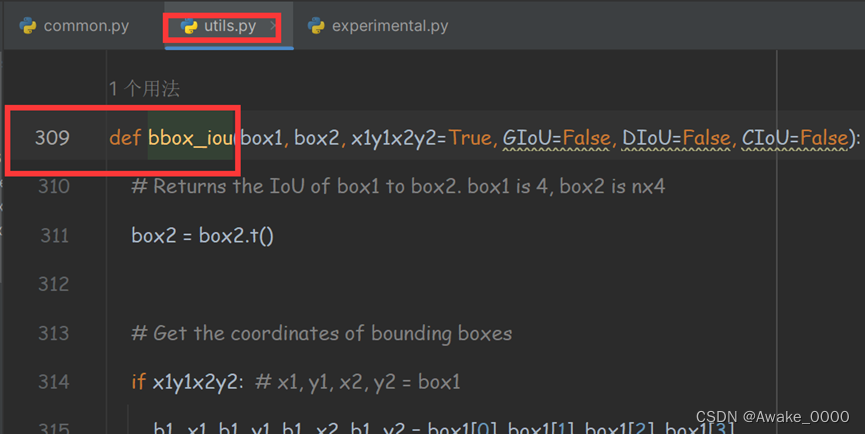
Yolov5中的IOU/GIOU/DIOU/CIOU模块代码在utils下的utils.py文件中
NMS非极大值抑制
分组与排序:
在YOLOv5模型中,预测框首先按类别分组,然后在每个类别内按置信度排序,最高置信度的框排在最前。
选取最高得分框:
在每个类别中,选择置信度得分最高的预测框作为基准框(reference box)。
计算交并比(IOU):
遍历剩余的预测框,计算它们与基准框的交并比(Intersection over Union, IOU)。
IOU是一个衡量两个预测框重叠程度的指标,其值介于0到1之间,值越大表示重叠程度越高。
抑制非极大值:
若IOU超过阈值(如0.5),则删除该预测框。保留最高置信度的基准框,并返回第一步继续处理剩余预测框直至全部处理完。
🥸代码讲解
Data里面有获取数据的.sh脚本和coco的数据集, coco128指的是从coco数据集中取出128张用于测试
models中的yaml指的是4个模型的配置文件, yolo.py指的是把模型翻译成模型的一些接口。common放的是一些网络结构的定义
runs是我们训练运行的时候的一些输出文件。每一次运行就会生成一个exp的文件夹
utils这个里面主要是放的一些脚本信息,比如mosaic数据增强等。
Weight是放模型权重文件的, yolov5.pt指的是预训练模型
detect.py是负责推理的文件,train.py 是训练的文件
在models里的配置文件yaml中,以yolov5s为例:
depth_multiple是模型深度倍数, width_multiple是通道倍数, 这个80是coco数据集的类别数量
# parameters
nc: 80 # number of classes这个80是coco数据集的类别数量
depth_multiple: 0.33 # model depth multiple模型深度倍数
width_multiple: 0.50 # layer channel multiple通道倍数
Anchors先验框
# anchors先验框
anchors:
- [10,13, 16,30, 33,23] # P3/8
- [30,61, 62,45, 59,119] # P4/16
- [116,90, 156,198, 373,326] # P5/32
Backbone配置文件:每一行代表yolo网络的每一层
-1表示上一层开始; number为模块数量(会和上面的深度倍数相乘后取整); module模块名; args输入参数;
经过第一层focus变为原图的1/2
第2层Conv卷积层中,128为该层输出通道数(和上面的通道倍数相乘), 卷积核大小为3*3,步长为2,经过该层后会变为原图的1/4,后面以此类推
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, BottleneckCSP, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, BottleneckCSP, [256]], #4 输出
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, BottleneckCSP, [512]], #6 输出
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
[-1, 3, BottleneckCSP, [1024, False]], # 9
]
head网络结构:
head包括两个部分,一个部分是Neck,一个部分是 Detect部分。
第11层中,Upsample为上采样, 不改变通道数,特征图的长和宽会增加一倍;
第12层的Concat中, [-1,6]表示有上层的和第6层的输出进行特征融合,增强语义
第19层中, 开始下采样,将上一层和第14层的输出进行特征融合,增强定位
最后一层detect层中,对第17,20,23层的输出进行检测
head:
[[-1, 1, Conv, [512, 1, 1]], #10
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 6], 1, Concat, [1]], # cat backbone P4
[-1, 3, BottleneckCSP, [512, False]], # 13
[-1, 1, Conv, [256, 1, 1]],
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 4], 1, Concat, [1]], # cat backbone P3
[-1, 3, BottleneckCSP, [256, False]], # 17
[-1, 1, Conv, [256, 3, 2]],
[[-1, 14], 1, Concat, [1]], # cat head P4
[-1, 3, BottleneckCSP, [512, False]], # 20
[-1, 1, Conv, [512, 3, 2]],
[[-1, 10], 1, Concat, [1]], # cat head P5
[-1, 3, BottleneckCSP, [1024, False]], # 23
[[17, 20, 23], 1, Detect, [nc, anchors]], # Detect(P3, P4, P5)
]
- 还有一些模块代码请参考下面的博客:
Yolov5代码解析(输入端、BackBone、Neck、输出端)) - 湾仔码农 - 博客园 (cnblogs.com)
*代码解释参考的CSDN的博客:
整篇文章还参考了
【YOLO系列】YOLOv5超详细解读(源码详解+入门实践+改进)-CSDN博客
YOLOv5网络模型的结构原理讲解(全)_yolov5网络结构详解-CSDN博客
最后,
这篇文章是我自己在网上查找资料并学习写的笔记,有些地方会有不正确的地方,所以仅供参考,错误的地方可以私信我对我指出,谢谢你!😁🍀
















 6667
6667











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









