






-
在深度学习的激活函数中,使用ReLu比Sigmoid的优势有哪些呢?
我知道用ReLu一般会比其他激活函数运算速度快一些,而且ReLu比Sigmoid更接近生物学中的激活模型,还有其他的优势么?(或者用Sigmoid有哪些劣势呢?)
答案:
ReLu另外的优势在于其稀疏度(Sparsity)和较小概率产生梯度消失(Vanishing Gradient)的问题,我们首先来看下其定义:
h=max(0,a)
a=Wx+b
然后是Sigmoid的定义:
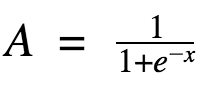
刚才我提到了ReLu的一个优势就是减少梯度消失(Vanishing Gradient),当a>0时,梯度(Gradient)是一个常量, 但是对于Sigmoid而言,当x的绝对值增加时,梯度就会变得越来越小;而且梯度常量化会使学习过程变快。
ReLu的另一个优势是稀疏度(Sparsity),因为当a<=0时,输出总是0, 每一层的神经元越多,结果就会越稀疏;另一方面Sigmoid总是会产生非零值,从而生成稠密表示(Dense Representations)。 稀疏表示(Sparse Representations )是学习变得更简单和快捷。
问题出处:https://dataquestion.com/question/6021-2
2. 机器学习的算法那么多,总的来说,在选择的时候有没有什么大方向上的指导原则呢?
首先要明确你要清楚你的数据是什么样的,然后你想通过这些数据解决怎样的问题。
如果你想预测某个类别:
-
训练数据集有标记好的预期输出(类别):选择分类(Classification) 算法
-
训练数据集没有标记好的预期输出(类别):选择聚类(Clustering) 算法
如果你想预测数量:
-
选择回归(Regression) 算法
其他目的的话可以考虑降维(Dimensionality Reduction)算法等
上面是帮助你确定算法的大类,如果你确定了算法的大类, 一般来说会把这类的主流算法都跑一边看下结果如何,在根据评估各个模型的不同误差和交叉检验(Cross Validation) 去选择最适合的模型,不过具体的情况也要具体分析,在实际情况下还有其他因素要考虑,比如:
1. 准确度 vs 可解释度
在实际应用中模型并不是越精确越好,尤其是在工作中,你要考虑到如何给你的同事,上司甚至是客户解释这个模型是如何运作的,你需要达到一定的准确度即可,这种情况下越是简单易懂的模型(比如线性回归,决策树等)越好,因为即使你用了很复杂的黑箱算法(如神经网络)得到了很高的准确度,但是别人不理解这个模型是怎么运作的也不太会采用。
2. 准确度 vs 区分度
在分类问题中有些时候准确度并不是一个很好的衡量模型的指标,因为我们有时候往往只关心模型能否分辨出特定的某一类而不太关心其他类别(比如检测癌症和机场安检的检测危险物品)这时就要用到混淆矩阵(Confusion Matrix), 去看模型对每个类别的区分度如何,这时候特定类别的precison和recall才是关键的指标
其他的还有数据量的大小(因为有些算法没有很好的scalability,不能用在大数据上面),运行的速度(对于某些Real-time的模型很关键), Bias-Variance trade off等等,这些都会影响到模型的选择。
目前想到这么多,欢迎数问里的大牛们继续补充。
最后附上一张Sklearn 的cheatsheet:

问题出处:https://dataquestion.com/question/6174
3. False Positive和 False Negative对应解决什么问题呢?
首先,你需要搞懂FP和FN分别都是什么意思
FP就只指预测是Positive的,实际是Negative;FN同理。
FP更重要的情况:
当公司只有有限预算的情况下,决定Campaign 发布还是不发布。在这个情况,公司希望尽可能的只选出“一定有效果的”Campaign,选错一个,可能就血本无归。这种情况下,我们就希望FP尽量小,甚至为0,意为只选出来一定的,宁可错过某些可能有意想不到的Campaign
FN更重要的情况:
最常见就是肿瘤的检测了。肿瘤之所以一直是医学中的疑难杂症是因为很难被提前足够的时间检测出来,如果能在肿瘤细胞刚刚扩散的时候就被检测出来,肿瘤就那么回事吧~~所以在这种情况下,容错率是很低的,我们宁可把不带有肿瘤细胞的人错误判定为肿瘤,也要把所有有可能带有肿瘤细胞的人找出来。这种情况,我们希望找出所有True Positive(阳性),也是我们常说的“宁可错杀一千,不可放过一个”;
希望能帮到你
问题出处:https://dataquestion.com/question/5961-2
4. 检测模型结果的时候,除了最常用的MSE,RMSE,Accuracy,AUC等,还有什么吗?
先做一个小小的归纳吧
回归问题:均方误差MSE(mean squared error), 标准误差RMSE (root mean squared error), 绝对平均误差MAE (mean absolute error), 加权平均绝对误差WMAE(weighted mean absolute error), 均方根对数误差RMSLE (root mean squared logarithmic error)…
分类问题: 召回率recall, AUC, 精准率accuracy, 错误分类错误misclassification error,卡帕 Cohen’s Kappa…
接下来我一一做下解释(包括计算和应用的区别)
回归问题
MSE和MAE适用于误差相对明显的时候,大的误差也有比较高的权重,RMSE则是针对误差不是很明显的时候;MAE是一个线性的指标,所有个体差异在平均值上均等加权,所以它更加凸显出异常值,相比MSE;
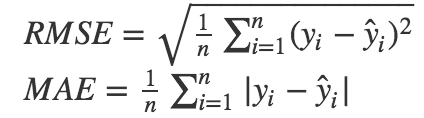
RMSLE: 主要针对数据集中有一个特别大的异常值,这种情况下,data会被skew,RMSE会被明显拉大,这时候就需要先对数据log下,再求RMSE,这个过程就是RMSLE。对低估值(under-predicted)的判罚明显多于估值过高(over-predicted)的情况(RMSE则相反)
提示:在它公式中,p指预测值,a指实际值
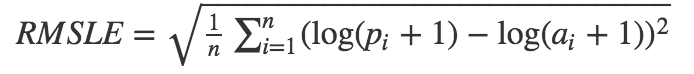
分类问题
召回率Recall(Sensitivity, True positive rate),当False Negative小的时候,召回率大。对样本不均匀的数据集特别敏感
精确率Precision(Positive Predictive Rate), 当False Positive小的时候,准确率高。同样对样本不均匀情况特别敏感
特异率Specificity(True Negative Rate), 当False Positive小的时候,特异率高。同样对样本不均匀情况敏感
准确率Accuracy,当FN和FP低的时候,准确率高。对样本不均匀情况敏感
ROC(Receiver Operating Characteristic)/AUC(Area Under Curve)ROC是专门用来说明二元分类器表现的图。跟上面几个率不同,ROC在样本不均匀的时候也能很好的说明结果
F1 score: precision*recall/(precision+recall)
AUC是指在ROC下面区域的面积,最完美的时候,AUC=1,既100%的召回率和100%的特异率
上面的解释只是个人见解,还有不全面的地方,希望大家也发表下!
问题出处:https://dataquestion.com/question/5890-2
5. 请问正则化(Regularization)具体是做什么呢?在训练模型的时候起到什么作用?
正则化(Regularization)常用的有L1(Lasso)和L2(Ridge)两者都是通过降低模型的复杂度(Complexitiy)来消除过拟合(Overfitting)这种现象。本质上,两者都是在回归模型的Loss function(损失方程)中加入了正则后解决最小化误差问题,用到的都是一种叫收缩的方法(Shrinkage)。所以也有regularization = shrinkage这种说法。
岭回归(Ridge Regression)是先于套索回归(Lasso Regression)之前提出来的,一开始是为了解决多重共线性(Multicolinearity),但是呢,岭回归并不能起到feature selection 的作用,每个变量的coefficient只能无限接近0,不能等于0。通过L2正则,调整lambda,每个特征的重要性会被打散,对target的影响变小,variance会减小,bias增加从而提供模型的准确度。
咱们来看看岭回归的公式:

公式可以分成两部分,前面一部分就是loss function了,也叫cost function,也是求最小二乘法的公式,在最小二乘法后面加上lambda*coefficient^2就能使coefficient往0缩小,为啥呢?
因为岭回归的方法有个约束条件,(在别的地方盗得截图)
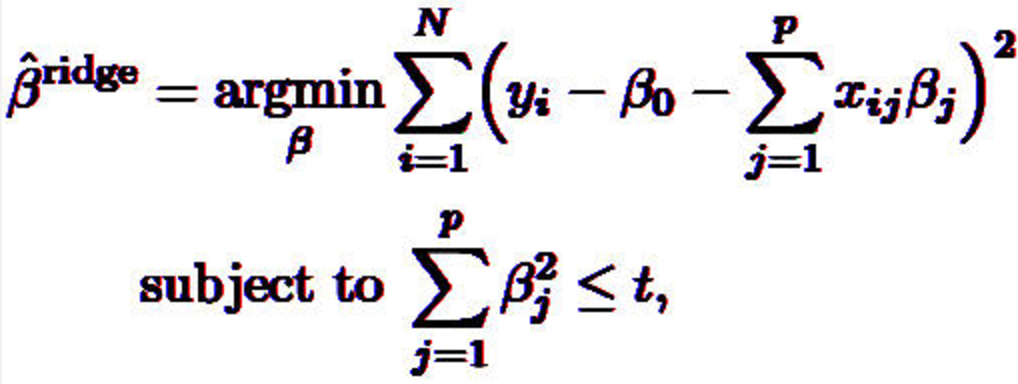
coefficient^2<=t?
咱们把lambda*coefficient^2 = k, 这时候左右换一下,coefficient^2 = k/lambda
这里k/lambda = t,也就是说lambda越大,coefficient^2越小,coefficient就越小了
套索回归(Lasso Regression)在岭回归的基础上加入了feature selection的功能,所以coefficient是可以缩小到等于0,当然公式也是跟岭回归有所不同。
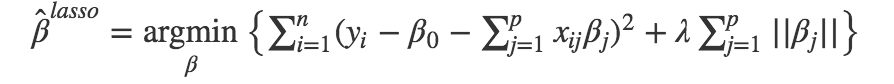
咱们再来看一个岭回归的几何解释图
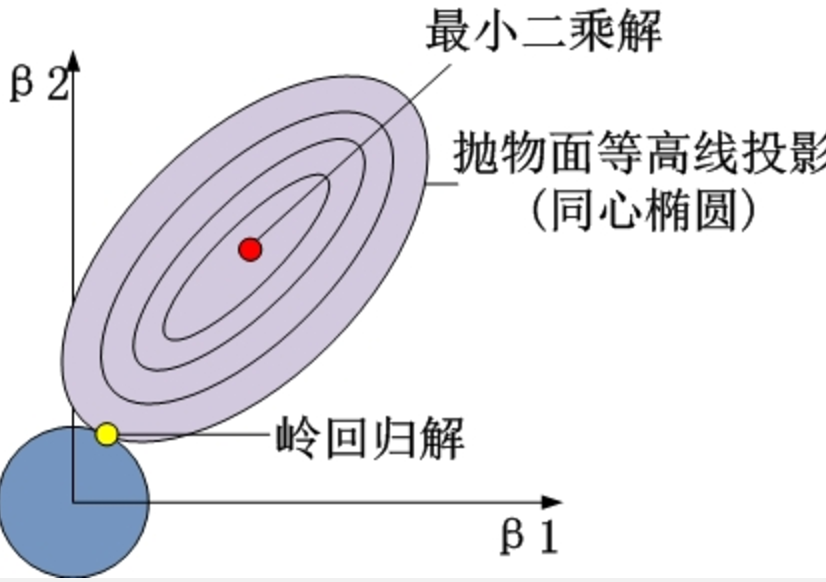
套索回归的图就是把圆变成正方形,这样子对于为什么套索回归可以把coefficient降为0这个问题就显得比较直观了,因为横平竖直的东西稀疏性更大。
而其实岭回归也可以让coefficient降为0,不过需要在lambda无限大的时候。
希望能帮到您!
问题出处:https://dataquestion.com/question/5903-2
更多优秀数据科学问题及解答请访问数问-数据科学社区:https://dataquestion.com/















 1859
1859

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









