








断断续续接触机器学习也差不多有1年多的时间了,论文看了一些,教程也看了一些,也动手写过一些东西,自认略微优点心得吧(大牛莫笑)
之前写的也很零散,所以这次就当做总结吧,也算是给自己的一个参考!
写的很浅显,主要追求通俗易懂,当然也是我的水平有限,目标就是做最好的入门资料[捂脸],有问题欢迎讨论!
声明:本专栏是在参考了网上众多资料和大牛的博客下整理收录的,如有侵权请联系作者删除,谢谢!
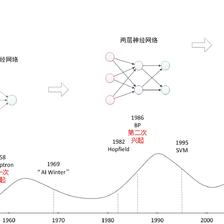
发展历史
这个已经有大牛写的很好了,参考这篇ML发展历史
ML的分类
按照是否存在监督,可划分成两类:
有监督的(supervised learning)
无监督的(unsupervisied learning)
按照学习方式的不同可以分为:
有监督的(除强化学习外)
无监督的
强化学习(reinforce learning)
按照具体的使用场景主要可以分为两类:
分类(classification)
回归(regression)
使用过程中我们都是按照具体的要求来进行,主要就是classification和regression,所以下面按照使用场景来说下
几个场景
基本上ML有如下几个场景:
- classification(example: SVM,KNN,CNN)
- regression(example: linear regression)
- clustering(example: k-means)
- dimensionality reduction(example: PCA)
- model selection(example: grid search,cross validation)
- preprocessing(example: standardization,variance scaling)
说到这,恐怕没有接触过ML的还是不知道我在说什么,下面就给大家先入为主的印象吧!
classification
大白话就是:给你一个目标预测此目标是属于哪一类的东西
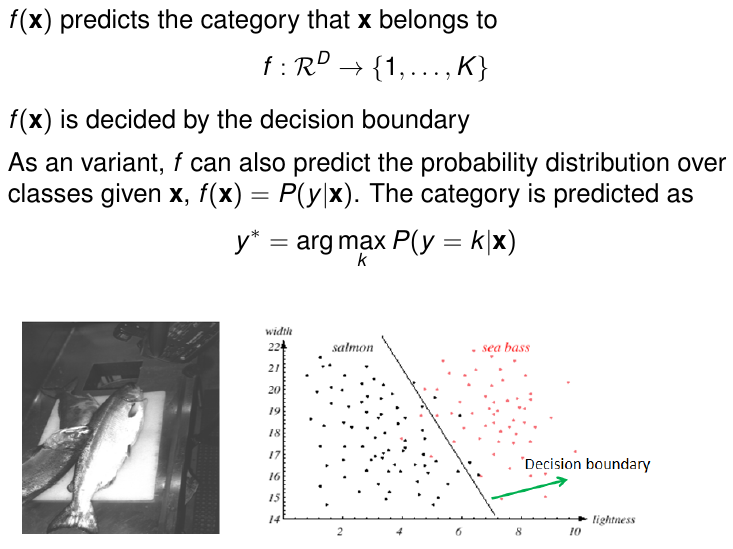
实质就是预测x属于每一类的概率P(y|x),概率最大的y即为x的类别(label)
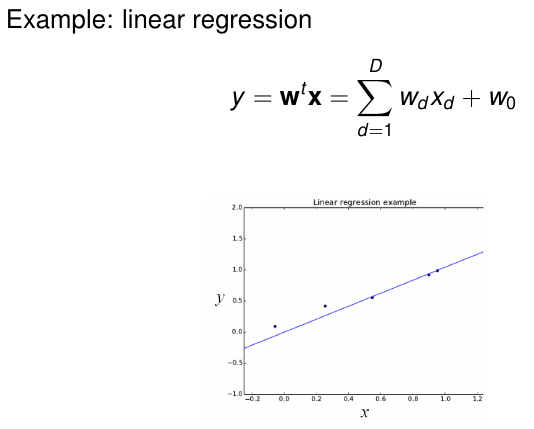
regression
通过不同的regression function来预测下个key的value是多少

比如说最简单的线性回归(linear regression):
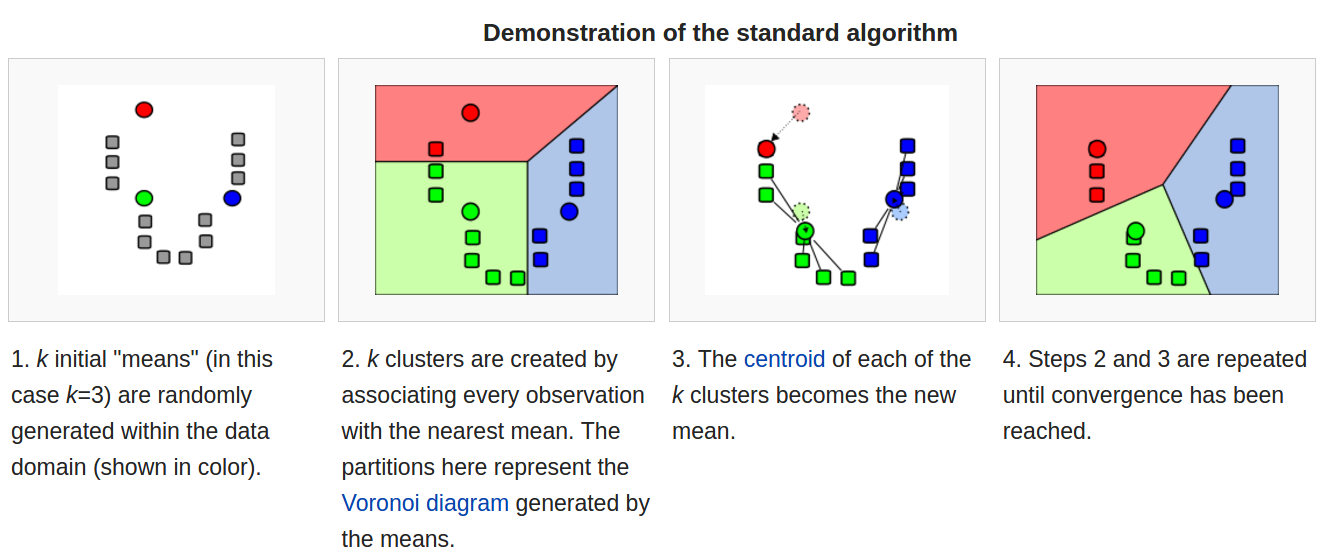
clustering
主要的作用是:将某种规则下属于一类的物体归为一类,也就是聚类,典型的应用是k-means,比如下图:
dimensionality reduction
中文叫做降维,顾名思义就是用来降低数据的维度的,减少运算量. 在ML中往往由于输入数据维度过大,导致时间复杂度很高.但是输入数据往往是包含很多无用的信息的,一个想法就是:提取有用的信息,丢弃无用的或者贡献度较低的信息,来实现降维度的目的.
典型应用是主成分分析(principle component analysis),使用PCA可以把原本的维度大大降低,减小了运算成本
model selection
ML中经常遇到的就是有多个模型,如何选择模型,这需要一个科学的方法去得出数据(而不是人工的方式)来进行选择.
典型应用是交叉验证(cross validation),大致就是将数据集划分为不同的多个部分,使用其中的某些数据去训练模型,剩下的去验证这个模型的精度,可以进行比较科学的model selection.
preprocessing
往往我们直接拿到的原始数据是不能用在ML上的,在某些场景下可能需要进行预处理(preprocessing),比如:图像的去噪,数据的归一化等等.
这个需要视具体的任务和数据而定
先写到这,下篇继续















 256
256

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









