







这两天在看CS231n的课程笔记,结合着原版英文和知乎上中文版翻译在看,确实Andrej Karpathy写的很棒,很多都是些实践经验不仅仅是理论知识. 我结合着自己的理解和Karpathy的介绍,重新看确实又收获了不少,以前觉得不明白的地方现在也清晰了,所以重新写这个再看篇,仅供参考
CNN的组成
- convolution layer
- pooling layer
- fc layer
- Batch Normalization layer
基础的三大部件(卷积, 池化, 全连接),最近两年Residual learning的流行导致大量的用到Batch Norm layer,此外还有像激活函数(Relu, PRelu, tanh等), LRU等.
我的工作中大量使用到的是Kaiming等人提出的Residual的形式,现今直接stack三大部件是很少见的,因为会出现像梯度消失等的问题. 不了解的直接去看相关的论文吧,推荐两篇:
(1) Residual Learning
(2) Wide Residual
基本的实现就是Residual Block.
细说卷积
卷积是CNN的重心,也是这篇博客的重点.
CNN的卖点
我的个人理解是两个卖点:
- 局部连接
- 参数共享
局部连接
对待像图像这样的高维数据,直接让神经元与前一层的所有神经元进行全连接是不现实的,这样做的害处显而易见: 参数过多,根本无法计算.
所以我们让每个神经元只与输入数据的一个局部区域连接,这个局部区域的大小就是局部感受野(receptive field),尺寸上等同于filter的空间尺寸(比如5*5*3).
为何说局部连接是CNN的卖点呢?通过局部连接的方式避免了参数的爆炸式增长(对比全连接的方式). 通过下面的参数共享可以大大的缩减实际的参数量,为训练一个多层的CNN提供了可能.
参数共享
这里直接上案例,来的更加直观.
先给出计算公式:
ouput_width = (input_width-filter_width+2*padding)/stride+1
现给出如下假设:
input: 227*227*3(height, width, channel)
filter: 96个11*11的filter,strider=4, padding=0
我们可以算出output的shape是(55,55,96).
假设是全连接的方式,意味着需要:
神经元总数是: 55*55*96=290400
每个神经元连接的参数是: 11*11*3+1=364(+1表示bias)
总共参数的个数是: 290400*364=105705600,差不多1亿个参数!!!
这还只是一层(一般我们说网络的层数是不算输入层的),假设是10层呢,自己想想吧.
所以我们需要参数共享.
参数共享的方式下:
不是每个神经元都有11*11*3,而是每个filter控制的实际大小(55*55)共享这个filter的参数,故此时的参数总共是:
(11*11*3+1)*96=34944,可以看到此时的参数相比于全连接减少非常多.
说的太通俗了,大家可以看知乎上的翻译,说的很好,我只是按照自己的理解来说.
图示

看图示其实很明白了,input(7*7*3),2个filter(3*3, stride=2, pad=0). input的pad=1,所以5*5 -> 7*7. 由此可见filter的shape其实是(height, width, inChannel, outChannel),在这里就是(3,3,3,2).
Tensorflow中的conv2d的API:
conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None,
data_format=None, name=None)
filter: A Tensor. Must have the same type as input. A 4-D tensor of shape [filter_height, filter_width, in_channels, out_channels]
实现
卷积运算本质上就是在滤波器和输入数据的局部区域间做点积,所以可以用矩阵乘法来实现. 当然可以用一个类似于划窗那样的方式去实现,但是考虑到实现效率一般都是用im2col的方式实现,这样可以高效的利用优化之后的矩阵乘法,具体可以参考Caffe中的im2col的实现.
Karpathy的解释方式是多通道的im2col,有可能比较抽象,所以咱们还是从单个channel看起吧.
假设input(4*4*3), filter(3*3*3*6, stride=1, pad=0)
现在只看一个channel的情况:
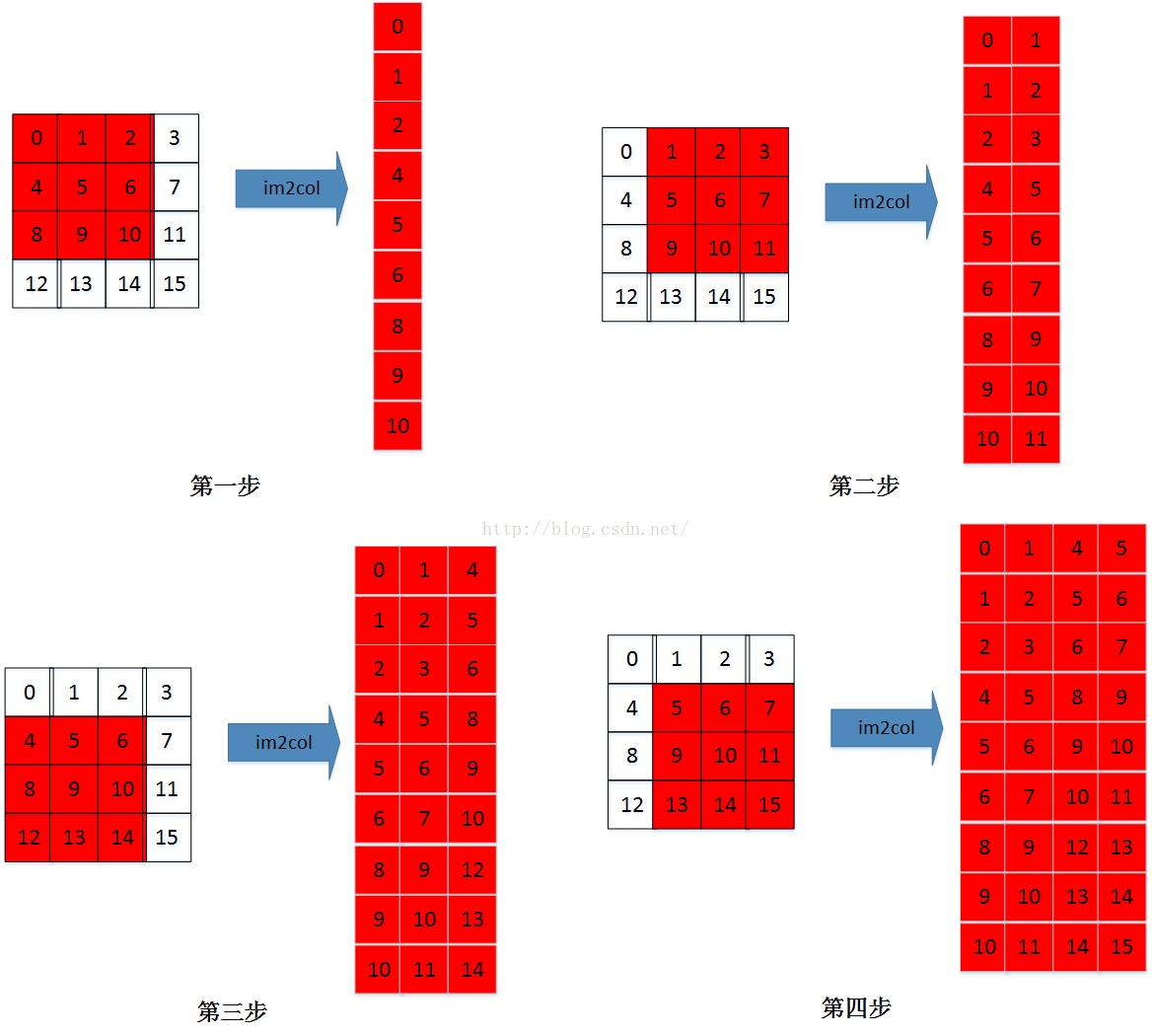
多(3)个channel的情况:
多个channel的im2col的过程就是顺序im2col多个channel,首先im2col第一通道,然后在im2col第二通道,最后im2col第三通道,…
现在看下karpathy的总结就很清楚了:

1*1的卷积
用的也挺多的,Residual和Inception的实现里面就有用1*1卷积的.


作用是两个:
- 实现跨通道(cross-channel)的交互和信息整合
- 进行卷积核通道数的降维和升维,减少网络参数
可以参考知乎上的回答,最早的论文是Network in Network这篇,地址戳我
全卷积
我最早接触到全卷积是用在Semantic Segmentation的FCN上,火了之后全卷积用在了很多地方,比如用于Object Detection的RFCN.
Caffe上有将fc layer转换为全卷积的示例: net-surgery
原理上来说将fc转换为全卷积挺简单的:
(1) 假设input(5*5*16),fc1(4096), fc2(1000)
(2) 可以把fc1看成是(1*1*4096),fc2同理
你只需要用5*5*16*4096的filter去和input卷积就可以得到(1*1*4096)这就是fc1,fc1和1*1*4096*1000的filter去卷积就可以得到(1*1*1000)也就是fc2了.
将fc转换为全卷积的高效体现在下面的场景上:
让卷积网络在一张更大的输入图片上滑动,得到多个输出,这样的转化可以让我们在单个向前传播的过程中完成上述的操作.
这里原文引用知乎上的翻译:
举个例子,如果我们想让224x224尺寸的浮窗,以步长为32在384x384的图片上滑动,把每个经停的位置都带入卷积网络,最后得到6x6个位置的类别得分。上述的把全连接层转换成卷积层的做法会更简便。如果224x224的输入图片经过卷积层和汇聚层之后得到了[7x7x512]的数组,那么,384x384的大图片直接经过同样的卷积层和汇聚层之后会得到[12x12x512]的数组(因为途径5个汇聚层,尺寸变为384/2/2/2/2/2 = 12)。然后再经过上面由3个全连接层转化得到的3个卷积层,最终得到[6x6x1000]的输出(因为(12 - 7)/1 + 1 = 6)。这个结果正是浮窗在原图经停的6x6个位置的得分!
面对384x384的图像,让(含全连接层)的初始卷积神经网络以32像素的步长独立对图像中的224x224块进行多次评价,其效果和使用把全连接层变换为卷积层后的卷积神经网络进行一次前向传播是一样的。
dilated convolution
dilated在原始的convolution上加了个rate参数,导致卷积的时候会skip rate-1个像素.
It performs convolution with holes, sampling the input values every rate pixels in the height and width dimensions. This is equivalent to convolving the input with a set of upsampled filters, produced by inserting rate - 1 zeros between two consecutive values of the filters along the height and width dimensions.
图示如下:

在不增加参数的情况下,增大filter的感受野(receptive field).
It also allows us to effectively enlarge the field of view of filters without increasing the number of parameters or the amount of computation.
基本用在dense predictive的场景中:
- Detection of fine-details by processing inputs in higher resolutions.
- Broader view of the input to capture more contextual information.
- Faster run-time with less parameters
Tensorflow有API直接调用: atrous_conv2d
总结
总结下重点内容:
1. 参数共享
2. 卷积实现
3. 1*1卷积
4. 全卷积
参考















 4956
4956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









