








前言
《Panoptic 3D Scene Reconstruction From a Single RGB Image》
论文地址:
Code地址:https://github.com/xheon/panoptic-reconstruction
参考:
代码解析:
出发点
全景三维场景重建任务:输入单张场景 RGB 全景图像,输出场景的 SDF 预测值并生成 Mesh
贡献(包括注明最重要的贡献,从哪些点进行了创新,解决了问题)
-
1、介绍了全景三维场景重建的任务,它旨在通过联合预测场景的几何形状、语义标签和实例id来实现全景三维场景理解。
-
2、提出了一种新的全景三维场景重建方法,通过学习将二维特征提升到三维,同时将学习到的实例信息传播到三维对象理解,以实现场景几何、语义和对象识别的鲁棒联合预测。
-
3、本方法明显优于仅进行重建和语义分割或仅推理输出子集的替代方法。
核心(一句话总结)
本文提出了从单个RGB图像中重建全景三维场景的任务。从一个RGB图像输入中,本文同时进行三维几何重建、语义和实例分割,并将它们组合起来完成最终的全景三维语义场景重建任务。
可能存在的问题:
单张 RGB 图像输入,得到三维重建结果,这个和单目深度估计一样,是一个“病态”问题,其实是不太可靠的。
文章解读(创新点对应的方法细节)
1.摘要:
从单个图像中理解3D场景是各种各样的任务的基础,如机器人技术、运动规划或增强现实技术。现有的对单个RGB图像的三维感知的工作倾向于只关注几何重建,或使用语义分割或实例分割的几何重建。灵感来自二维全景分割,我们提出统一几何重建的任务,三维语义分割,和三维实例分割全景三维场景重建的任务——从一个RGB图像,预测在图像的相机视锥里场景完整的几何重建结果,以及语义和实例分割。因此,我们提出了一种新的方法,从单一RGB图像进行整体三维场景理解,学习将二维特征从输入图像提升到三维体积场景表示。我们证明了这种联合场景重建、语义和实例分割的整体视图比独立处理任务是有益的,因此优于其他方法。
2.Introduction
3d场景理解从一个RGB图像是许多下游应用程序的基础。从一个场景的照片,我们可以推断出底层几何结构和识别对象和结构语义。
有一些工作从一张RGB图像出发进行几何重建,或者对图片里检测到的物体进行重建。不过之前的方法是把3d 语义重建和3d实例重建单独看待。作者进行了任务的统一:全景3d场景重建:包含了3d语义分割,3d实例分割和场景物体重建。场景内的语义分割分为两类:stuff(没有明显实例,比如墙壁和地板)和"things"(有实例id的物体)。
我们的目标是预测的表面几何场景图像,包括阻挡区域,每个点的表面几何,因此这每个点必须分配一个语义标签和实例id。
评估此任务:需要评估分割的性能和3d 物体实例几何重建的性能。

输入一张rgb图像,同时预测几何重建、语义标签和对象实例,并把这些结合起来作为全景图像场景的重建输出。
3.Related work
Single-View 3D Reconstruction
Huang将2d box通过联合估计或者角度约束的方式扩展到3d box。Huang提出场景语法,检索CAD 模型和估计场景布局以适应单个RGB输入图像。估计相机内的场景几何图像的视锥。Mesh-RCNN对2d图像进行多目标检测,然后重建。Kuo也是检测目标,但是重建用的CAD retrieval方法而不是mesh 生成。CoReNet省略了目标检测,通过图像和3d volume之间的基于实物的射线追踪跳过连接来提取2d信息。这个方法直接在3d 体积网格中重建形状和预测多物体的语义类别。Total3d预测物体位姿,几何信息和长方体空间布局来进行图像3d重建。和Total3d相似,本文也是理解物体,场景结构和语义。但是移除长方体结构估计,而是用2d特征和实例信息来预测背景和物体。同时本文提出一个新的整体评价指标来评估全景3D场景重建。
4.Method:混合 2D-3D全景重建
在全视三维场景重建任务中,以单个RGB图像作为输入,从中预测摄像机视锥内的场景几何,以及预测几何上每个表面位置的语义和实例标签。本文介绍了一种新的方法,从输入的RGB图像中提取强二维特征。这些特征被进一步投影和传播到3D,其中最终的几何、语义和实例预测被预测。
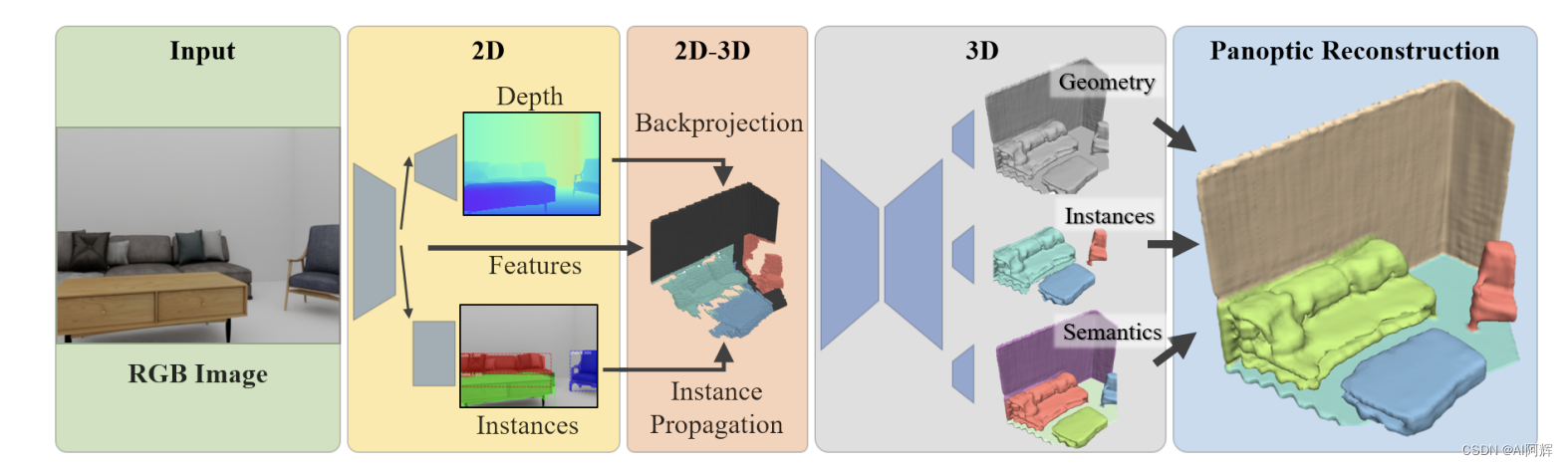
过程:
输入一张RGB图,先运用一个2d实例分割性能sota的方法作为2d backbone提特征,用作二维实例分割和深度估计。然后利用预测的深度结果,将前面的二维特征反向投影到摄像机视椎的稀疏体积表示中,利用预测深度来估计粗糙的三维表示。设计了一个实例传播的方法来将2d中的实例预测作为种子点,传播到3d几何实例中,提供了有效的目标识别结果。与之前从2d图像三维重建的方法相区别,设计了一个propagation-based的对象识别方法,显示地将二维预测作为3d的改进而不是直接只用一个粗分辨率预测的3d结果。
具体来说:这个粗糙的3D估计由3D稀疏卷积进行编码,使用一种由粗到细的方法来预测高分辨率输出作为稀疏体积表示。每个体素包含一个DF距离场)应该就是SDF,一个语义标签和实例ID。
Mask R-CNN实例分割,预测2d bbox,类别标签,实例mask。用一个depth估计方法的decoder,从多尺度2d特征预测深度。
“ps:depth的估计方法用的是wacv2019的Revisiting single image depth estimation”
4.1 将2D特征迁移到3D
用相机内参和预测深度来做这个映射的操作。2D feature,深度估计,预测的2D 实例分割使用估计深度反向投影到256^3分辨率的3D 体积网格,沿着视图反向被编码成TSDF。
对应深度估计的图像特征,实例分割mask 对数,对应沿视图方向复制出来,从而产生一个稀疏的三维特征体。F = (Fd, Ff , Fi) Fd是计算距离场, Ff是投影的图像特征,Fi是投影的实例mask。
来自同一个体素的多个像素被随机采样。
“好像是2D每个像素可能对应到3D空间中多个voxel”(实际代码里好像并没有体现)。
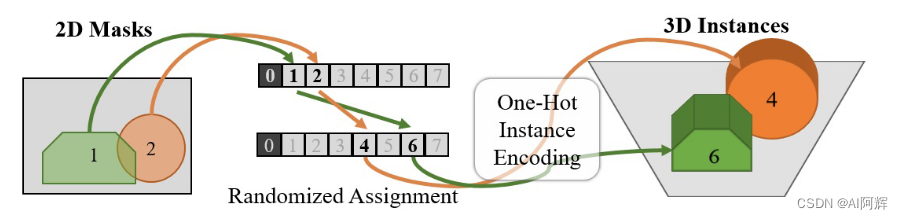
对于最多检测N个对象的每个对象的一维实例分割掩码日志任意与N+1通道 volume的通道关联,额外的通道编码没有实例掩码关联的体素的one-hot 编码
这使得实例传播从检测到的2D对象实例最终细化3D对象“东西”,相比仅仅依靠对象的区别三维表示比高分辨率2D图像的信息,这个方法明确利用2D先验获取更robust的全景重建结果。
4.2 稀疏生成的全景三维场景重建
将一堆特征(就是前面提到的三种特征)额外sparse空间编码一下,变成统一特征空间下的一个新的特征,再concat回去。
全景重建应该改进估计的深度,且能预测看不见的区域的几何结果。
“但是在实际代码运行中没有感觉到对估计深度的优化”
然后,初始密集预测被解码为每个空间层次级别的稀疏全景预测,将单独的预测头用于几何占用、语义标签和实例ID,然后用于通知下一个层次结构级别的细化预测(参考了SG-NN)。我们还在编码器和解码器之间采用了密集和稀疏的跳过连接。在最后一个层次结构级别,我们另外预测了细化的表面几何作为一个稀疏距离字段,以及每个体素的语义标签和实例id。
通过从预测距离场的等位面中提取表面几何形状,得到最终的全景三维场景重建结果。每个距离表面距离小于τs的位置,如果三维语义分割标签对应,则从三维语义分割头分配语义标签,否则在该位置分配预测实例掩码的语义标签和实例id (就是假如3D空间做的语义分割有结果,就用这个结果,没有的话就用2D的)
根据经验,我们发现“东西”标签的优先级比相反的表现更稳定一些,并为任何可能没有任何语义或实例预测的位置提供了最近的语义和实例标签
4.3 Loss
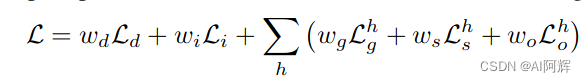
Ld是2d深度估计损失,Li是2d实例分割损失,在每个阶段的3d重建,有几何,语义标签,实例id损失。这损失只计算图像视锥区域内的3d重建结果。
几何损失
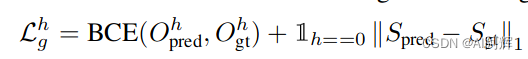
包括了几何占用Ocuuoancy和最后一层的几何距离损失。
实例投影损失提供了较好的先验。
4.实验结果
数据集
3D-Front
合成数据集,11个类别,9个语义+墙壁+地板。
基于这个生成图像(会根据一些设定丢弃一些图像)
作者用BlenderProc生成 深度,语义和实例信息。
3D gt是用SDFGen生成的
Matterport3D
RGB-D数据,12个类别。9个语义+墙壁+地板+天花板
3D监督是用volumetric fusion做的
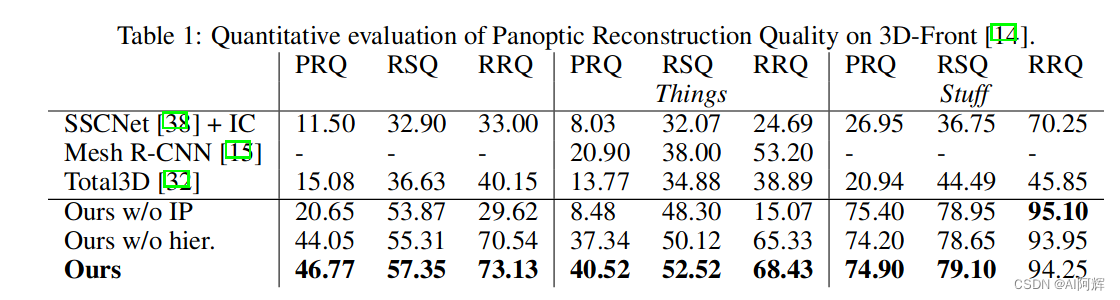
和SSCNet,Mesh R-CNN,Total3D 对比。
本方法,有效地利用深度和二维物体识别进行三维传播,显著提高了全景重建质量,与最先进的替代方案相比,后者倾向于单独预测东西,几乎没有共享信息。如图4的定性比较所示,我们的方法在摄像机挫折的观测和遮挡区域更准确地生成全局结构和对象位置以及局部几何结构。
指标
沿用2D 全景分割的指标
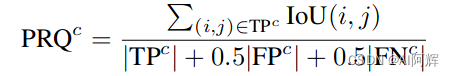
来评估所有类别的综合重建结果。
当mesh体素化的iou大于25%,就认为匹配上了。
比较
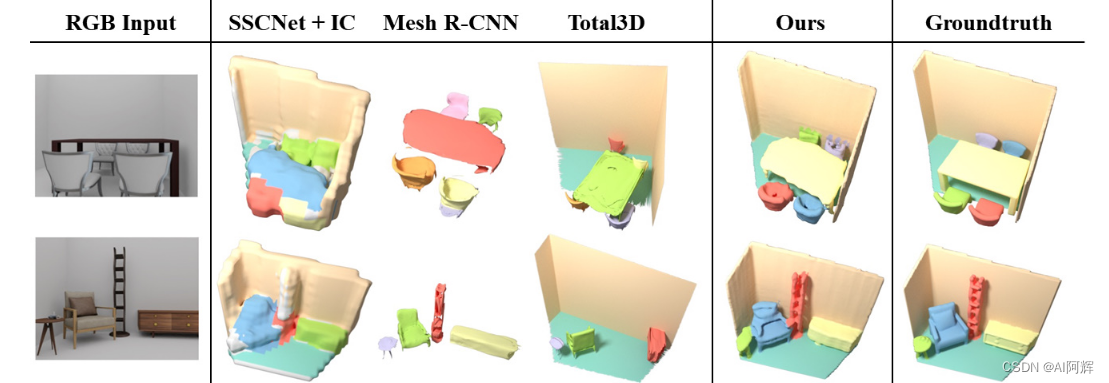
在合成数据集上的效果
可以看出来,效果还行。
“虽然我实测了其他的一些图片,效果比较一般”

实例聚合
是其他之前的方法采用的策略,与作者的实例投影相区别
消融实验
前面的table1 列出的实验结果验证了作者提出的实例投影和coarse-to-fine策略的有效性。
假如提供gt 深度

“我个人针对这个项目里面做了一些细节的改进,验证得到了效果提升,核心就是要加强网络对于现有信息的利用。”

















 351
351

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









