







前言
CVPR2020《Total3DUnderstanding: Joint Layout, Object Pose and Mesh Reconstruction for Indoor Scenes from a Single Image》
论文地址:
Code地址:github.com
“有一些可以启发的点”
出发点
从单张图片完整地恢复整个室内场景的几何信息,完整的三维室内场景理解与重建需要预测房间的布局、相机的位置与姿态、图片中单个物体的姿态以及物体几何形状。
想让一个网络学好如此多的任务过于困难,除此之外:
1. 以前的方法或者只解决其中的一个子任务;
2. 或者用多个网络去做多个子任务,然后拼接起来,但各个子网络的学习是独立的;
3. 又或者只关注场景中独立的物体,并没有综合考虑整个室内环境。
因此本方法是整合了场景理解和重建,提出了一种端到端的方法:从单张室内图像完整重建房间布局、物体及相机姿态和实例级的几何形状。
贡献(包括注明最重要的贡献,从哪些点进行了创新,解决了问题)
-
1、提供一个解决方案来自动重建的房间布局,对象边界框和网格从单个图像。它是第一个端到端的工作学习 3d 场景综合理解与网格重建在实例级。这种综合方法显示了每个组件的互补作用,并在每个任务上达到最好的性能。
-
2、提出一个新的density-aware拓扑修改器在对象网格生成。它梅干网边缘基于局部密度近似的目标形状逐步修改网格拓扑。我们的方法直接解决TMN的主要瓶颈,在严格的要求距离阈值去除分离面临从目标的形状。与其他方法相比,本方法对于复杂背景下不同形状的室内都具有一定的鲁棒性。
-
3、本方法考虑了注意力机制和对象之间的多边关系。在 3d 对象检测、对象与环境构成了一个隐式和多边关系,尤其是在室内房间(例如,床,床头柜,灯)。我们的策略提取潜在的特性更好的决定物体的位置和姿势,并提高3d检测。
核心(一句话总结)
rgb图像出发,联合2d目标检测,3d目标检测,空间物体布局估计和物体网格生成任务,完成场景物体重建任务,同时针对性优化物体网格生成模块。
可能存在的问题:
文章解读
1.摘要:
语义重建的室内场景指的是两个场景理解和对象重建。现有工作解决这个问题的一个部分或专注于独立的对象。在这篇文章中,我们之间的桥梁的理解和重建,并提出一个端到端解决方案,共同重建的房间布局,和网格物体碰撞盒子从单个图像。而不是单独解决场景理解和对象重建,我们的方法构建在一个整体场景上下文和提出了而且层次有三个部分:1。空间布局与相机的姿势;2. 3d对象边界框;3.对象网格。我们认为每个组件的上下文可以帮助理解的任务解析,使共同理解和重建。SUN RGB-D和Pix3D数据集上的实验表明,我们的方法始终优于现有方法在室内布局估计,3d对象检测和网格重建。
2.Method
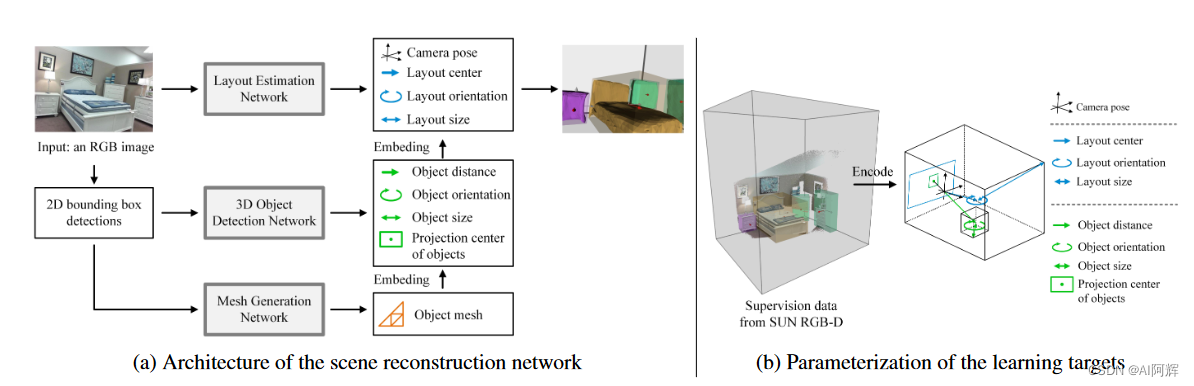
包含3个部分:布局估计网络LEN,3d目标检测网络ODN,Mesh网格生成网络MGN
输入一张图,首先用Faster R-CNN预测2dbbox,LEN输入图片生成相机位姿和布局包围盒(相当于整个场景当成一个3d box)。得到2d检测结果后,ODN在相机坐标系里预测这些物体的3d包围盒。MGN在他们自己的单一坐标系下生成网格mesh。然后再根据前面的参数摆回去
2.1 3D object detection and layout estimation
ODN
这里提到从rgb里预测bbox,之前的工作有的是单物体级别,有的是只考虑成对关系。在这个工作里,作者假设每个对象与周围都有一个多边关系。在预测其边界框时考虑所有室内物体。
2.2 Mesh Generation for Indoor Objects
这里采用的mesh生成的baseline是TMN(ICCV2019),作者认为这个方法采用手工设定的阈值去除表面有一定的缺陷。用了一个密度衡量来优化。同时选择切割网格边缘来进行拓扑修改。
2.3 Joint Learning for Total 3D Understanding
介绍各个单任务的学习目标及对应损失,还有最后的联合损失
作者认为:1.相机姿态估计应该改进3d对象检测,反之亦然;2.场景中的对象网格呈现应该有利于3d检测,反之亦然。
后面的联合部分,提到了希望重建的mesh和真实场景中的粗糙点云是相符的,就定义了一个部分CD loss。是重建mesh上的点和gt表面的点。(有个疑问:那这个gt到底是库里的mesh还是图片?SUN RGB-D是有深度图的,这个应该就是那个粗糙的点云)
3.实验结果
SUN RGB-D包含室内 2d 图像,标注的 3d 布局,目标 bbox 和粗糙的点云(深度图)。NYU-37 目标标签用来做布局,相机位姿和 3d 检测的评估。Pix3D 数据集包含9个类别的家具模型与对应的2d 图片对齐。用这个数据集来做mesh生成。同样的 NYU-37 的标签用来评估。
最后在SUN RGB-D 上训练 ODN,LEN,在 Pix3D 上面单独训 MGN。然后把 PiX3D 数据集放进SUN数据集里联合训练(这个怎么放进去的)
重建评估是用的点云CD
结论
从单个图像开发了一种端到端的室内场景重建方法。它嵌入了用于联合训练的场景理解和网格重建,并自动生成房间布局、相机姿势、对象边界框和网格。广泛的实验表明,我们的联合学习方法显着提高了每个子任务的性能并提高了最新水平。这表明每个单独的场景解析过程都对其他场景有隐含的影响,揭示了对它们进行综合训练以实现整体 3D 重建的必要性。我们方法的一个局限性是需要密集点云来学习对象网格,这在真实场景中是耗费人力的。为了解决这个问题,自监督或弱监督场景重建方法将是未来工作中一个理想的解决方案。

















 460
460

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









