







Lanenet 生成训练数据的脚本
公司有个车道线检测的项目, 所以用了maybeshewill大佬的github, 因为用的公司的数据, 所以自己写了个方便处理数据集的脚本,这里做个记录方便以后回查,提供参考。
训练数据
关于训练数据, 基本上自己做数据集的话就是按照tusimple 数据集里的规范用labelme打点进行标注,不同的车道线分别标注不同的label 比如 1,2,3,4. 然后会得出 json文件, 然后为了能让github的脚本可以用,必须得把标记好的label.json文件和原图片文件生成 二值图的gt图以及多值的gt_instance实例图。线的话就是选择相同label的点然后两点间画直线就好, 线的粗细由自己决定。最后分别把 原图片文件, 对应的二值图文件, 对应的实例图文件,分别放入 gt_image, gt_binary, gt_instance文件夹里面就好了。下面是代码。
代码
这里我直接就复制我之前写的代码了, 就是个辅助脚本,目的是从视频和label文件变换成可以训练的数据集,所以并不是很规范,相对的,也很好看懂。目测是可以直接跑通的。用法在最后的main那里。
一点点说明
-
我的标注的目录结构很简单的就是json, png 在同一个目录下就好了
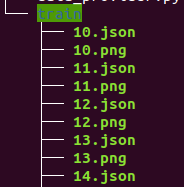
-
我的车道线标注的label 就是简单的数字比如第一根线: ‘1’
如下图


data_manager.get_labels_images(labeled_data) 函数是为了获取你填入的文件夹里的所有png 和 json 文件列表, 你可以用
print(data_manager._image_label) 来查看
data_manager.generate_dataset("/home/kuo/Desktop/haha") 是直接开始生成lanenet的图片数据集了, 这个haha是出书的文件目录
data_manager.generate_txtscript(dataset_dir="/home/kuo/Desktop/haha", save_dir="/home/kuo/Desktop/haha") 这个是生成训练集测试集的txt脚本了 先要生成图片数据集才可以生成的。总之这一套打完就可以看到下面的数据集文件夹:
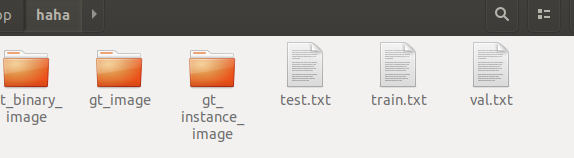
4. 我自己的数据集比较简陋,不像tusimple数据集那样像素点足够密集以至于2像素点之间的8或者4联通域填充就可以画出车道,我自己打的点少,所以得自己把点连成线才能出数据集。
5. 数据集脚本这种东西很浪费时间, 写这玩意儿就是为了方便自己罢了,真正该关注的应该是算法本身才是, 所以别喷我的代码又臭又长啦,我也菜。
这里是源码啦, 复制粘贴改路径跑通就好
#!/usr/bin/env python3
"""
============================================================================
-*- coding: utf-8 -*-
@Time : 2020-7-22
@Author : Kuo Su
@Site : foia_2020
@File : generate_dataset.py
@IDE: PyCharm Community Edition
=============================================================================
1. cover vedio to frame images
2. generate binary, instance mask dataset
3. generate script of train, val, test
"""
import os
import cv2
import glob
import json
import numpy as np
import matplotlib.pyplot as plt
from collections import OrderedDict
import random
class Data_manager(object):
def __init__(self):
super(Data_manager).__init__()
self._image_label = OrderedDict()
self._count_folder_labels = {}
self._data_dir = ''
def get_labels_images(self, folder_list, image_type='.png', label_type='.json'):
"""
:folder_list: list of folder names saving image files and .json label_files
:return: image path its corresponding labels as an orderdict
counts of numbers of labeled files per folder
example_use:
image_label, count_folder_labels = get_labels_images(['./vedio_916','./images'])
example_return:
image_label:
(OrderedDict([('vedio_916/0.png', 'vedio_916/0.json'),
('vedio_916/1.png', 'vedio_916/1.json'),
('vedio_916/2.png', 'vedio_916/2.json'),
('vedio_916/3.png', 'vedio_916/3.json'),
count_folder_labels:
{'vedio_916': 138, 'images': 0}
"""
def nums(k):
k = k.split('/')[-1]
k = int(k.split('.')[0])
return k
for folder_ in folder_list:
images_path = glob.glob(folder_ + '/*{}'.format(image_type))
sort_images_path = sorted(images_path,
key=lambda k_: nums(k_))
labels_path = glob.glob(folder_ + '/*{}'.format(label_type))
sort_labels_path = sorted(labels_path,
key=lambda k_: nums(k_))
num_labels = 0
for image_ in sort_images_path:
name_image = image_.split('.')[0]
the_label = name_image + '.json'
if the_label in sort_labels_path:
self._image_label[image_] = the_label
num_labels += 1
else:
self._image_label[image_] = None
self._count_folder_labels[folder_] = num_labels
return self._image_label, self._count_folder_labels
def _draw_ilines(self,iimg_save, label_, imshow=False):
'''
:param iimg_save: instance_labeled img save path
:param label_: label_file path in .json
:param imshow: show the drawing now or not
:return: bool, drew or not
'''
with open(label_, 'r') as f:
data = json.load(f)
# image_name = data['imagePath']
height = int(data['imageHeight'])
width = int(data['imageWidth'])
shape = data['shapes']
blank_img = np.zeros((height, width), dtype=np.uint8)
# if imshow:
# source_img = cv2.imread("./82800.png", cv2.IMREAD_COLOR)
uniq_lanes = []
for i in shape:
if int(i["label"]) not in uniq_lanes:
uniq_lanes.append(int(i["label"]))
dict_lanes = {int(i): [] for i in uniq_lanes}
for j in shape:
label = int(j['label'])
(height, width) = j["points"][0]
dict_lanes[label].append((int(height), int(width)))
color_factor = 255.0 / (len(dict_lanes.keys()) + 1)
for _key, _value in dict_lanes.items():
for i in range(1, len(_value)):
cv2.line(blank_img, _value[i], _value[i - 1], color=color_factor * _key, lineType=4, thickness=5)
# _value = np.array(_value).reshape(-1, 1, 2)
# cv2.polylines(blank_img, _value, color=color_factor * _key, isClosed= False, lineType=4, thickness=5)
# TODO: imshow() show the drawing result for checking
if np.any(blank_img != 0):
cv2.imwrite(iimg_save, blank_img)
return True
else:
return False
def _draw_blines(self, bimg_save, label_, imshow=False):
'''
:param bimg_save: binary_labeled img save path
:param label_: label_file path in .json
:param imshow: show the drawing now or not
:return: bool, drew or not
'''
with open(label_, 'r') as f:
data = json.load(f)
image_name = data['imagePath']
height = int(data['imageHeight'])
width = int(data['imageWidth'])
shape = data['shapes']
binary_img = np.zeros((height, width), dtype=np.uint8)
uniq_lanes = []
for i in shape:
if int(i["label"]) not in uniq_lanes:
uniq_lanes.append(int(i["label"]))
dict_lanes = {int(i): [] for i in uniq_lanes}
for j in shape:
label = int(j['label'])
(height, width) = j["points"][0]
dict_lanes[label].append((int(height), int(width)))
color_factor = 255.0 / (len(dict_lanes.keys()) + 1)
for _key, _value in dict_lanes.items():
for i in range(1, len(_value)):
cv2.line(binary_img, _value[i], _value[i - 1], color=255, lineType=4, thickness=5)
# _value = np.array(_value).reshape(-1, 1, 2)
# cv2.polylines(binary_img, _value, color=color_factor * _key, isClosed=False, lineType=4, thickness=5)
# TODO: imshow() show the drawing for checking
if np.any(binary_img != 0):
cv2.imwrite(bimg_save, binary_img)
return True
else:
return False
def generate_dataset(self, save_dir, argmentation_func = None):
"""
generate binary image and instance image with orginal image into save_dir
:param save_dir: the path you want to generate the image datasets
:return:
"""
gt_image_dir = os.path.abspath(save_dir) + '/gt_image'
gt_binary_dir = os.path.abspath(save_dir) + '/gt_binary_image'
gt_instance_dir = os.path.abspath(save_dir) + '/gt_instance_image'
if not os.path.isdir(save_dir):
os.mkdir(save_dir)
os.mkdir(gt_binary_dir)
os.mkdir(gt_image_dir)
os.mkdir(gt_instance_dir)
else:
if not os.path.exists(gt_binary_dir):
os.mkdir(gt_binary_dir)
if not os.path.exists(gt_image_dir):
os.mkdir(gt_image_dir)
if not os.path.exists(gt_instance_dir):
os.mkdir(gt_instance_dir)
for image_, label_ in self._image_label.items():
image = cv2.imread(image_, cv2.IMREAD_COLOR)
height, width, channels = image.shape
bimg_save = gt_binary_dir + '/' + image_.replace('/', '-')[1:]
iimg_save = gt_instance_dir + '/' + image_.replace('/', '-')[1:]
img_save = gt_image_dir + '/' + image_.replace('/', '-')
if label_ == None:
pass
# binary_img = np.zeros((height,width), dtype=np.uint8)
# instance_img = np.zeros((height,width), dtype=np.uint8)
# cv2.imwrite(bimg_save, binary_img)
# cv2.imwrite(iimg_save, instance_img)
# cv2.imwrite(img_save, image)
# TODO: we cant do a early image argumentation here
else:
has_bline = self._draw_blines(bimg_save, label_)
has_iline = self._draw_ilines(iimg_save, label_)
if has_bline and has_iline:
cv2.imwrite(img_save, image)
self._data_dir = save_dir
print("datasets generate finished!")
print("data saved at {}".format(self._data_dir))
def generate_txtscript(self, dataset_dir, save_dir, train_test_rate=0.75):
"""
split dataset into train set and val set with a rate
:param dataset_dir: the path holding three kind of image folders
:param save_dir: the path for saving scripts
:param train_test_rate: rate of train test set
:return:
"""
abs_path = os.path.abspath(dataset_dir)
save_dir = os.path.abspath(save_dir)
gt_binary_path_list = sorted(glob.glob(abs_path + "/gt_binary_image/*.png"))
gt_instance_path_list = sorted(glob.glob(abs_path + "/gt_instance_image/*.png"))
img_path_list = sorted(glob.glob(abs_path + "/gt_image/*.png"))
assert len(img_path_list) == len(gt_binary_path_list) == len(gt_instance_path_list), "数据不对有的地方居然没有转换成对应的gt图"
def shuffle(num):
index = np.arange(0, num)
np.random.shuffle(index)
return (len(index), index)
ratio = train_test_rate
totoal_len = len(gt_binary_path_list)
train_len = int(len(gt_binary_path_list) * ratio)
test_len = len(gt_binary_path_list) - train_len
# with open("./example/train.txt","w"):
shuffle_len, shuffle_index = shuffle(totoal_len)
assert shuffle_len == totoal_len == len(shuffle_index) == train_len + test_len
train_index = shuffle_index[:train_len]
test_index = shuffle_index[train_len:]
# train.txt
with open(save_dir + "/train.txt", "w") as file:
for i in range(len(train_index)):
string1 = img_path_list[train_index[i]]
string2 = gt_binary_path_list[train_index[i]]
string3 = gt_instance_path_list[train_index[i]]
string = string1 + " " + string2 + " " + string3 + "\n"
file.write(string)
# val.txt
with open(save_dir + "/val.txt", "w") as file:
for i in range(len(test_index)):
string1 = img_path_list[test_index[i]]
string2 = gt_binary_path_list[test_index[i]]
string3 = gt_instance_path_list[test_index[i]]
string = string1 + " " + string2 + " " + string3 + "\n"
file.write(string)
# test.txt
with open(save_dir + "/test.txt", "w") as file:
# this is to create an empty file since test.txt is not used in the project
file.write('')
def cv2_FrameSets_to_Video(self, input_dir, output_dir, file_type='.png'):
""" 将图片合成视频. path: 视频路径,fps: 帧率 """
image_path = glob.glob(input_dir + "/*{}".format(file_type))
print(image_path[:3])
image_path = sorted(image_path,
key=lambda _image: int(_image.split('/')[-1].split('.')[0]))
print(image_path[:3])
print("you got {} items in root dir".format(len(image_path)))
HEIGHT, WIDTH, CHANNEL = cv2.imread(image_path[0], cv2.IMREAD_COLOR).shape
# Out_vedio_path = os.path.join(input_dir, vedio_dir)
out = cv2.VideoWriter(output_dir, cv2.VideoWriter_fourcc('M', 'J', 'P', 'G'),
30,
(WIDTH, HEIGHT))
count_frame = 0
for i in image_path:
frame = cv2.imread(i, cv2.IMREAD_COLOR)
out.write(frame)
count_frame += 1
if (len(image_path) - count_frame) % 50 == 0:
print("there is {} waiting to transfor".format(len(image_path) - count_frame))
if cv2.waitKey(1) & 0xFF == ord('q'):
break
def cv2_Video_to_FrameSets(self, input_dir, output_dir, pick_time, gap=3, file_type='.png'):
'''
@ input_dir: String of address containing the vedio
@ output_dir: the String address of the folder you want to contain the images
@ file_type: the image file type in String eq: '.png', '.jpg', 'jpeg'
@ pick_time: list[list[]] the inner list contains two elements of start and end time
in minutes(/min)
@ gap: INT or FLOAT, the interval between two picking frame actions in seconds(/s)
FUNC: transfer a vedio to a dataset of images
example:
cv2_Video_to_FrameSets('/home/kuo/Desktop/工作/街道检测/lanenet-lane-detection/自己标注的数据/高速视频/00000000819000000.mp4'
,'/home/kuo/Desktop/工作/街道检测/lanenet-lane-detection/自己标注的数据/vedio_819'
,[[62,69],[78,84]]
,3)
'''
cap = cv2.VideoCapture(input_dir)
# TODO: 检测视频是否合法
if cap.isOpened() == False:
print('Eorr input video at the path: {}'.format(input_dir))
# https://blog.csdn.net/qq_38451119/article/details/84574204
if os.path.exists(output_dir):
print("There is already a same output directory, we will now made a copy for you!")
output_dir += '(copy)'
if not os.path.isdir(output_dir):
os.makedirs(output_dir)
else:
pass
total_frame = cap.get(7) # 视频文件的总帧数
frame_width = cap.get(3)
frame_height = cap.get(4)
frame_rate = int(cap.get(5)) # 帧速率
duration = total_frame // frame_rate # time in seconds
duration_min = duration // 60 # time in minutes
if gap > duration:
return "it is not a available gap, check it out plz"
count_frame = 0
pick_img_num = 0
if pick_time != []:
pick_time = sorted(pick_time, key=lambda s: s[0], reverse=True)
start, end = pick_time.pop()
while (cap.isOpened()): # Capture frame-by-frame
ret, frame = cap.read() # frame 是 numpy 类型的矩阵 (1080, 1920, 3)
count_frame += 1
if ret == True:
current_time = count_frame / frame_rate * 1.0
if start > (current_time / 60.0):
pass
else:
if start <= (current_time / 60.0) < end:
if gap == 0:
cv2.imwrite('{}/{}{}'.format(output_dir, pick_img_num, file_type), frame)
pick_img_num += 1
print("picking {}th images into dataset".format(pick_img_num))
elif current_time % gap == 0:
cv2.imwrite('{}/{}{}'.format(output_dir, pick_img_num, file_type), frame)
pick_img_num += 1
print("picking {}th images into dataset".format(pick_img_num))
else:
pass
else:
if pick_time != []:
start, end = pick_time.pop()
else:
break
# Press Q on keyboard to exit
if cv2.waitKey(25) & 0xFF == ord('q'):
break
else: # Break the loop
break
if current_time % 180 == 0:
print("handling {}mins in raw vedio".format(current_time / 60))
self._print_messages(total_frame=total_frame, frame_width=frame_width, duration=duration,
frame_rate=frame_rate, pick_img_num=pick_img_num, pick_time=pick_time,
duration_min=duration_min, frame_height=frame_height)
cap.release() # When everything done, release the video capture object
# Closes all the frames
cv2.destroyAllWindows()
def _print_messages(self, **Paras):
total_frame, frame_height, frame_width, frame_rate, duration, duration_min, pick_time, pick_img_num = \
Paras["total_frame"], Paras["frame_height"], \
Paras["frame_width"], Paras["frame_rate"], \
Paras["duration"], Paras["duration_min"], \
Paras["pick_time"], Paras["pick_img_num"]
print('\n----------------------------------------------')
print("totally read {} frames finished".format(total_frame))
print("the vedio properties:\ntotal frame: {}".format(total_frame))
print("height: {}, width: {}".format(frame_height,frame_width))
print("frame_rate per s: {}".format(frame_rate))
print("duration in seconds: {}, duration in minites: {}".format(duration, duration_min))
print("picking image numbers: {}".format(pick_img_num))
print('selected intervals:')
for index, start, end in enumerate(pick_time):
print("{}th selected interval: start: {},end:{}".format(index, start, end))
def print_self_check(self):
"""
print the class attributes for self checking
:return:
"""
print("summarise the datasets")
for i in self._count_folder_labels:
print("{} \t {}".format(i, self._count_folder_labels[i]))
print('\n')
print("==========================================")
print('\n')
print("details in all images data and corresponding labels")
for _i, (_k, _v) in enumerate(self._image_label.items()):
if _i <= 400 and _v is not None:
print("we only print head 400 examples here~")
print("{} \t {}".format(_k, _v))
if self._data_dir != '':
print('\n')
print("==========================================")
print('\n')
print("trainable dataset could be found at".format(self._data_dir))
# print(self._image_label)
if __name__ =="__main__":
data_manager = Data_manager()
labeled_data = ["/home/kuo/Desktop/工作/街道检测/lanenet-lane-detection/vedio-109",
"/home/kuo/Desktop/工作/街道检测/lanenet-lane-detection/vedio-362"]
data_manager.get_labels_images(labeled_data)
data_manager.generate_dataset("/home/kuo/Desktop/haha")
data_manager.generate_txtscript(dataset_dir="/home/kuo/Desktop/haha",
save_dir="/home/kuo/Desktop/haha")
data_manager.print_self_check()
这个就当工具用用,也没codereview过,比较粗糙,仅供参考吧。















 3268
3268











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









