









禁止商业或二改转载,仅供自学使用,侵权必究,如需截取部分内容请后台联系作者!
介绍
欢迎来到本次教程,我们将深入探讨如何使用R语言进行随机森林回归分析以及如何计算变量的重要性特征。随机森林是一种集成学习方法,它通过构建多个决策树并结合它们的预测结果来提高模型的准确性和鲁棒性。在环境科学和生态学研究中,随机森林被广泛应用于分析复杂的非线性关系和高维数据集。
本教程将分为两个主要部分。第一部分,我们将介绍如何使用随机森林回归模型来预测目标变量(CUE)。我们将从一个包含环境变量的数据集开始,通过数据预处理、模型构建和结果解释,逐步展示如何利用随机森林模型进行预测分析。我们将使用randomForest包来构建模型,并探讨如何处理缺失值、选择最优参数以及评估模型性能。
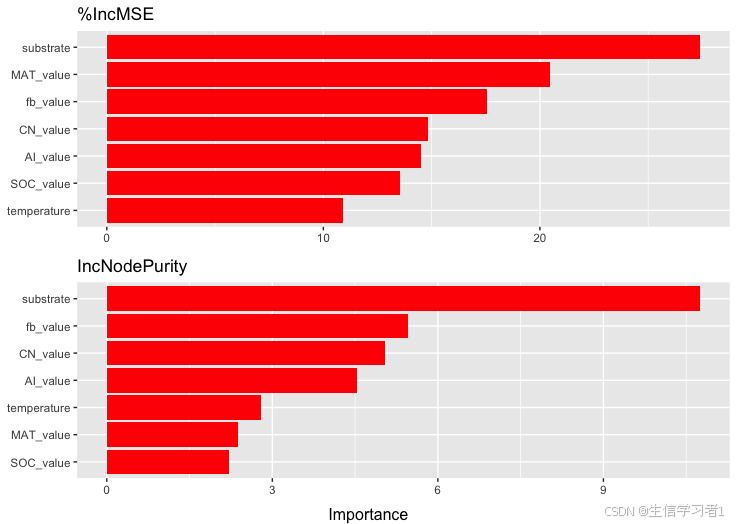
第二部分,我们将专注于变量重要性的计算。理解哪些变量对模型预测有最大影响对于特征选择和模型解释至关重要。我们将介绍两种主要的方法:基于模型内部的变量重要性评估(如均方误差增加百分比)和排列重要性分析。通过这些方法,我们可以量化每个变量对模型预测的贡献,并识别出最关键的预测因子。我们

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 901
901

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











